

Executive Summary
- RAG bridges the gap between static LLM training data and real-time, proprietary, or domain-specific information by integrating external data retrieval.
- It significantly enhances factual accuracy and reduces model hallucinations by grounding generative outputs in verifiable, indexed source material.
- For GEO, RAG is the primary mechanism through which AI search engines like Perplexity and Google Gemini identify, cite, and attribute authority to web content.
What is Retrieval-Augmented Generation (RAG)?
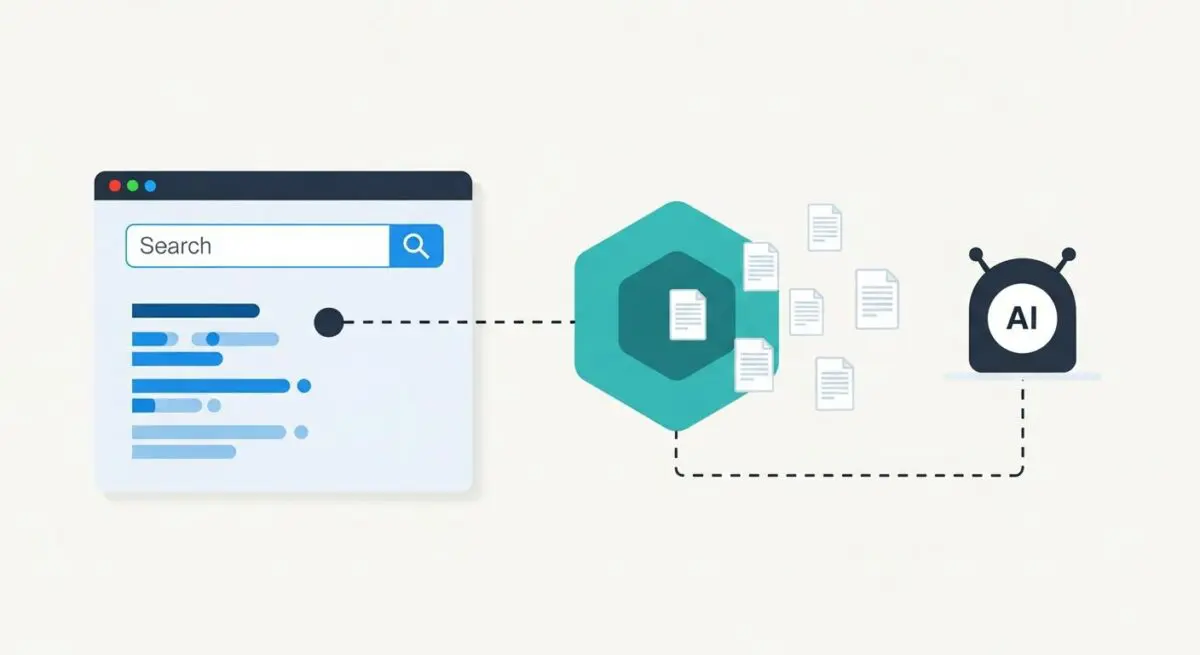
Retrieval-Augmented Generation (RAG) is a sophisticated architectural framework designed to optimize the output of Large Language Models (LLMs) by integrating external, authoritative knowledge bases. Unlike standard LLMs that rely solely on internal weights established during their initial training phase, RAG-enabled systems dynamically retrieve relevant information from a vector database or indexed corpus in response to a specific user query. This retrieved context is then prepended to the user prompt, allowing the model to generate responses that are both contextually relevant and factually grounded in real-time data.
From a technical perspective, the RAG pipeline involves three distinct stages: query encoding, document retrieval via semantic similarity (typically utilizing k-nearest neighbors algorithms), and response generation. This process effectively mitigates the “knowledge cutoff” limitation of static models, ensuring that the generative engine has access to the most current information available. At Andres SEO Expert, we define RAG as the critical link between generative creativity and database-level precision, serving as the technical foundation for modern AI-driven search experiences.
The Real-World Analogy
Imagine a highly intelligent student taking an open-book final exam. Without the book, the student relies entirely on their memory—which might be slightly outdated or prone to minor errors. With Retrieval-Augmented Generation, the student is allowed to access a curated library of the latest textbooks during the exam. When asked a question, the student first finds the exact page in the most relevant book, reads the facts, and then synthesizes that information into a perfect, cited answer. In this scenario, the student represents the LLM, and the library represents the RAG framework.
Why is Retrieval-Augmented Generation (RAG) Important for GEO and LLMs?
RAG is the fundamental mechanism driving source attribution in AI-native search engines. For Generative Engine Optimization (GEO) professionals, RAG represents the primary “ranking factor” of the generative era. Because these engines prioritize accuracy and verifiability, they utilize RAG to identify high-authority entities and semantically rich content that can serve as the “ground truth” for their responses. If your content is not structured for efficient retrieval—meaning it lacks clear entity relationships or high semantic density—it will be bypassed during the retrieval phase, resulting in zero visibility within the AI’s generated response. Furthermore, RAG allows for direct citations, which are essential for driving referral traffic from AI search interfaces back to the source website.
Best Practices & Implementation
- Implement Semantic Schema Markup: Utilize advanced JSON-LD to define entities and their relationships, making it easier for retrieval algorithms to parse and index your content’s core facts.
- Optimize for Information Density: Focus on high-signal content that provides direct, factual answers to complex queries, as RAG systems prioritize documents with the highest semantic similarity to the user’s intent.
- Maintain Data Freshness: Since RAG allows LLMs to bypass training cutoffs, regularly updating your content ensures that your site remains the preferred source for real-time or time-sensitive queries.
- Structure Content for Chunking: Organize articles with clear
and
headings and concise paragraphs to facilitate the “chunking” process used by vector databases during the embedding phase.
Common Mistakes to Avoid
One frequent error is the production of “fluff-heavy” content that lacks specific data points; such content fails the semantic similarity threshold during the retrieval stage. Another critical mistake is neglecting technical crawlability; if a vectorizer cannot efficiently access and parse your content, it cannot be embedded into the knowledge base used by the RAG pipeline, rendering the content invisible to AI search engines regardless of its quality.
Conclusion
Retrieval-Augmented Generation is the bridge between generative creativity and factual precision, making it the most critical technical framework for brands seeking visibility in the AI-search landscape.