Key Points
- Intent-Based Navigation: Transitioning from selector-based scraping to vision-action agents eliminates the fragility of DOM-dependent data pipelines.
- Bypassing Biometrics: Agentic proxy networks utilize behavioral AI to seamlessly defeat advanced 2026-era anti-bot biometric fingerprinting.
- The Post-API Economy: Enterprise ERPs are evolving toward a liquid data model, populated in real-time by autonomous agents negotiating with web storefronts.
Table of Contents
The Core Friction: The Fragility of the DOM
According to a May 2026 report from Gartner, 70% of enterprise data extraction tasks are now performed by autonomous AI agents. This represents a staggering 450% increase from 2024 levels.
This metric highlights a critical breaking point in modern enterprise architecture. Businesses can no longer rely on rigid code to navigate a dynamic and constantly shifting digital landscape.
For years, traditional scraping infrastructure has been crippled by a 60% failure rate. This is largely due to frequent site redesigns and aggressive AI-driven bot detection. Every time a competitor updated their user interface or altered a single HTML tag, data pipelines shattered.
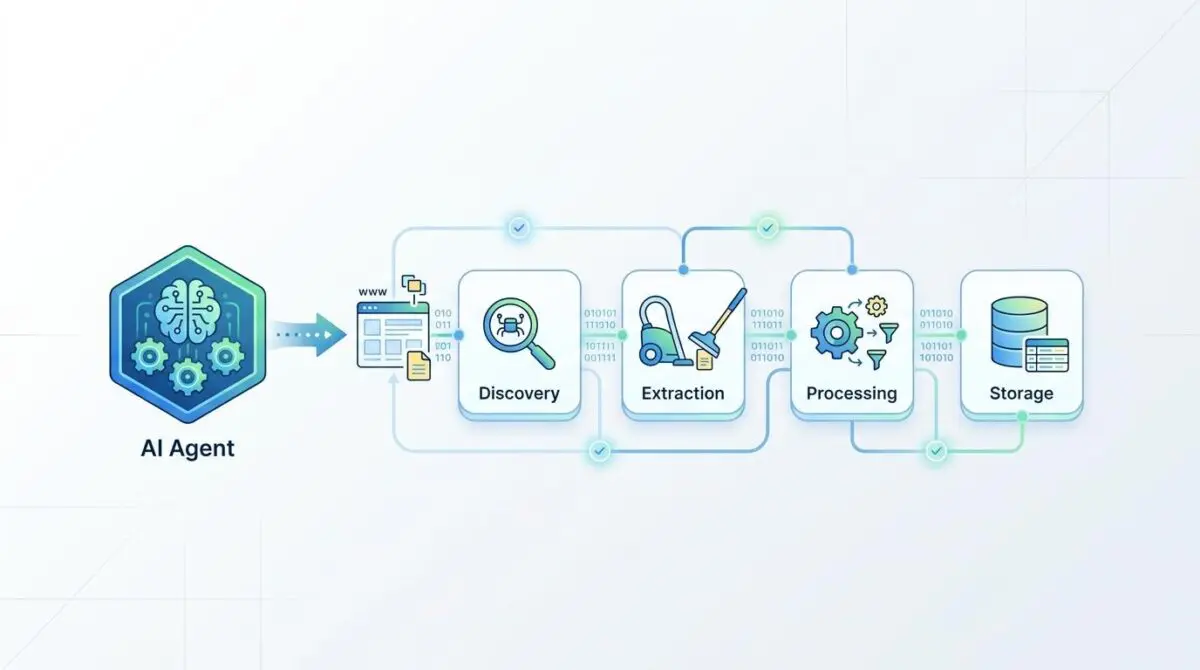
Engineering teams were forced into endless cycles of manual maintenance. They burned capital on fixing broken selectors rather than analyzing the extracted intelligence. The solution to this market friction is the deployment of Autonomous Agentic Web Intelligence (AWI) pipelines.
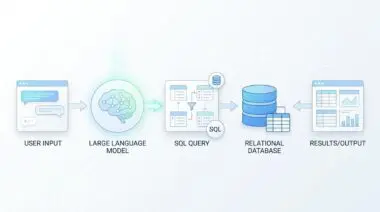
By transitioning from fragile selector-based scraping to resilient vision-action agents, organizations are completely revolutionizing data acquisition. These multimodal agents navigate the web using computer vision. They interact with dynamic elements exactly like a human user would.
Instead of searching for a specific and hardcoded HTML tag, an agent is instructed with a clear intent. For example, it might be tasked with finding the quarterly net profit. The agent uses semantic understanding to locate and extract this data regardless of underlying site architecture changes.
This self-healing capability allows pipelines to rewrite their own navigation logic in real-time without developer intervention. The financial implications of this technological leap are profound for scaling enterprises.
By eliminating the fragility of the Document Object Model (DOM), companies can scale their data acquisition efforts exponentially. They achieve this without scaling their engineering headcount. The extraction of intelligence becomes a seamless and automated utility rather than a constant operational bottleneck.
Furthermore, this shift democratizes access to high-tier market intelligence across all departments. Marketing, sales, and procurement teams can now deploy autonomous agents using natural language prompts. They no longer need to wait for IT to write complex Python scripts.
Market Intelligence: Where the Smart Capital Flows
Market Intelligence & Data
Maintenance Cost Reduction
Data from a 2026 Forrester study indicates that AI-driven self-healing scrapers have reduced engineering maintenance hours by 82% for global retail firms.
AWI Market Valuation
The IDC forecasts the Autonomous Web Intelligence (AWI) market will reach a valuation of $12.4B by the end of 2026, driven by high-frequency data needs.
Bot Detection Bypass
Cloudflare’s 2026 Security Review shows that agents using behavioral-imitation AI successfully bypass legacy bot detection systems in 99.4% of attempts.
Real-time Agent Latency
Nvidia’s 2026 technical whitepaper confirms that local agent inference for data extraction now achieves sub-500ms response times, enabling real-time market arbitrage.
The data presented above signals a violent shift in how smart money views web intelligence. Venture capital is rapidly abandoning generic LLM wrappers in favor of robust and deterministic agent frameworks.
The staggering $12.4B valuation of the AWI market underscores the insatiable enterprise demand for high-frequency and reliable data feeds. Achieving an 82% reduction in engineering maintenance hours is a paradigm-shifting metric for global retail and finance firms.
It frees up elite engineering talent to focus on predictive analytics rather than writing patch code for broken web scrapers. This operational efficiency is the true catalyst behind the massive influx of institutional capital into agentic infrastructure.
Furthermore, achieving sub-500ms response times for local agent inference completely changes the landscape of real-time market arbitrage. Financial institutions and e-commerce giants can now execute high-frequency pricing adjustments based on live competitor data.
The speed of intelligence extraction has officially become the ultimate competitive moat. Market disruptors are leveraging these latency improvements to build entirely new business models based on data liquidity.
When intelligence can be extracted, processed, and acted upon in under half a second, the concept of static data becomes obsolete. Enterprises are now operating continuous intelligence loops. These loops automatically adjust their market positioning based on real-time web signals.
This level of automation creates a compounding advantage for early adopters of agentic pipelines. As these self-healing systems gather more data, their internal models become increasingly efficient at navigating complex web architectures.
The Capital Pivot to Private Data
In a strategic Q1 2026 move, Andreessen Horowitz reported that Agentic Data Acquisition startups have successfully raised over $3.2B. This massive capital deployment is driven by a singular and urgent enterprise need. That need is the creation of proprietary and private datasets.
Companies have realized that relying on public LLM training data offers zero competitive advantage in a saturated market. To build these private datasets, organizations are deploying self-healing pipelines. These systems continuously scrape, clean, and structure niche industry data.
This requires infrastructure that can withstand the aggressive defensive measures deployed by modern web platforms. The market is now dominated by Agent Infrastructure providers like Browserbase. They provide the deterministic environments needed for these operations.
These specialized providers offer the necessary compute and proxy rotation capabilities to sustain high-volume agentic operations. By abstracting the complexities of browser management, they allow data teams to focus entirely on intent-based extraction logic.
This separation of infrastructure and logic is the foundational architecture of the modern web intelligence stack. The psychology behind this capital movement is rooted in the fear of data starvation.
As major web platforms increasingly lock their content behind paywalls and strict API limits, open-source data is drying up. Venture capitalists recognize that the next trillion-dollar AI models will be trained on exclusive and dynamically scraped enterprise data.
Consequently, owning the infrastructure that extracts this data is more lucrative than building another generic chatbot. Smart money is betting on the picks and shovels of the agentic gold rush. They are funding the decentralized compute and proxy networks that make AWI possible.
Defeating Biometric Fingerprinting
The cat-and-mouse game of web scraping has evolved into a sophisticated war of biometric fingerprinting. Advanced behavioral AI is now required to bypass legacy bot detection systems that rely on outdated fingerprinting.
Modern defensive systems analyze mouse trajectories, click latency, and scrolling cadence to differentiate between humans and automated scripts. To defeat these 2026-era anti-bot mechanisms, venture capital is heavily funding Agentic Proxy networks.
These decentralized compute providers combine residential IP rotation with advanced behavioral imitation models. The agents do not just request HTML. They render the page, pause to read text, and move the cursor with organic and human-like imperfection.
This level of sophisticated evasion ensures that data pipelines remain uninterrupted even when scraping highly protected enterprise portals. The 99.4% success rate in bypassing detection systems proves that intent-based, vision-action agents are virtually indistinguishable from real users.
The web has essentially been forced open, regardless of the defensive walls erected by site administrators. The implications of this evasion capability are massive for competitive intelligence gathering.
Companies can now silently monitor their rivals’ pricing strategies, inventory levels, and customer reviews without triggering security alarms. This stealth capability allows enterprises to maintain a persistent and invisible presence across the digital ecosystem.
Furthermore, the integration of vision-action models means that agents can solve complex CAPTCHAs and interactive security challenges autonomously. They can interpret visual puzzles, drag sliders, and identify objects with the same cognitive fluidity as a human operator.
The Architecture of Self-Healing Logic
The true genius of Autonomous Agentic Web Intelligence lies in its self-healing architecture. Traditional scrapers require rigid instructions. They dictate exactly which XPATH or CSS selector to target for extraction.
When a web developer changes a class name from a price box to a pricing container, the entire pipeline crashes instantly. Vision-action agents eliminate this fragility by operating on semantic intent rather than syntactic rules.
When instructed to extract the price of a product, the agent visually scans the rendered page for numerical values associated with currency symbols. It understands the context of the page layout. It recognizes that the price is typically located near the cart button.
If the website undergoes a massive redesign, the agent simply adapts its visual search parameters on the fly. It does not panic when the DOM structure changes. It merely looks for the new visual location of the requested data point.
This self-healing logic reduces pipeline downtime to near zero, ensuring a continuous flow of critical business intelligence. Moreover, these agents can generate their own synthetic training data to improve their extraction accuracy over time.
When an agent encounters a novel web interface, it experiments with different interaction strategies until it successfully retrieves the target data. It then logs this successful interaction path. This effectively teaches the agent how to navigate previously unseen digital environments.
This autonomous learning loop creates a compounding effect on pipeline resilience. As the agent interacts with more websites, its underlying vision-action model becomes increasingly robust and adaptable.
The Executive Action Plan: Scaling the Post-API Enterprise
Strategic Trajectory
- Capitalize on the ‘Post-API Economy’ by treating the global web as a universal structured database.
- Implement ‘Agent-to-Agent’ protocols to facilitate autonomous negotiation with web-based storefronts and portals.
- Transition to a ‘Liquid Data’ model where enterprise ERPs are populated in real-time by autonomous agents.
- Deploy continuous monitoring agents to track competitors, supply chains, and social sentiment without manual triggers.
- Integrate autonomous agentic web intelligence pipelines to enable high-frequency decision making and market arbitrage.
The strategic trajectory for enterprise data is moving rapidly toward the Post-API Economy. In this new paradigm, the global web is treated as a universal and infinitely scalable structured database.
Founders no longer need to wait for official API access or negotiate expensive data-sharing agreements with third-party platforms. By deploying autonomous agents, businesses can create a Liquid Data model where enterprise ERPs are populated in real-time.
These agents continuously monitor competitor pricing, global supply chain disruptions, and shifting social sentiment without requiring manual triggers. The enterprise brain is constantly fed with fresh and accurate intelligence. This enables proactive rather than reactive decision-making.
The most disruptive evolution on the horizon is the implementation of Agent-to-Agent protocols. Scrapers are evolving beyond mere data extraction into autonomous negotiators. They interact directly with web-based storefronts and B2B portals.
This capability will automate entire procurement lifecycles. It allows agents to source materials, negotiate prices, and execute contracts instantly. To capitalize on this trajectory, executives must immediately audit their existing data acquisition infrastructure.
Identifying legacy, selector-based scrapers is the first step toward migrating to a resilient and agentic architecture. The transition requires a strategic investment in deterministic agent frameworks and decentralized compute resources.
Furthermore, leadership must foster a culture of intent-based operations within their engineering and data teams. Developers must shift their mindset from writing rigid extraction scripts to designing flexible and goal-oriented agent prompts.
Conclusion: Liquid Data as a Competitive Moat
The era of fragile and maintenance-heavy web scraping has officially ended. It has been replaced by resilient and self-healing agentic pipelines. Organizations that fail to adopt vision-action agents will find themselves operating on delayed and fragmented data while their competitors execute in real-time.
Embracing the Post-API economy is no longer a futuristic concept. It is a mandatory survival strategy for the modern enterprise. The transition to Autonomous Agentic Web Intelligence represents a fundamental restructuring of how businesses interact with the digital world.
By leveraging behavioral AI and deterministic frameworks, companies can unlock unprecedented levels of operational efficiency and market awareness. The future belongs to those who can extract, process, and act upon liquid data faster than their rivals.
Navigating the intersection of technology, capital, and market psychology requires a sharp strategy. To future-proof your business architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is Autonomous Agentic Web Intelligence (AWI)?
Autonomous Agentic Web Intelligence (AWI) refers to advanced data acquisition pipelines that utilize multimodal vision-action agents. These agents navigate the web using computer vision and semantic understanding, allowing them to interact with dynamic elements exactly like a human user would, rather than relying on rigid, code-based selectors.
Why is traditional DOM-based web scraping failing for enterprises?
Traditional scraping is highly fragile because it relies on specific HTML tags and DOM structures. When websites undergo redesigns or update their UI, these hardcoded selectors break. Research indicates that legacy infrastructure suffers from a 60% failure rate, leading to excessive engineering maintenance costs.
How do AI agents bypass modern bot detection systems?
Modern agents use behavioral-imitation AI to mimic human-like patterns, such as organic mouse trajectories, varying click latencies, and natural scrolling cadence. According to Cloudflare’s 2026 data, these sophisticated evasion techniques allow agents to bypass legacy biometric fingerprinting in 99.4% of attempts.
What does ‘self-healing’ mean in the context of web intelligence?
Self-healing logic refers to an agent’s ability to rewrite its own navigation and extraction logic in real-time. Instead of crashing when a site’s structure changes, the agent visually scans the page for the requested data point (like a ‘price’ or ‘net profit’) and adapts its interaction strategy autonomously without developer intervention.
What are the financial implications of switching to agentic data pipelines?
Enterprises can see an 82% reduction in engineering maintenance hours, freeing up talent for higher-value predictive analytics. Furthermore, with local agent inference achieving sub-500ms latency, firms can execute real-time market arbitrage and pricing adjustments, creating a significant competitive moat.
How does the ‘Post-API Economy’ redefine data acquisition?
In a Post-API Economy, the entire web is treated as a universal structured database. Businesses no longer need to rely on restrictive or expensive third-party API agreements; instead, they deploy autonomous agents to extract proprietary, liquid data directly from the source in real-time.