Key Points
- Elimination of Parametric Freeze: RAG architecture transforms static LLMs into dynamic systems, solving the Black Box Trust crisis by providing a verifiable audit trail for every output.
- The Hybrid Stack Advantage: Enterprises are pairing fine-tuned, high-speed open-weights models with RAG to achieve sub-second inference and near-zero hallucinations in mission-critical applications.
- The 14-Million-Query Threshold: Strategic scaling requires balancing token-heavy RAG costs against model fine-tuning capital expenditures once query volumes hit critical mass.
Table of Contents
The Core Friction: Breaking the Parametric Freeze
According to 2026 data from Synvestable, implementing RAG architecture reduces LLM hallucination rates by 70% to 90% compared to standard out-of-the-box models. This staggering metric has effectively made it the non-negotiable standard for enterprise-grade accuracy. We are no longer living in an era where generative AI is allowed to guess.
The core friction crippling early enterprise AI adoption was the Parametric Freeze. This inherent limitation prevents large language models from accessing critical information beyond their static training cutoff dates. Retraining these massive neural networks daily is a financial and temporal impossibility for even the most well-funded tech giants.
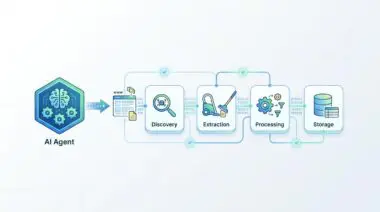
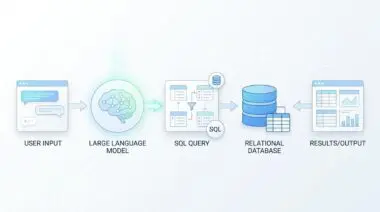
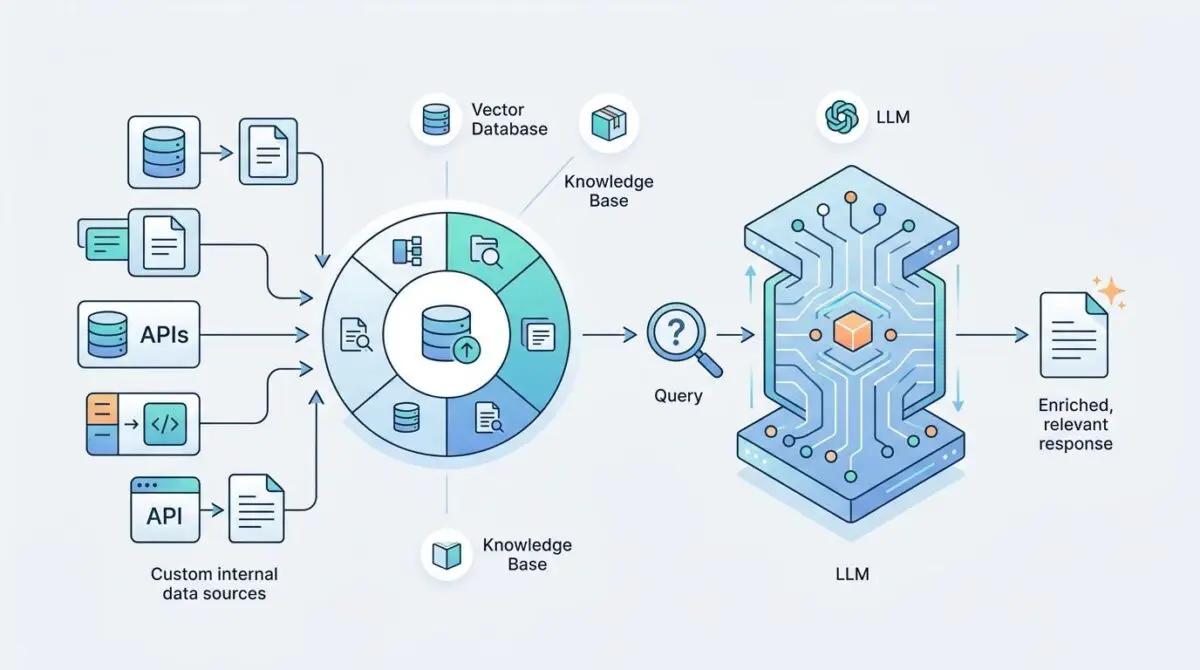
Custom Data Integration via RAG (Retrieval-Augmented Generation) solves this exact bottleneck natively. It transforms static intelligence into dynamic, real-time corporate memory. By fetching live data at the moment of inference, RAG acts as a cognitive bridge between a frozen model and a constantly evolving world.
Furthermore, tethering every AI response to a traceable source document solves the Black Box Trust crisis. Executives can finally trust AI outputs because they are grounded in verifiable reality. This creates a rigorous audit trail that satisfies strict global AI compliance frameworks while drastically reducing legal liability.
Market Intelligence & Smart Capital
Market Intelligence & Data
Vector Database Market Size
The global market for vector databases has surged to $3.73 billion in 2026 as enterprises prioritize high-dimensional data retrieval, according to The Business Research Company.
Agentic App Penetration
Gartner forecasts that 40% of all enterprise applications will feature embedded task-specific AI agents using RAG architecture by the end of 2026.
Factuality Improvement
Independent benchmarks reported by Gitnux in early 2026 show that RAG-integrated systems provide a 74% boost in factual groundedness over base LLM counterparts.
Agentic AI VC Funding
Venture capital investment into the agentic AI and RAG orchestration layer reached $1.1 billion in just the first five months of 2026, per New Market Pitch.
The data reveals a massive tectonic shift in how institutional capital views artificial intelligence. Venture capital is flowing aggressively into Context Engineering and the foundational Vector Infrastructure that powers it. This is not just about upgrading search capabilities; it is about building the cognitive operating system for the modern enterprise.
As a testament to this shift, Gartner forecasts that 40% of all enterprise applications will feature embedded task-specific AI agents using RAG architecture by the end of 2026. This rapid adoption is driven entirely by the need for verifiable accuracy across corporate ecosystems.
Independent benchmarks reported by Gitnux in early 2026 show that RAG-integrated systems provide a 74% boost in factual groundedness over base LLM counterparts.
The Rise of Vector Infrastructure
Pinecone and Weaviate continue to dominate the native vector database space. Pinecone recently reached a peak valuation driven by its real-time serverless indexing breakthroughs. Smart money from top venture firms is prioritizing startups that automate the complex ETL-to-Vector pipeline.
These investments aim to turn messy, unstructured corporate data into high-fidelity AI memory without any human intervention. The goal is seamless data ingestion where PDFs, emails, and internal messages are instantly vectorized. Significant capital is also shifting toward Agentic Orchestration layers like LangChain and LlamaIndex.
These platforms have rapidly become the standard enterprise middleware for building complex retrieval systems. They allow developers to chain multiple data sources together, creating a unified intelligence layer. This orchestration is what ultimately turns a raw language model into a highly capable business asset.
The Strategic Deep Dive: Agentic Orchestration
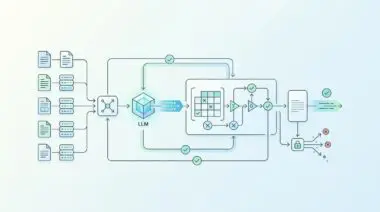
RAG has transitioned entirely from simple semantic search to Agentic RAG and GraphRAG. Modern enterprises no longer deploy systems that just fetch relevant text chunks based on keyword proximity. Instead, they deploy autonomous agents that leverage complex knowledge graphs to perform deep reasoning.
This multi-hop reasoning allows AI to connect dots across highly siloed data lakes. An agent can now read a financial report in one database, cross-reference it with a legal contract in another, and synthesize a comprehensive risk assessment. This represents a paradigm shift from data retrieval to true knowledge synthesis.
Deploying the Hybrid Stack
The killer strategy for enterprise architecture today is the Hybrid Stack. Organizations are actively fine-tuning small, high-speed open-weights models specifically for domain-centric logic. They then use RAG as a dynamic memory module to feed these fast models volatile, real-time facts.
This dual-layered architecture allows for sub-second query responses with near-zero hallucination rates. It is the exact infrastructure currently supporting mission-critical operations across global legal and financial services. By separating reasoning capability from factual knowledge, businesses achieve unprecedented scalability and precision.
Furthermore, the hybrid approach drastically reduces reliance on massive, expensive proprietary APIs. Companies retain full control over their intellectual property while still benefiting from state-of-the-art reasoning capabilities. It is the ultimate balance of performance, security, and cost-efficiency.
The 14-Million-Query Inflection Point
Scaling this architecture requires a deep understanding of unit economics and compute costs. Industry research identifies a 14-million-query inflection point for enterprise deployments. This is the precise volume where the token-heavy operating costs of RAG begin to exceed the amortized capital expenditure of fine-tuning a smaller specialized model.
Every time a RAG system fetches context, it consumes thousands of tokens, which directly impacts the bottom line. Executives must monitor their pipeline throughput closely to avoid severe margin compression at scale. When a specific domain query crosses this critical threshold, the strategic move is to bake that specific knowledge directly into the model weights.
By fine-tuning the model on high-frequency queries, organizations eliminate the need for constant data retrieval. RAG is then reserved strictly for the long-tail of volatile, rapidly changing data. This dynamic balancing act is the hallmark of a mature, cost-optimized AI operation.
The Executive Action Plan
Strategic Trajectory
- Evolve toward ‘Self-Optimizing Memory’ systems for autonomous pipeline management.
- Implement autonomous pruning and re-ranking of internal knowledge bases.
- Integrate user feedback loops and data freshness scores into the RAG lifecycle.
- Transition to ‘Long-Context RAG’ utilizing 2M+ token windows for native data handling.
- Eliminate complex chunking strategies in favor of direct synthesis of massive corporate archives.
- Optimize for single-step inference across entire datasets to improve insight depth.
The next evolutionary leap is the Self-Optimizing Memory system. Forward-thinking businesses are preparing for RAG pipelines that autonomously prune, re-rank, and update their own internal knowledge bases. This self-healing architecture will be driven entirely by automated user feedback loops and dynamic data freshness scores.
This means the AI will learn which documents yield the best answers and naturally deprioritize outdated or conflicting information. Simultaneously, we are moving rapidly toward Long-Context RAG deployments. Models boasting massive token windows can now handle proprietary datasets natively in memory.
This expanded context window eliminates the need for complex, error-prone chunking strategies. It allows for the deeper synthesis of entire corporate archives in a single inference step. The result is a more holistic, nuanced understanding of enterprise data that was previously impossible to achieve.
Conclusion: The Verifiable Future
The integration of custom data via RAG has moved from an experimental luxury to a fundamental pillar of corporate survival. Those who master the hybrid stack and vector infrastructure will build unassailable moats of proprietary intelligence. The future belongs to organizations that can reason over their data with absolute, verifiable certainty.
As AI continues to disrupt traditional business models, the ability to inject real-time context into language models will separate industry leaders from the obsolete. The technology is here, the capital is deployed, and the architecture is proven.
Navigating the intersection of technology, capital, and market psychology requires a sharp strategy. To future-proof your business architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is the “Parametric Freeze” in generative AI models?
The Parametric Freeze is the inherent limitation where large language models (LLMs) cannot access information beyond their static training cutoff dates. RAG (Retrieval-Augmented Generation) resolves this by acting as a cognitive bridge, fetching live data at the moment of inference to provide real-time corporate memory.
How does RAG architecture reduce AI hallucination rates?
According to 2026 data from Synvestable, RAG reduces LLM hallucination rates by 70% to 90%. By grounding every AI response in traceable source documents, RAG ensures outputs are based on verifiable reality rather than statistical guessing.
What is the 14-million-query inflection point for AI scaling?
The 14-million-query inflection point is the threshold where the token-heavy operating costs of RAG retrieval exceed the amortized capital expenditure of fine-tuning a specialized model. At this volume, organizations should bake high-frequency knowledge directly into model weights to optimize margins.
How do Agentic RAG and GraphRAG differ from traditional semantic search?
Traditional RAG fetches text chunks based on keywords, while Agentic RAG and GraphRAG use autonomous agents and knowledge graphs to perform multi-hop reasoning. This allows AI to synthesize insights by connecting dots across siloed data lakes, moving from simple retrieval to deep knowledge synthesis.
What are the benefits of a Hybrid AI Stack for enterprise architecture?
A Hybrid Stack combines small, high-speed fine-tuned models for domain logic with RAG as a dynamic memory module for volatile facts. This dual-layered approach achieves sub-second query responses, minimizes hallucinations, and reduces reliance on expensive proprietary APIs.
What is the projected market size for Vector Databases in 2026?
The global vector database market is projected to reach $3.73 billion by 2026. This growth is driven by enterprise demand for high-dimensional data retrieval and the massive shift toward embedding task-specific AI agents into 40% of all business applications.