Key Points
- Federated Identity Resolution: Consolidating brand presence across LLMs requires strict mapping to external ontologies using persistent identifiers to prevent entity splitting.
- GraphRAG Architecture Alignment: Establishing semantic relationship triples connects your brand to core industry competencies, drastically improving factual accuracy in AI overviews.
- Extractable Answer Formatting: Restructuring content into high-density, front-loaded answers ensures AI models can directly quote your expertise without context loss.
Table of Contents
The AI Search Context
Industry data indicates a massive behavioral pivot toward AI chatbots and virtual agents for direct information retrieval. This transition fundamentally alters the mechanics of digital visibility across the modern web.
Brands can no longer rely on lexical keyword matching or traditional link equity to secure organic traffic. Generative Engine Optimization has replaced traditional search engine optimization as the primary discipline for digital discovery.
Entity Authority in 2026 has emerged as the definitive metric of brand credibility within Large Language Model environments. Search engines like SearchGPT and Google AI Overviews now prioritize verified nodes in a Knowledge Graph over unlinked, unstructured text.
This paradigm shift marks the absolute obsolescence of traditional Domain Authority metrics. Entity Authority relies instead on persistent identification and semantic triples to prove a brand’s existence and expertise to complex retrieval systems.
The impact of this architectural shift is profound and immediate. By mid-2026, AI-driven zero-click searches account for nearly half of all informational queries.
This reality makes entity-first optimization the only viable method to remain visible in the synthesis layer of generative engines. Brands that successfully establish themselves as authoritative nodes in Knowledge Graphs see a 14.2% higher conversion rate from AI Overview citations compared to traditional organic traffic.
Users inherently treat AI-curated summaries as pre-vetted recommendations, bypassing traditional evaluation phases.
Understanding the underlying mechanics of these generative engines is non-negotiable for modern technical architects. Large Language Models do not read web pages in real-time; they retrieve context from highly structured vector databases and knowledge graphs.
If your brand is not explicitly defined as a distinct entity within these data structures, the model cannot synthesize your expertise. The failure to architect your entity presence guarantees your exclusion from the AI-generated answers that now dominate the search landscape.
Core Architecture & Pillars
Core Architecture & Pillars
Federated Identity Resolution
LLMs use federated identity to disambiguate brands by cross-referencing persistent identifiers (PIDs). At the server level, this requires consistent ‘sameAs’ mapping to external ontologies like Wikidata, DBpedia, and official business registries to ensure the AI’s internal Knowledge Vault resolves to a single, unique entity ID.
Semantic Relationship Triples
Modern RAG (Retrieval-Augmented Generation) systems utilize ‘GraphRAG’ architectures to navigate relationships via Subject-Predicate-Object triples. Establishing authority requires explicit schema declarations that link the brand (Subject) to its primary industry (Predicate: knowsAbout) and its expert founders (Object: founder).
Citation Graph Density
AI models assess authority by the density and quality of brand mentions within their grounding corpus. This is not about backlinks, but ‘co-occurrence’ with high-authority concepts on platforms LLMs trust, such as Reddit, GitHub, and industry-specific peer-reviewed databases.
E-E-A-T Signal Hardening
The 2026 Google ‘Entity-First’ updates explicitly look for cryptographically signed or verifiable credentials (VCs) in schema markup. This involves linking ‘Person’ schema for authors to verifiable credentials like professional licenses or academic IDs to confirm the ‘Expertise’ component of E-E-A-T.
To master Generative Engine Optimization, we must dissect the underlying data structures that power AI retrieval systems. These four pillars represent the foundational architecture required to translate flat HTML into machine-readable knowledge.
Federated Identity Resolution
Large Language Models process billions of parameters, making disambiguation a critical computational challenge. Federated identity resolution allows these models to cross-reference persistent identifiers across the web.
Without a singular, verified identity, AI engines suffer from entity splitting. This occurs when a brand is viewed as multiple distinct and less-trusted objects, diluting its overall authority score.
At the server level, establishing this identity requires consistent sameAs mapping to external ontologies. Connecting your digital properties to Wikidata, DBpedia, and official business registries ensures the AI’s internal Knowledge Vault resolves to a single entity ID.
In standard CMS environments like WordPress, identity signals are often fragmented across multiple plugins. Consolidating these signals into a unified schema payload is the first step toward true entity resolution.
Semantic Relationship Triples
Semantic triples form the connective tissue of modern retrieval systems. Modern RAG systems utilize advanced GraphRAG architectures to navigate relationships via Subject-Predicate-Object triples.
Establishing authority requires explicit schema declarations that link the brand to its primary industry and its expert founders.
Integrating Knowledge Graphs into Retrieval-Augmented Generation (RAG) improves LLM factual accuracy by 54.2% on average by preventing models from fabricating non-existent semantic connections. This mid-content insight highlights why flat HTML content is no longer sufficient.
Plugins like WordLift or custom JSON-LD scripts are required to bridge the gap between human-readable text and the structured relationship data that AI crawlers prioritize.
Citation Graph Density
Citation Graph Density moves beyond the archaic concept of PageRank and traditional link building. AI models assess authority by the density and quality of brand mentions within their grounding corpus.
This evaluation focuses on co-occurrence with high-authority concepts rather than hyperlinked text. Platforms that LLMs inherently trust, such as Reddit, GitHub, and peer-reviewed databases, serve as the primary validation layers.
The urgency of establishing this density cannot be overstated. As industry analysts have confirmed, search engine volume is projected to decline 25% by the end of 2026.
Brands failing to establish Knowledge Graph dominance will simply disappear from the synthesis layer. Furthermore, excessive AI-generated content on a site without external third-party verification creates a hallucination loop.
This loop causes AI engines to drastically lower the brand’s entity confidence score.
E-E-A-T Signal Hardening
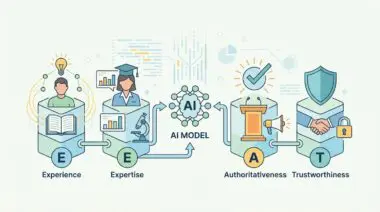
The concept of Experience, Expertise, Authoritativeness, and Trustworthiness has evolved into a highly technical, programmatic requirement. The 2026 Google Entity-First updates explicitly look for cryptographically signed or verifiable credentials in schema markup.
This evolution transforms subjective trust into objective, verifiable data points. Hardening your signals involves linking Person schema for authors directly to verifiable credentials.
Professional licenses, academic IDs, and verified social graphs confirm the Expertise component of E-E-A-T. Standard CMS environments frequently fail this requirement by using generic Admin tags or unlinked author bios.
This effectively anonymizes the expertise and disqualifies the content from lucrative AI Overview citations.
The Execution Roadmap
Implementation Roadmap
Entity Mapping and Disambiguation Audit
Identify your brand’s unique Wikidata or Crunchbase ID. If one does not exist, use an official business registration number (e.g., DUNS) as your primary identifier in the ‘identifier’ property of your Organization schema.
Advanced JSON-LD 2.0 Implementation
Deploy a consolidated ‘@graph’ JSON-LD block in the site head. Use the ‘sameAs’ array to link your homepage to Wikidata, LinkedIn, and Crunchbase. Add ‘knowsAbout’ properties listing your top 3-5 core industry competencies.
Verification via GraphRAG Anchors
Secure brand mentions on ‘seed sites’ that AI models use for verification. Update your official social profiles and Wikipedia/Wikidata entries to ensure the metadata (Name, CEO, Headquarters) perfectly matches your site’s schema to prevent conflict signals.
AI-Inverted Pyramid Content Structuring
Rewrite primary service and pillar pages using the 2026 ‘Extractable Answer’ format: ensure the first 60 words under every H2 provide a standalone, fact-dense answer that an AI can quote directly without requiring broader context.
Executing a successful Generative Engine Optimization strategy requires a methodical, engineering-led approach. The roadmap to Entity Authority is built on strict data structuring and continuous validation.
Each phase of this implementation roadmap addresses specific vulnerabilities in how LLMs parse and synthesize brand information.
Entity Mapping and Disambiguation Audit
The foundation of your architecture begins with a rigorous Entity Mapping and Disambiguation Audit. You must identify your brand’s unique Wikidata or Crunchbase ID to serve as your primary anchor.
If a public ontology entry does not exist, leveraging an official business registration number like a DUNS identifier becomes mandatory. This identifier must be injected directly into the identifier property of your Organization schema.
Conducting this audit requires querying public knowledge bases using SPARQL or similar graph query languages. You must identify any conflicting entities that share your brand name or operational footprint.
Resolving these conflicts prior to schema deployment prevents the LLM from merging your authority signals with an unrelated entity.
Advanced JSON-LD 2.0 Implementation
Deploying Advanced JSON-LD 2.0 is the most critical technical step in this roadmap. You must deploy a consolidated @graph JSON-LD block in the site head to prevent parser fragmentation.
Utilizing the sameAs array explicitly links your canonical homepage to trusted external ontologies, reinforcing your federated identity.
Furthermore, adding the knowsAbout property is essential for semantic relevance. This property must list your top core industry competencies, effectively mapping your brand to specific vector embeddings within the LLM.
This explicit declaration prevents the AI from guessing your expertise based on ambiguous lexical patterns.
Verification via GraphRAG Anchors
Verification via GraphRAG Anchors ensures that your internal schema declarations are corroborated by external data sources. You must secure brand mentions on highly trusted seed sites that AI models use for baseline verification.
These platforms include authoritative industry directories, GitHub repositories, and verified social graphs.
Updating your official social profiles and Wikidata entries is crucial. You must ensure that the metadata across all external platforms perfectly matches your site’s internal schema.
Any discrepancy in your CEO’s name, headquarters location, or founding date will trigger conflict signals, severely downgrading your Entity Authority.
AI-Inverted Pyramid Content Structuring
The final phase involves AI-Inverted Pyramid Content Structuring. You must rewrite primary service and pillar pages using the 2026 Extractable Answer format.
This format ensures maximum machine readability and aligns with the attention mechanisms of modern transformer models.
Ensure the first 60 words under every H2 provide a standalone, fact-dense answer. An AI must be able to quote this section directly without requiring broader context to understand the premise.
This high-density, front-loaded approach minimizes token waste and maximizes the probability of direct extraction into an AI Overview.
Technical Implementation
Bridging the gap between conceptual Entity Authority and machine-readable reality requires precise schema engineering. The following JSON-LD payload demonstrates a consolidated graph architecture optimized for Generative Engine Optimization.
This structure utilizes the sameAs property for disambiguation and the knowsAbout predicate for semantic relevance.
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Organization",
"@id": "https://brand.com/#org",
"name": "Your Brand",
"url": "https://brand.com",
"sameAs": [
"https://www.wikidata.org/wiki/Q12345",
"https://www.linkedin.com/company/yourbrand"
],
"knowsAbout": [
"Generative Engine Optimization",
"Entity Search"
],
"founder": {
"@type": "Person",
"name": "Expert Name",
"sameAs": "https://www.linkedin.com/in/expert"
}
}
]
}Deploy this payload globally across your application architecture, ensuring it renders server-side before client-side hydration occurs. Ensure that the @id nodes resolve consistently across all subdomains to prevent entity fragmentation within the AI’s grounding corpus.
The use of the #org fragment identifier establishes a persistent URI that internal pages can reference via the publisher property.
This explicit structuring forces the LLM crawler to recognize the relationship between the organization, its founders, and its core competencies.
By wrapping the entities in a single @graph array, you eliminate the risk of the parser treating the founder and the organization as disconnected objects. This is the exact technical standard required by 2026 AI retrieval systems.
Validation & Future-Proofing
Validation & Monitoring
- Run comprehensive technical audits via the Google Rich Results Test to ensure the @graph JSON-LD block parses without structural errors.
- Benchmark Share of Model (SoM) across leading LLMs using high-precision AI-specific analytics tools like Perplexity Sonar.
- Audit Google Search Console’s ‘Search Appearance’ filter to track instances where Organization or FAQ schema triggers AI Overview citations.
Validation is a continuous, iterative process in the era of Generative Engine Optimization. Running comprehensive technical audits via the Google Rich Results Test ensures your @graph JSON-LD block parses without structural errors.
This validation is the absolute baseline for entry into the AI’s Knowledge Vault. Any syntax error will result in the entire payload being discarded by the ingestion engine.
Benchmarking your Share of Model across leading LLMs provides actionable intelligence on your true Entity Authority. Utilizing high-precision AI-specific analytics tools like Perplexity Sonar allows you to track entity resonance in real-time.
This metric reveals how frequently your brand is synthesized in response to non-branded industry queries.
Auditing Google Search Console’s Search Appearance filter remains critical for tracking traditional and AI Overview citations. As LLMs evolve and integrate deeper into the operating system level, maintaining strict adherence to entity-first optimization principles will safeguard your digital presence.
Continuous monitoring of your semantic triples ensures your brand remains the definitive answer in a zero-click world.
Navigating the intersection of traditional SEO and Generative Engine Optimization requires a precise architecture. To future-proof your enterprise stack for AI Overviews and LLM discovery, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is Generative Engine Optimization (GEO) and why is it replacing SEO?
Generative Engine Optimization (GEO) is the technical discipline of preparing digital assets for discovery and synthesis by AI models and search engines like SearchGPT. Unlike traditional SEO, which relies on keyword matching and link equity, GEO focuses on machine-readable knowledge structures and entity clarity to ensure a brand is correctly prioritized in AI-generated overviews.
What is Entity Authority and why is it superior to Domain Authority?
Entity Authority has emerged as the definitive metric of brand credibility in LLM environments. While Domain Authority measures backlink strength, Entity Authority relies on persistent identification and semantic triples to prove a brand’s existence and expertise. AI engines prioritize verified nodes in Knowledge Graphs over unstructured text, making entity-first signals the primary driver of visibility.
How do Semantic Relationship Triples and GraphRAG improve AI accuracy?
Semantic triples (Subject-Predicate-Object) form the basis of GraphRAG architectures. By defining explicit relationships—such as linking a brand to its industry and its expert founders via schema—companies can increase LLM factual accuracy by up to 54.2%. This prevents models from hallucinating non-existent connections and ensures the AI correctly synthesizes the brand’s expertise.
What is Federated Identity Resolution for brands?
Federated Identity Resolution uses persistent identifiers (PIDs) like Wikidata IDs or DUNS numbers to disambiguate a brand across the web. This prevents ‘entity splitting,’ where AI engines view a brand as multiple distinct and less-trusted objects. Resolving a brand to a single, unique entity ID ensures that all authority signals are consolidated within the AI’s internal Knowledge Vault.
How should content be structured for AI-driven zero-click searches?
Content should utilize the AI-Inverted Pyramid format, specifically the ‘Extractable Answer’ structure. This requires the first 60 words under every H2 heading to provide a standalone, fact-dense answer that can be quoted directly by an AI without requiring broader context. This high-density approach maximizes the probability of a brand appearing in AI Overview citations.
What is E-E-A-T signal hardening in the context of 2026 AI search?
E-E-A-T signal hardening involves transforming subjective trust signals into verifiable technical data. This is achieved by using schema markup to link authors to cryptographically signed credentials, such as professional licenses or academic IDs. This objective verification allows AI engines to confirm the ‘Expertise’ component of E-E-A-T, making the content more likely to be used as a pre-vetted recommendation.