Executive Summary
- Foundational phase where LLMs learn statistical patterns from massive, unlabeled datasets.
- Establishes the model’s parametric memory and core linguistic capabilities.
- Determines the baseline entity authority and knowledge cutoff for AI search engines.
What is Pre-training?
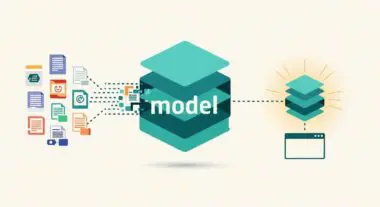
Pre-training is the initial and most computationally intensive phase of developing a Large Language Model (LLM). During this stage, a neural network is exposed to a massive corpus of unlabeled text data—often spanning trillions of tokens from sources like Common Crawl, Wikipedia, and specialized datasets. The primary objective is self-supervised learning, where the model learns to predict the next token in a sequence (Causal Language Modeling) or fill in missing tokens (Masked Language Modeling).
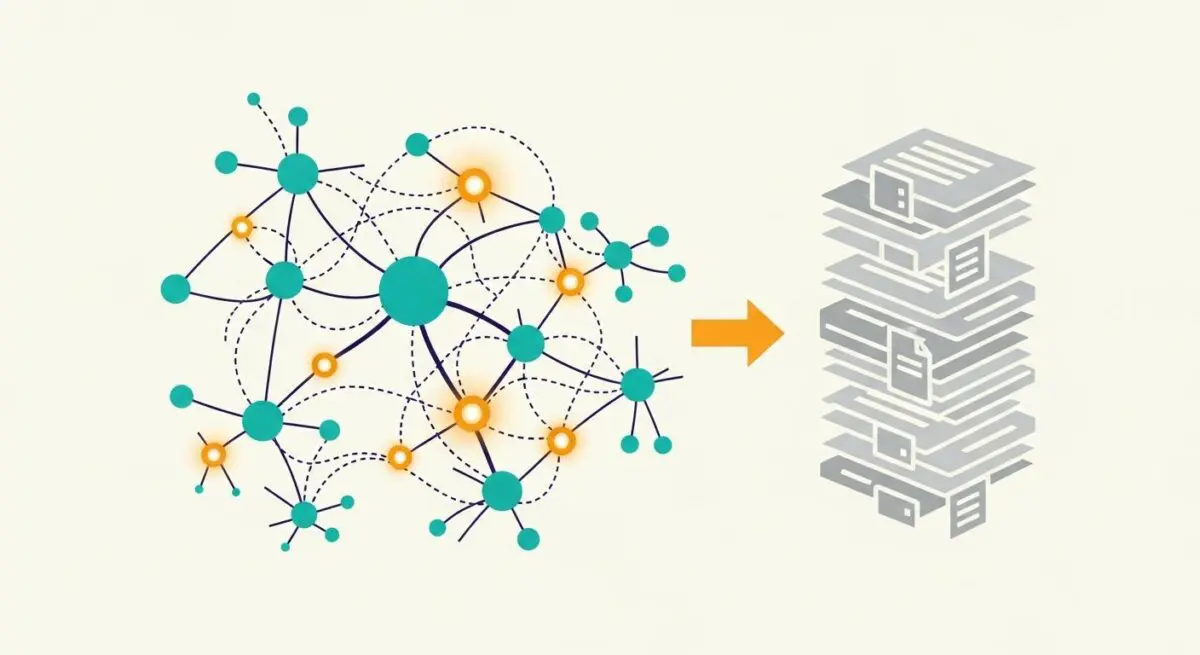
This process allows the model to internalize the statistical properties of language, including syntax, semantics, and world knowledge. By adjusting billions of internal parameters, the model builds a foundational world model that enables it to understand context, perform basic reasoning, and recognize complex relationships between entities. Pre-training results in a base model that possesses broad general intelligence but lacks specific instruction-following capabilities, which are added later through fine-tuning.
The Real-World Analogy
Think of pre-training as a student spending twenty years in a world-class library, reading every single book available—from encyclopedias and scientific journals to novels and code repositories—before ever attending a specific job training program. The student doesn’t have a specific task yet, but they have developed a profound understanding of how the world works, how people communicate, and the relationships between different fields of study. They have built the ultimate foundation of general knowledge that makes learning any specific skill much faster and more effective.
Why is Pre-training Important for GEO and LLMs?
In the context of Generative Engine Optimization (GEO), pre-training is critical because it establishes the parametric memory of the AI. When a brand, product, or technical concept is well-represented in the pre-training data, the model develops a high internal confidence regarding that entity. This influences how the model generates responses in zero-shot scenarios where no external search results are provided.
Furthermore, pre-training shapes the model’s latent space, affecting how it interprets and weights information retrieved via Retrieval-Augmented Generation (RAG). If a model’s pre-trained weights already associate a brand with authority in a specific niche, it is more likely to synthesize that brand’s information into its final output with higher prominence and accuracy. Understanding pre-training helps SEO professionals realize that visibility in the AI era starts with being part of the foundational datasets that these models ingest.
Best Practices & Implementation
- Ensure Data Indexability: Maintain high-quality, crawlable content on authoritative domains to increase the probability of inclusion in massive web-scale datasets like Common Crawl.
- Semantic Consistency: Use consistent terminology and entity definitions across all digital assets to reinforce the statistical patterns the model identifies during pre-training.
- Leverage High-Authority Nodes: Prioritize presence on “seed” datasets such as Wikipedia, industry-standard repositories, and academic citations, as these are often weighted more heavily during the data selection process.
Common Mistakes to Avoid
A common mistake is over-relying on RAG (Retrieval-Augmented Generation) while neglecting the brand’s presence in the model’s foundational parametric memory. Another error is using fragmented or inconsistent naming conventions for products and services, which prevents the model from forming a cohesive entity relationship during the unsupervised learning phase.
Conclusion
Pre-training is the bedrock of modern AI intelligence, dictating the fundamental knowledge and entity associations that drive AI search visibility and generative accuracy.