Executive Summary
- Source attribution is the technical mechanism by which Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) systems map generated claims to specific web-based data sources.
- It serves as the primary bridge between generative output and referral traffic, directly influencing a brand’s visibility within AI search interfaces like Perplexity and SearchGPT.
- Optimization for attribution requires high semantic density, verifiable factual claims, and robust technical signals such as Schema.org markup and persistent identifiers.
What is Source Attribution?
Source attribution in the context of Generative Engine Optimization (GEO) refers to the computational process where an AI system identifies and cites the specific external documents used to synthesize a response. Unlike traditional search engines that provide a list of links, AI engines utilize Retrieval-Augmented Generation (RAG) to pull context from the web, process it through a Large Language Model (LLM), and then generate a cohesive answer. Attribution is the grounding mechanism that links the generated tokens back to the source URI to ensure factual accuracy and provide users with a path for verification.
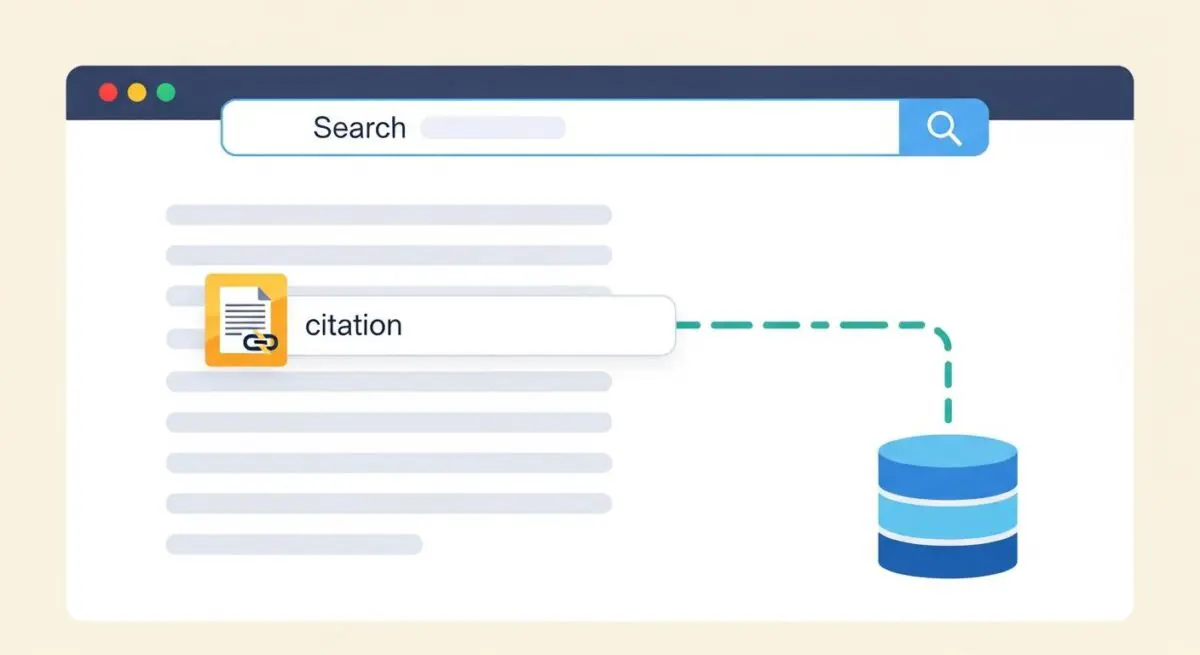
Technically, source attribution involves the alignment of retrieved text chunks with the model’s generated output. When an LLM produces a statement, the system calculates which retrieved snippets have the highest semantic similarity or influence on that specific statement. This results in the placement of citations—often in the form of footnotes or inline links—that credit the original publisher. For GEO professionals, this is the fundamental metric of success, as it determines whether a brand’s content is recognized as the authoritative source for a given query.
The Real-World Analogy
Imagine a high-stakes legal trial where a judge must deliver a final ruling based on thousands of pages of evidence. Instead of just stating the verdict, the judge provides a detailed report where every single factual claim is followed by a specific reference to a witness testimony or a physical exhibit (e.g., “The defendant was at the scene [Exhibit A, Page 12]”). Source attribution is that precise referencing system; it transforms a general statement into a verifiable fact by showing exactly which “evidence” from the internet was used to build the conclusion.
Why is Source Attribution Important for GEO and LLMs?
Source attribution is the lifeblood of visibility in the AI-search era. For LLMs, attribution mitigates the risk of hallucinations by forcing the model to rely on retrieved context rather than internal weights alone. This grounding increases the perceived reliability of the AI engine. From a GEO perspective, attribution is the only way to capture share of voice in a zero-click environment. If an AI engine synthesizes your content but fails to attribute it, your brand gains no authority and zero referral traffic.
Furthermore, high attribution rates signal to the AI engine that your content is a high-utility source. Engines like Perplexity and SearchGPT prioritize sources that are structured in a way that is easy to parse and cite. Consistent attribution builds a Citation Loop, where being cited frequently increases your entity authority, leading to more frequent inclusion in future RAG retrieval sets.
Best Practices & Implementation
- Implement Granular Schema Markup: Use specific Schema.org types (e.g., Article, Product, TechArticle) and include the “citation” or “isBasedOn” properties to explicitly define relationships between data points.
- Optimize for Semantic Density: Structure content with clear, declarative sentences that answer specific “who, what, where, why” questions. This makes it easier for RAG systems to map your text to user intents.
- Maintain Factual Integrity: AI engines use cross-referencing to validate claims. Ensure your data is consistent with other authoritative sources to increase the probability of being selected as the primary citation.
- Use Persistent Identifiers: Ensure that URLs and internal anchors are stable. AI models often cache source relationships; broken links or frequent redirects can degrade attribution reliability.
Common Mistakes to Avoid
A frequent error is the use of fluff or overly decorative language that obscures the factual core of the content, making it difficult for LLMs to extract citable snippets. Another critical mistake is blocking AI crawlers via robots.txt or aggressive firewalls; if the RAG pipeline cannot access the content, attribution is impossible. Finally, many brands fail to provide clear authorship or entity signals, leaving the AI engine unable to verify the credibility of the source.
Conclusion
Source attribution is the technical bridge between generative synthesis and web authority, serving as the primary driver for traffic and brand trust in AI-driven search ecosystems.