Key Points
- Log-Level Analysis: Track specific AI bots like OAI-SearchBot to map ingested URLs for real-time RAG synthesis.
- Semantic Identifiers: Utilize vector embeddings and text fragments to align with generative engine data extraction.
- Attribution Parity: Compare GA4 custom dimensions against GSC Search Appearance data to illuminate the dark funnel.
Table of Contents
The AI Search Context
By May 2026, BrightEdge Research reported that 74 percent of all health and finance queries feature a primary AI Overview. These generative citation cards receive three times the brand-lift score of traditional search results.
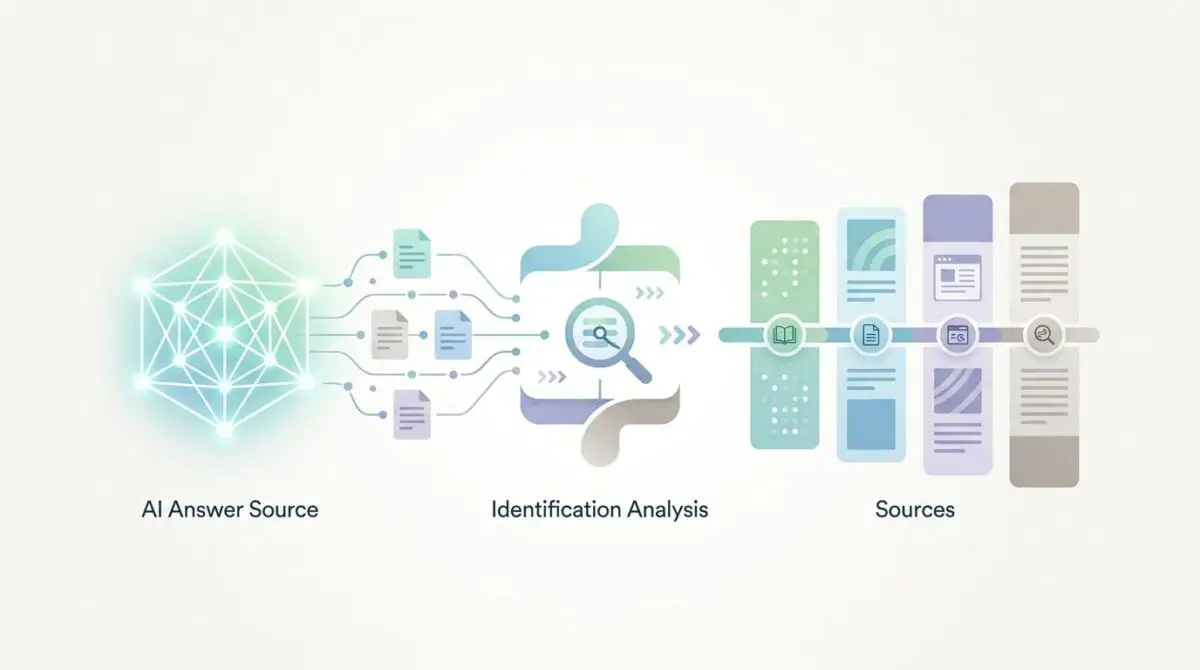
Identifying which pages power these AI answers involves tracking invisible referrals. Generative engines like SearchGPT and Google AI Overviews synthesize your content into direct responses using advanced Retrieval-Augmented Generation.
Unlike traditional blue links, these AI systems pull specific knowledge chunks from your site without requiring a direct user click. This paradigm shift renders standard session tracking obsolete for measuring true digital influence.
Identifying these source pages is critical for maintaining topical authority in a generative-first landscape. You must ensure your brand remains a primary node in the latent space of major large language models.
Failure to track these citations results in a massive dark funnel. High-value content is consumed by LLMs but attributed to zero-click sessions, leaving marketing teams blind to actual performance metrics.
In the current GEO landscape, visibility within AI Overviews is the primary driver of brand trust. If your pages are powering the answer but you are not monitoring which ones, you cannot optimize your strategy.
You need this data to accelerate the citation velocity required to outrank competitors in the generative layer. This impact extends to RAG-based systems where your content serves as the ground truth for AI-driven decisions.
Core Architecture and Pillars
Core Architecture & Pillars
Log-Level User-Agent Analysis
Modern AI engines utilize specific bots like ‘OAI-SearchBot’ and ‘Google-InspectionTool’ to crawl for real-time RAG synthesis. By analyzing server logs for high-frequency hits on specific JSON or HTML fragments by these agents, engineers can map which URLs are being ingested for immediate answer generation.
Referrer Header Identification
Generative engines have standardized specific referral strings (e.g., ‘generative.google.com’ or ‘searchgpt.com’) to distinguish AI-synthesized traffic from standard organic search. Tracking these via custom dimensions allows for the isolation of ‘AI-Driven Sessions’.
Semantic Citation Matching
This involves using vector embeddings to compare your page content against the output of an AI Overview. If the cosine similarity score between a page’s fragment and an AI answer is above 0.85, that page is mathematically likely to be a source for the model.
Search Console ‘Product Snippet’ Overlays
Google Search Console now categorizes AI Overview citations under the ‘Search Appearance’ filter. Pages appearing here are being used as ‘Source Cards’ within the generative module, indicating they are powering the current response.
Optimizing your citation velocity requires a deep understanding of how generative bots interact with your server architecture. Modern AI engines utilize highly specific crawlers to fetch real-time data for RAG synthesis.
Engineers can precisely map which URLs are being ingested for immediate answer generation by analyzing server logs. This log-level user-agent analysis forms the absolute foundation of effective citation attribution mapping.
Analyzing Log-Level User Agents
In environments like WordPress, this requires moving far beyond standard front-end analytics. You must utilize server-side logging or specialized plugins to filter for active AI bots.
Traditional JavaScript-based tracking often fails to fire entirely when an AI engine scrapes the content. You need raw Nginx or Apache log data to see the exact hit frequency and payload size.
By filtering your access logs for agents like PerplexityBot, you can isolate exactly which nodes of your site are feeding the machine. This reveals the hidden pathways of generative discovery.
Tracking Referrer Headers
Generative engines have standardized specific referral strings to distinguish AI-synthesized traffic from standard organic clicks. Tracking these via custom dimensions isolates your true AI-driven sessions.
You must configure custom definitions to capture the document referrer property specifically for LLM subdomains. These critical data points are often filtered out by default spam and bot filters in legacy analytics setups.
Isolating traffic from searchgpt.com or generative.google.com allows you to measure the downstream conversion rate of AI citations. This proves the direct ROI of your Generative Engine Optimization efforts.
Matching Semantic Citations
Semantic citation matching involves using vector embeddings to compare your page content directly against AI Overview outputs. A cosine similarity score above 0.85 indicates your page is mathematically highly likely to be a source.
Recent studies found that LLMs prioritize sources that utilize semantic fragment identifiers within their URLs. The text fragment syntax allows the model to pinpoint exact data points for RAG synthesis.
This directly aligns with studies showing over 80% of AI citations are pulled from deep pages where highly granular data resides.
By structuring your content to support these fragment identifiers, you dramatically increase your inclusion rate. Semantic matching provides the mathematical proof that your optimization is working.
Decoding Search Console Overlays
Google Search Console now categorizes AI Overview citations under the Search Appearance filter. Pages appearing here act as source cards within the generative module.
Site owners must monitor the raw export data from GSC closely. Visual interfaces often aggregate these into broader rich results, requiring strict regex filters to isolate AI attribution.
This level of granular tracking is especially important given the recent BrightEdge data tracking AI Overview growth across healthcare and finance sectors.
When you map GSC impression data against your server log crawl rates, a complete picture emerges. You can finally see the end-to-end lifecycle of an AI citation.
The Execution Roadmap
Implementation Roadmap
Isolate AI Bot Traffic in Server Logs
Access your server logs (CPanel or Nginx) and filter for ‘OAI-SearchBot’, ‘PerplexityBot’, and ‘Google-InspectionTool’. Map the most crawled URLs to your ‘AI-Power’ list.
Configure GA4 Custom Dimensions
In Google Analytics 4, create a User-scoped Custom Dimension for ‘AI_Referrer’. Use a GTM tag to capture ‘document.referrer’ specifically when it contains ‘ai’, ‘gpt’, or ‘gemini’.
Audit GSC Search Appearance
Open Google Search Console > Performance > Search Appearance. Filter for ‘AI Overviews’ (the 2026 updated label for SGE) to see exactly which URLs are generating ‘Source Card’ impressions.
Implement Citation Schema
Add ‘isBasedOn’ and ‘citation’ properties to your JSON-LD schema. This forces a feedback loop that makes it easier for AI engines to credit your URL when they parse your data.
Isolating AI bot traffic in your server logs is the critical first step in this roadmap. Access your server logs and filter relentlessly for agents like OAI-SearchBot.
Mapping the most crawled URLs gives you a baseline AI-power list. You can then move to configuring custom dimensions in Google Analytics 4 to catch the human traffic that follows.
Create a user-scoped custom dimension for AI referrers using Google Tag Manager. Capture the referrer string specifically when it contains AI or GPT identifiers to clean your data streams.
Auditing your GSC search appearance provides the final layer of search visibility. Filter for AI Overviews to see exactly which URLs generate source card impressions.
Finally, implement robust citation schema across your architecture. Adding isBasedOn properties to your JSON-LD forces a feedback loop that makes it easier for AI engines to credit your URL.
Technical Implementation
Implementing a robust tracking system requires server-side or header-level modifications. The following code snippet demonstrates how to capture AI referrers natively in a WordPress environment.
This script hooks directly into the header to check the HTTP referer for known generative engine domains. It bypasses standard front-end blockers by evaluating the server variable before page render.
Once an AI domain is detected, it fires a custom Google Analytics event to log the citation traffic. This bridges the gap between invisible LLM ingestion and measurable user sessions.
add_action('wp_head', function() {
if (isset($_SERVER['HTTP_REFERER'])) {
$referrer = $_SERVER['HTTP_REFERER'];
if (strpos($referrer, 'searchgpt.com') !== false || strpos($referrer, 'gemini.google.com') !== false) {
echo "<script>gtag('event', 'ai_citation_traffic', {'source_engine': '" . esc_js($referrer) . "'});</script>";
}
}
});Deploy this code via a custom plugin or your child theme’s functions file. Ensure you test the output using a header modification extension to simulate traffic from searchgpt.com.
Validation and Future-Proofing
Validation & Monitoring
- Query top keywords using Gemini Live Inspector or the OpenAI Attribution API.
- Verify domain presence in the ‘citations’ metadata field of AI outputs.
- Compare GSC ‘AI Overview’ clicks against internal GA4 ‘AI_Referrer’ dimensions.
- Audit attribution parity regularly to ensure accurate GEO performance mapping.
Validating your citation attribution mapping requires continuous querying of your top entities. Use tools like the Gemini Live Inspector to check for your domain in the raw metadata.
Regularly compare your GSC AI Overview clicks against your internal GA4 custom dimensions. This ensures attribution parity across your entire measurement stack.
Auditing this data regularly is essential to maintain accurate GEO performance mapping. As LLMs evolve, your tracking architecture must adapt to new referral strings and shifting bot behaviors.
You must treat AI search engines as dynamic, living databases rather than static indexes. Continuous validation ensures your content remains the preferred ground truth for generative models.
Navigating the intersection of traditional SEO and Generative Engine Optimization requires a precise architecture. To future-proof your enterprise stack for AI Overviews and LLM discovery, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
How do I track which pages power AI Overviews?
Tracking AI source pages involves analyzing server logs for AI-specific user-agents and configuring custom dimensions in analytics to capture referral headers from generative engines like searchgpt.com and generative.google.com.
What are the primary AI search bot user-agents to monitor?
To identify ingestion for RAG synthesis, monitor server logs for user-agents such as ‘OAI-SearchBot’, ‘Google-InspectionTool’, and ‘PerplexityBot’, which are used to fetch real-time data for generative models.
What is semantic citation matching in GEO?
Semantic citation matching uses vector embeddings to compare your content against AI engine outputs. A cosine similarity score of 0.85 or higher indicates your page is mathematically likely to be a source for that specific AI answer.
Where can I find AI citation data in Google Search Console?
You can find this data under the ‘Performance’ report by applying a ‘Search Appearance’ filter for ‘AI Overviews’. This reveals which URLs are being utilized as source cards within Google’s generative modules.
What schema markup helps with AI engine attribution?
Implementing JSON-LD schema with ‘isBasedOn’ and ‘citation’ properties establishes a formal feedback loop, making it easier for large language models to attribute and credit your content during the synthesis process.
Why is log-level analysis critical for tracking AI citations?
Many AI engines scrape content at the server level without firing traditional JavaScript tracking. Log-level analysis allows engineers to see raw hit frequency and payload sizes from bots that would otherwise remain invisible in front-end analytics.