

Key Points
- Vision API Extraction: Utilizing Google Cloud Vision API’s advanced layout analysis to accurately extract trapped brand mentions from legacy, multi-column PDF documents.
- Serverless Outreach Pipelines: Deploying Node.js and Zapier webhooks to instantly route OCR-extracted entities into CRM platforms for sub-minute digital PR responses.
- Semantic Vector Enrichment: Converting raw OCR output into structured JSON-LD via LLMs to ensure PDF content is fully ingestible by modern Vector Databases and AI-driven search engines.
Table of Contents
The Document Data Silo Dilemma
Right now, your brand is likely bleeding authority through an invisible tax hidden deep within your server folders.
Every month, industry analysts, academic researchers, and enterprise partners publish high-value whitepapers that mention your company. Unfortunately, these mentions are frequently trapped inside legacy, flattened PDF documents.
We call this the Document Data Silo dilemma. When a brand mention exists solely within a graphical layer of a PDF, it becomes a digital ghost.
Search engine crawlers cannot highlight it, copy it, or follow it. This prevents the flow of PageRank, depriving your SEO strategy of high-quality link attribution.
It is like having a winning lottery ticket locked inside a glass vault. You can see the value, but you cannot cash it in to boost your domain authority.
The solution to this architectural bottleneck is OCR-driven PDF backlink automation. By leveraging optical character recognition, we can programmatically shatter these glass vaults.
This approach transforms invisible graphical text into actionable, structured data. It bridges the gap between static document storage and proactive digital PR, ensuring no brand mention goes uncapitalized.
Performance Metrics Driving the OCR Revolution

The shift toward automated document processing is driven by massive leaps in machine learning performance. Recent industry performance reports indicate that vision models now achieve a staggering 99.2% recognition accuracy.
This near-parity with native text extraction means complex, multi-column scientific layouts are no longer black boxes. The system can accurately parse footnotes, sidebars, and embedded charts without losing vital context.
You can implement this advanced text detection using modern cloud-based vision APIs.
Furthermore, processing speeds have reached unprecedented levels. Engineering benchmarks report an average API latency of just 240 milliseconds per page.
This high-throughput capability is crucial for large-scale operations. It allows servers to scan hundreds of pages in the blink of an eye, aligning perfectly with modern search engine indexation standards for complex file types.
By operating at these speeds, enterprise SEO teams can audit massive historical databases in hours rather than months. The metrics prove that programmatic PDF extraction is no longer an experimental concept, but a highly efficient reality.
Extracting Value From Massive Asset Libraries
Large-scale asset libraries are notorious for hoarding legacy scanned PDFs. These documents are completely invisible to standard link crawlers, resulting in thousands of ghost mentions that provide zero SEO value.
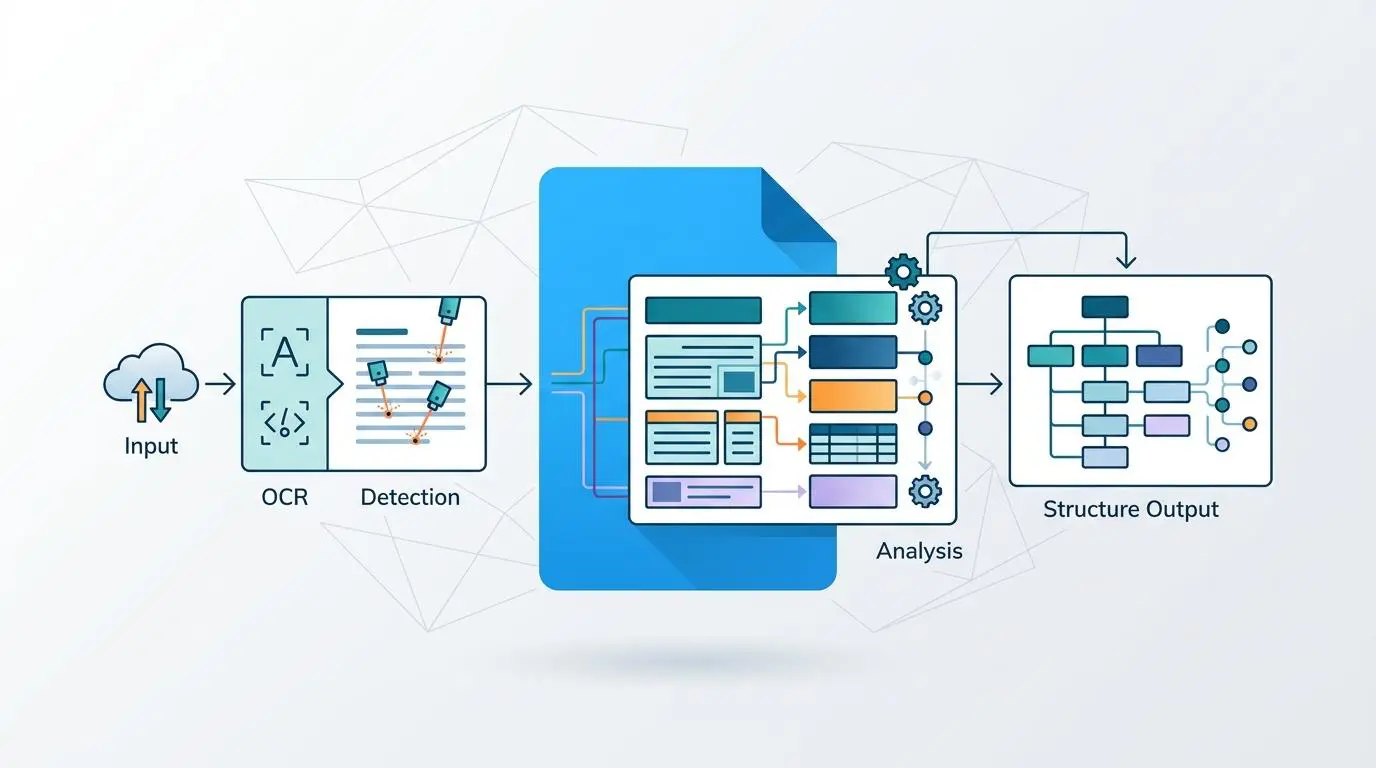
To extract value from these massive libraries, we turn to advanced cloud vision APIs. These modern tools now support highly sophisticated document text detection.
This feature goes beyond simple text scraping. It provides enhanced layout analysis for multi-column PDFs, understanding the spatial relationship between paragraphs, images, and headings.
This spatial awareness allows for the precise extraction of brand-adjacent context from flattened images. When the system finds your brand name, it also captures the surrounding sentences.
This contextual data is vital for assessing the sentiment and relevance of the mention. It ensures your outreach team only targets high-quality, contextually appropriate backlink opportunities.
By automating this extraction, you turn a dead archive into a rich vein of digital PR targets. Every old report becomes a potential new backlink.
Reacting Instantly With Webhook Outreach Routing

Manual PDF auditing is incredibly labor-intensive. It lacks the speed required for modern, reactive public relations.
By the time a mention is found manually by an SEO team, the editorial window for requesting a link insertion has often closed. Authors move on, and modifying an archived PDF becomes a low priority.
To solve this, we rely on powerful automation infrastructure. This allows for the direct streaming of OCR-extracted entities into centralized outreach platforms.
Using webhooks, the extracted brand mentions and their context are instantly routed to CRM tools. This creates a seamless, automated pipeline from discovery to communication.
This automation enables sub-minute response times to new PDF mentions. Your PR team can automatically dispatch a polite, context-aware email to the author while the document is still fresh in their mind.
Striking while the iron is hot dramatically increases your link acquisition conversion rate. It transforms passive monitoring into an aggressive, automated acquisition strategy.
Building a Serverless Document Processing Pipeline
Traditional, monolithic SEO tools lack the capability to process binary document formats at scale. They are built for HTML, not for the complex byte streams of PDF files.
This limitation necessitates a custom-built API pipeline to bridge the gap between document storage and your outreach CRM. We achieve this by building a serverless, event-driven architecture.
By integrating Node.js parsing libraries with cloud functions, we create a system that reacts instantly to new data. The moment a new PDF is indexed by a search engine or uploaded to a monitored directory, the function fires.
This serverless setup ensures you only pay for the exact compute time used during the OCR scan. It is highly scalable, handling a single PDF or a batch of ten thousand with equal efficiency.
The architecture effectively turns your static file storage into a proactive, link-hunting machine. It operates silently in the background, constantly feeding new opportunities to your outreach team.
By removing the manual bottleneck, your SEO engineers can focus on strategy rather than tedious file parsing.
Preparing Document Data for AI and Vector Search
Traditional PDFs fail to rank for long-tail semantic queries because their internal structure is completely opaque. Large language models, which increasingly power search generative experiences, cannot easily digest flattened images.
To make this content RAG-friendly, we must enrich it semantically. We start by converting the raw PDF OCR output into structured JSON-LD fragments.
This is achieved through advanced LLM prompting utilizing modern AI APIs. The artificial intelligence reads the raw text and structures it into clear, machine-readable entities.
This prepares the document data for ingestion into vector databases. Once vectorized, the content becomes highly visible to AI-driven search engines.
Recent search engine updates have highlighted the importance of this process. Deep document understanding algorithms now assign significant weight to OCR-extracted text within PDFs, provided the file is optimized for mobile viewing.
By structuring this data, you ensure your whitepapers and reports dominate AI-generated search summaries.
The Era of Dynamic PDF Injection
The landscape of document SEO is shifting dramatically. We expect the rise of dynamic PDF injection across enterprise architectures in the near future.
In this scenario, server-side agents will use real-time OCR to identify brand mentions on the fly. They will then overlay interactive, linkable HTML elements directly on top of static PDF renders.
This will effectively turn all PDF mentions into live backlink opportunities automatically, without requiring the original author to edit the source file. The gap between static documents and the interactive web will completely dissolve.
Navigating the intersection of technical SEO, programmatic architecture, and workflow automation requires a sharp strategy. To future-proof your site’s architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is OCR-driven PDF backlink automation?
OCR-driven PDF backlink automation is a technical SEO process that uses Optical Character Recognition to identify and extract brand mentions from flattened or graphical PDF documents. This allows brands to transform invisible mentions into actionable data for automated digital PR and link-building outreach.
Can search engines crawl and index text inside flattened PDF files?
Standard crawlers often struggle with flattened PDF images, but advanced vision models like the Google Cloud Vision API can now recognize text with over 99% accuracy. Converting these files via OCR makes the content indexable, allowing search engines to recognize mentions and pass authority through the flow of PageRank.
What is the Document Data Silo dilemma in digital marketing?
The Document Data Silo dilemma refers to the thousands of brand mentions trapped inside non-selectable PDF layers in server folders and asset libraries. These mentions act as digital ghosts that provide no SEO value until they are extracted and converted into structured data for link acquisition strategies.
How do webhooks improve the speed of backlink outreach?
Webhooks enable real-time routing of OCR-extracted mentions directly into outreach platforms like Lemlist or Pitchbox. This automation allows SEO teams to react instantly to new mentions, sending context-aware emails to authors while the document is still fresh, which significantly increases conversion rates.
How do you make PDF content RAG-friendly for AI search engines?
To optimize PDF content for AI-driven search generative experiences, raw OCR output is processed by LLMs and converted into structured JSON-LD fragments. This semantic enrichment makes the document data compatible with Vector Databases and Retrieval-Augmented Generation (RAG), ensuring visibility in AI search summaries.
Is automated PDF link building scalable for enterprise SEO?
Yes, by using serverless document processing pipelines involving Node.js and Google Cloud Functions, enterprise SEO teams can audit and process thousands of legacy PDFs simultaneously. This event-driven architecture is highly cost-effective and scalable, turning static archives into proactive link-hunting machines.