Executive Summary
- Transforms unstructured textual data into structured semantic nodes, facilitating Knowledge Graph integration and LLM comprehension.
- Enhances the precision of Retrieval-Augmented Generation (RAG) by enabling high-fidelity mapping between user queries and document entities.
- Serves as a critical pillar for Generative Engine Optimization (GEO) by establishing entity salience and topical authority within AI training sets.
What is Entity Extraction?
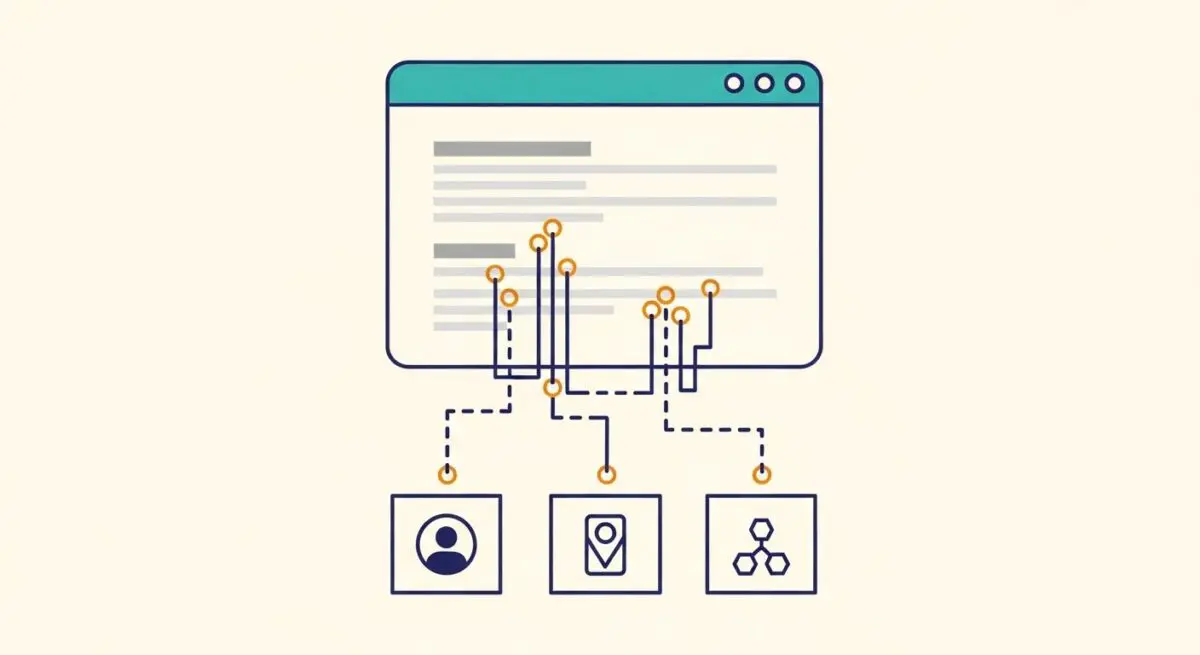
Entity Extraction, also known as Named Entity Recognition (NER), is a subtask of Natural Language Processing (NLP) that involves the automated identification and categorization of specific information units within unstructured text. These units, or entities, typically include names of people, organizations, locations, dates, monetary values, and technical terminology. In the context of modern AI architecture, entity extraction functions as the primary mechanism for converting raw linguistic input into machine-readable data structures.
The process utilizes sophisticated machine learning models, often based on Transformer architectures, to analyze the context surrounding a token. By evaluating the syntactic and semantic relationships within a sentence, the system assigns a probability score to determine if a word or phrase belongs to a predefined category. This structured output allows Large Language Models (LLMs) and search engines to build semantic triples (subject-predicate-object), which are the building blocks of comprehensive Knowledge Graphs.
The Real-World Analogy
Imagine a massive, unorganized library where millions of books are scattered on the floor. A human researcher looking for information on “Quantum Computing in Berlin” would have to read thousands of pages to find relevant mentions. Entity Extraction acts like an automated high-speed scanning system that instantly reads every page and applies digital “tags” to every person, city, and technology mentioned. Instead of a pile of books, you now have a perfectly indexed database where you can instantly filter for every instance where “Berlin” (Location) and “Quantum Computing” (Technology) appear together, allowing for immediate retrieval without manual reading.
Why is Entity Extraction Important for GEO and LLMs?
For Generative Engine Optimization (GEO), entity extraction is the fundamental layer that determines how AI models perceive brand authority and relevance. When an AI search engine like Perplexity or Google’s Search Generative Experience (SGE) processes a query, it does not just look for keywords; it identifies the entities involved. If your brand is frequently extracted as a high-confidence entity in association with specific technical problems or solutions, the model assigns higher entity salience to your content.
In RAG (Retrieval-Augmented Generation) systems, entity extraction improves the accuracy of the retrieval step. By extracting entities from a user’s prompt, the system can query vector databases with higher precision, ensuring that the context provided to the LLM is factually aligned with the user’s intent. This reduces hallucinations and ensures that source attribution is directed toward the most authoritative entity nodes.
Best Practices & Implementation
- Implement Robust Schema Markup: Use JSON-LD structured data (Schema.org) to explicitly define entities, relationships, and attributes, reducing the computational overhead for AI crawlers.
- Maintain Entity Consistency: Ensure that brand names, product titles, and key personnel are referred to using consistent nomenclature across all digital touchpoints to strengthen the entity’s signature in training data.
- Optimize for Co-occurrence: Position your primary entities in close proximity to established, high-authority entities within your niche to build semantic associations in the AI’s latent space.
- Provide Clear Contextual Cues: Avoid ambiguous pronouns (e.g., “it,” “they”) in technical documentation; instead, repeat the entity name or use specific descriptors to facilitate accurate NER tagging.
Common Mistakes to Avoid
One frequent error is Entity Ambiguity, where a brand uses a generic name that overlaps with common nouns or other famous entities, making it difficult for NLP models to disambiguate the specific brand. Another mistake is the Lack of Structured Data; relying solely on unstructured text forces AI models to guess the relationships between entities, which can lead to lower visibility in AI-generated summaries. Finally, Inconsistent Naming Conventions across different platforms can fragment an entity’s authority, preventing the AI from consolidating all mentions into a single, powerful Knowledge Graph node.
Conclusion
Entity extraction is the bridge between human language and machine-readable knowledge, serving as a non-negotiable component for visibility in the era of AI-driven search and Generative Engine Optimization.