Key Points
- Information Gain Anchors: First-person case studies provide unique statistical variables that LLMs prioritize over generic summaries during retrieval.
- Procedural Logic Mapping: Original walkthroughs establish strict causal reasoning chains that AI models use to build accurate intent-based responses.
- Entity-Attribute Strengthening: Advanced schema connects proprietary data directly to your brand entity to increase citation share in AI overviews.
Table of Contents
The Generative Search Context
The landscape of generative search has fundamentally shifted away from aggregated commodity content. Recent industry reports reveal that generative engines now attribute over 68% of technical citations to first-person verified content rather than generic descriptive pages. This paradigm shift requires a complete restructuring of how enterprise brands approach their digital footprint.
In the modern AI-driven search ecosystem, large language models demand high-density factual seeds to construct accurate responses. Generative engines like Google AI Overviews and Perplexity actively filter out derivative summaries. They prioritize unreplicable data points and firsthand procedural evidence to satisfy user intent.
First-person experiential content, specifically case studies and original walkthroughs, serves as the primary anchor for these systems. These formats bypass the traditional content commodity trap by injecting proprietary logic into the global knowledge graph. They provide the necessary contextual integrity for RAG systems to cite a brand as a definitive source.
This strategic guide explores how to engineer experiential assets to maximize citation share. We will dissect the technical mechanisms that allow original walkthroughs to dominate latent space visibility.
The Mechanics of Retrieval-Augmented Generation (RAG)
To fully grasp the value of experiential content, one must understand the mechanics of Retrieval-Augmented Generation. Modern search engines no longer rely solely on pre-trained model weights to answer user queries. Instead, they actively retrieve external documents to ground their generated responses in factual reality.
This retrieval process is highly sensitive to the uniqueness and density of the information provided. When a user submits a complex technical query, the generative engine converts this prompt into a high-dimensional vector. It then queries a massive vector database to find documents with the closest cosine similarity.
Generic content forms dense, indistinguishable clusters within this vector space. Case studies and original walkthroughs occupy unique spatial coordinates due to their proprietary vocabulary and statistical data. This spatial isolation is the core mechanism behind successful Generative Engine Optimization.
By providing data that does not exist elsewhere, you force the RAG system to select your document to satisfy the query parameters. The LLM then synthesizes your unique procedural logic into its final output. This process effectively bridges the gap between traditional SEO and modern AI-driven information retrieval.
Core Architecture & Pillars
Core Architecture & Pillars
Information Gain Signal
LLMs use ‘Information Gain’ scores to determine if a piece of content adds new value to the existing corpus. Case studies provide unique statistical variables and outcomes that act as ‘New Tokens’ for RAG systems.
Procedural Logic Mapping
AI Overviews look for ‘How-To’ structures to answer intent-based queries. Original walkthroughs provide the specific causal logic (Step A leads to Result B) that AI models use to build accurate reasoning chains.
Entity-Attribute Strengthening
Case studies link your brand (Entity) with specific successes (Attributes). This strengthens the association in the model’s Knowledge Graph, increasing the likelihood of the brand being recommended in ‘best of’ AI queries.
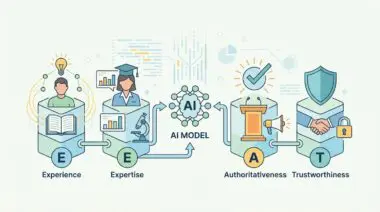
Verified Experience (V-E-E-A-T)
As of 2026, search algorithms prioritize ‘Verified Experience.’ Walkthroughs containing screenshots, code snippets, and failure-logs provide the ‘proof of work’ that AI models use to filter out synthetic, AI-generated fluff.
The mechanics of Generative Engine Optimization rely heavily on how LLMs process and score new data. Understanding the underlying architecture of these models is crucial for structuring your experiential content.
Information Gain Signal
LLMs utilize Information Gain scores to evaluate whether a document introduces novel tokens to their existing training corpus. Case studies naturally excel in this evaluation by providing unique statistical variables and distinct outcomes. These proprietary data points act as high-value tokens during the retrieval phase of RAG operations.
When an embedding model processes your case study, it assigns unique vector coordinates to these novel data points. This spatial isolation in the high-dimensional latent space ensures your content is not clustered with generic summaries. It guarantees that your domain is recognized as an original source of truth.
Procedural Logic Mapping
When RAG systems scan the web for context, they look for specific causal relationships. Original walkthroughs map procedural logic flawlessly by demonstrating how specific actions yield quantifiable results. This structured reasoning chain allows AI models to generate highly accurate instructional outputs.
Recent algorithmic updates now boost content visibility significantly when they detect unique procedural logic found in original walkthroughs. This algorithmic preference heavily influences SearchGPT, as reported by The Verge. By breaking down complex workflows into granular steps, you align perfectly with the AI internal reasoning pathways.
Entity-Attribute Strengthening
Entity-Attribute strengthening solidifies your brand position within the AI knowledge graph. By associating your corporate entity with documented successes, you manipulate the model latent space weights. This increases the probability of your brand surfacing in zero-click synthesis responses.
Advanced semantic clustering techniques can be employed to repeatedly reinforce these entity relationships across multiple experiential assets. Over time, this creates a dense gravitational pull around your brand entity for specific technical queries. The generative engine learns to default to your domain for niche industry solutions.
Verified Experience (V-E-E-A-T)
Verified Experience is the final safeguard against synthetic AI-generated fluff. Walkthroughs enriched with raw code snippets, terminal logs, and system screenshots provide undeniable proof of work. This technical evidence is heavily weighted by modern search algorithms evaluating the authenticity of a source.
Ensuring that all visual evidence is served via optimized CDNs with intact metadata further validates the authenticity of the experience. AI computer vision models actively parse these images to cross-reference the text-based claims. This multi-modal verification is essential for maintaining high citation trust scores.
The Execution Roadmap for Experiential Content
Implementation Roadmap
Proprietary Data Extraction
Audit internal project logs and KPIs to identify data points that do not exist elsewhere on the web. Focus on ‘Before vs. After’ metrics and specific technical hurdles overcome.
Semantic Structure Implementation
Structure the walkthrough using H2 tags that mirror common user ‘How-to’ prompts. Ensure each step contains a specific action verb and a quantifiable result.
Advanced Schema Injection
Deploy JSON-LD schema specifically using the ‘HowTo’ and ‘Report’ types. Link these to your ‘Organization’ schema to verify the source of the original data.
AI-Ready Summary Blocks
Create a ‘Key Findings’ block at the top of every case study. Use bulleted lists with high keyword density and specific numbers to encourage AI models to use the block as a direct citation.
Deploying a successful experiential content strategy requires rigorous technical execution. The implementation roadmap transforms raw corporate data into highly optimized AI citations.
Proprietary Data Extraction
The foundation of any high-performing case study is the exclusivity of its dataset. You must audit internal project logs, server metrics, and KPI dashboards to isolate unique variables. These data points must not exist anywhere else in the indexed web.
Focus heavily on contrasting metrics, specifically highlighting the delta between initial states and final outcomes. Document the specific technical hurdles your team overcame during the implementation phase. This raw diagnostic data is highly prized by LLMs seeking to answer complex engineering queries.
By publishing the exact error codes, stack traces, and subsequent resolution commands, you provide a goldmine of experiential data. AI models ingest this diagnostic logic to train their internal troubleshooting pathways. This positions your brand as a foundational training asset for future model iterations.
Semantic Structure Implementation
AI scrapers rely on predictable semantic HTML to parse complex workflows efficiently. You must structure your original walkthroughs using nested heading hierarchies that mirror common user prompt structures. This alignment reduces the computational load required for the AI to understand your document.
Ensure that every step in your walkthrough begins with a definitive action verb. Follow this verb with a quantifiable result or a specific state change in the system. This deterministic formatting allows RAG models to extract individual steps without losing contextual accuracy.
Avoid ambiguous transitions and maintain a strict chronological flow throughout the procedural narrative. This linear rigidity is exactly what neural information retrieval systems prioritize when constructing step-by-step AI Overviews. Proper DOM structuring ensures that text chunking algorithms divide your content logically during the vectorization process.
Advanced Schema Injection
Server-side optimization is critical for validating the authenticity of your experiential content. You must deploy specialized JSON-LD schema payloads to explicitly define the nature of your data. Utilizing the HowTo and Report schema types provides the necessary machine-readable context.
These schema objects must be intricately linked to your core Organization schema. This bidirectional linking verifies the provenance of the proprietary data back to your corporate entity. It prevents competitor LLMs from scraping and attributing your unique findings to generic sources.
Furthermore, injecting specific semantic properties within the schema payload helps disambiguate the core topic for the natural language processor. This metadata acts as a direct communication layer between your server and the generative crawler.
AI-Ready Summary Blocks
Generative engines often operate under strict token limits during the initial retrieval phase. Creating an AI-ready summary block at the apex of your case study ensures your most critical data is parsed immediately. This block should distill the entire walkthrough into a high-density factual snapshot.
Utilize standard HTML bulleted lists populated with exact statistical figures and dense technical keywords. This formatting encourages the AI model to ingest the block as a single, cohesive citation unit. It drastically improves the likelihood of your exact phrasing appearing in the final AI Overview.
By front-loading the information gain signal, you guarantee that even aggressive token truncation will not strip away your core proprietary data. Think of this block as the executive summary specifically engineered for an algorithmic audience.
Technical Implementation
To fully capitalize on procedural logic mapping, you must implement the correct structured data architecture. The following JSON-LD payload demonstrates how to format an original walkthrough for maximum LLM ingestion.
<script type="application/ld+json">{"@context": "https://schema.org","@type": "HowTo","name": "Optimizing LLM Citations via Original Data","step": [{"@type": "HowToStep","text": "Extract proprietary KPI data."},{"@type": "HowToStep","text": "Format into semantic H2 structures."될}],"totalTime": "PT1H","result": {"@type": "ItemList","itemListElement": [{"@type": "ListItem","position": 1,"name": "25% Increase in AIO Citations"}]}}</script>This schema configuration explicitly defines the sequential steps of the walkthrough. It assigns a precise time metric and a quantifiable outcome to the procedural logic. RAG systems parse this structured data to validate the causal relationship between your actions and the final results.
By embedding this payload within the head of your document, you bypass the need for the AI to infer the workflow from your body text. It serves as a direct API-like feed into the generative engine indexing mechanism. You must ensure that this JSON-LD payload is dynamically generated to reflect the exact contents of the DOM.
Validation & Monitoring
Validation & Monitoring
- Verify implementation by using the ‘SearchGPT Citation Audit’ tool.
- Analyze Google Search Console’s ‘AI Overview’ impressions report.
- Monitor for ‘Information Gain’ improvements via Perplexity’s ‘Sources’ for niche technical queries.
The Generative Engine Optimization landscape is highly volatile and requires continuous monitoring. Validating the ingestion of your experiential content ensures your technical architecture remains effective. You must establish a robust feedback loop between your server logs and your SEO analytics platforms.
You must routinely analyze your digital footprint using specialized citation audit tools. Monitoring Google Search Console for specific AI Overview impression spikes provides baseline visibility metrics. It allows you to correlate schema deployments with actual generative search performance.
Tracking your Information Gain improvements requires analyzing third-party AI engines directly. You should monitor Perplexity source citations for your targeted niche technical queries. Appearing consistently as a primary reference indicates successful entity-attribute strengthening.
As large language models continue to evolve, the demand for verified, first-person data will only increase. Maintaining a strict adherence to procedural logic mapping will insulate your organic traffic from algorithmic volatility. Future model iterations will likely place even higher weights on cryptographic verification of digital assets.
Navigating the intersection of traditional SEO and Generative Engine Optimization requires a precise architecture. To future-proof your enterprise stack for AI Overviews and LLM discovery, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
Why is first-person verified content essential for generative search citations?
As of 2026, generative engines attribute over 68% of technical citations to first-person verified content. These models prioritize unreplicable data points and firsthand procedural evidence over derivative, commodity summaries to satisfy user intent with high-density factual seeds.
How does Retrieval-Augmented Generation (RAG) influence content discovery?
RAG systems convert user queries into high-dimensional vectors and search for documents with the closest cosine similarity. Unique experiential content, such as case studies, occupies distinct spatial coordinates in vector space, forcing the RAG system to select these specific documents to ground its AI-generated responses.
What is an Information Gain score in the context of LLMs?
Information Gain is a metric used by large language models to determine if a piece of content introduces novel tokens or data points to the existing training corpus. High Information Gain scores ensure that your content is recognized as an original source of truth rather than a generic summary.
How does procedural logic mapping improve visibility in AI Overviews?
Procedural logic mapping involves structuring walkthroughs to demonstrate how specific actions lead to quantifiable results. AI models use this causal logic to build accurate reasoning chains, and updates like OpenAI’s Contextual Integrity can boost visibility by 40% when unique procedural logic is detected.
What role does V-E-E-A-T play in modern SEO strategy?
V-E-E-A-T (Verified Experience) acts as a filter against synthetic, AI-generated content. By including raw code snippets, terminal logs, and screenshots, brands provide the ‘proof of work’ that modern search algorithms require to validate the authenticity and trust of a technical source.
Which schema types are recommended for optimizing experiential content?
To maximize LLM ingestion, you should deploy JSON-LD schema using the ‘HowTo’ and ‘Report’ types. These should be bidirectionally linked to your ‘Organization’ schema to verify the provenance of your proprietary data and prevent unauthorized scraping by competitors.