Key Points
- Definition-First Extraction: Structuring the first 40-60 words of a section as a standalone fact-unit prevents a 50% drop in LLM citation rates.
- Agentic Semantic Chunking: Modern RAG pipelines use models like Claude 4.6 to dynamically set context boundaries, requiring content to be modular and self-contained.
- Cross-Encoder Precision: Implementing cross-encoder re-ranking on technical content yields a 42% lift in AI citation probability by evaluating semantic relationships simultaneously.
Table of Contents
The Zero-Click Collapse
Traditional page-level ranking is dead, swallowed whole by the zero-click information sink.
By mid-2026, AI Overviews and conversational agents will handle nearly 50% of informational queries natively. Brands are watching their organic traffic evaporate because their content was built for crawlers, not synthesizers.
The new battleground is not about getting a page indexed. It is about structuring content to be cited at the fragment level, where algorithms slice and serve your data directly to the user.
To survive this shift, organizations must pivot their AI content creation strategies toward Generative Engine Optimization (GEO) and Machine-Parsable Fact Density. This architectural approach ensures your brand’s data is actively extracted and prioritized by LLMs, rather than ignored as unstructured noise.
The Mathematics of Citation Yield

The financial impact of AI visibility is staggering. A 2026 industry report from Column Five revealed that 90% of high-intent buyers now prefer clicking on sources cited within AI Overviews over traditional organic blue links.
This behavioral shift means that if your content is not surfacing as a primary citation, you are effectively invisible to bottom-of-funnel users. Adapting to this requires studying official industry guidelines on optimizing for generative AI features to understand how engines prioritize structural data over traditional prose.
Furthermore, the technical mechanics of retrieval heavily dictate your citation probability. According to the 2026 RAG Performance Landscape report, implementing cross-encoder re-ranking on technical content increases the probability of being selected as an AI citation by 42%.
This precision lift occurs because cross-encoders evaluate the semantic relationship between the query and the document simultaneously. For a deeper dive into the architecture, explore improving RAG retrieval precision with cross-encoder re-ranking to see how microservices handle this computational load.
Extracting Value via Search as Code
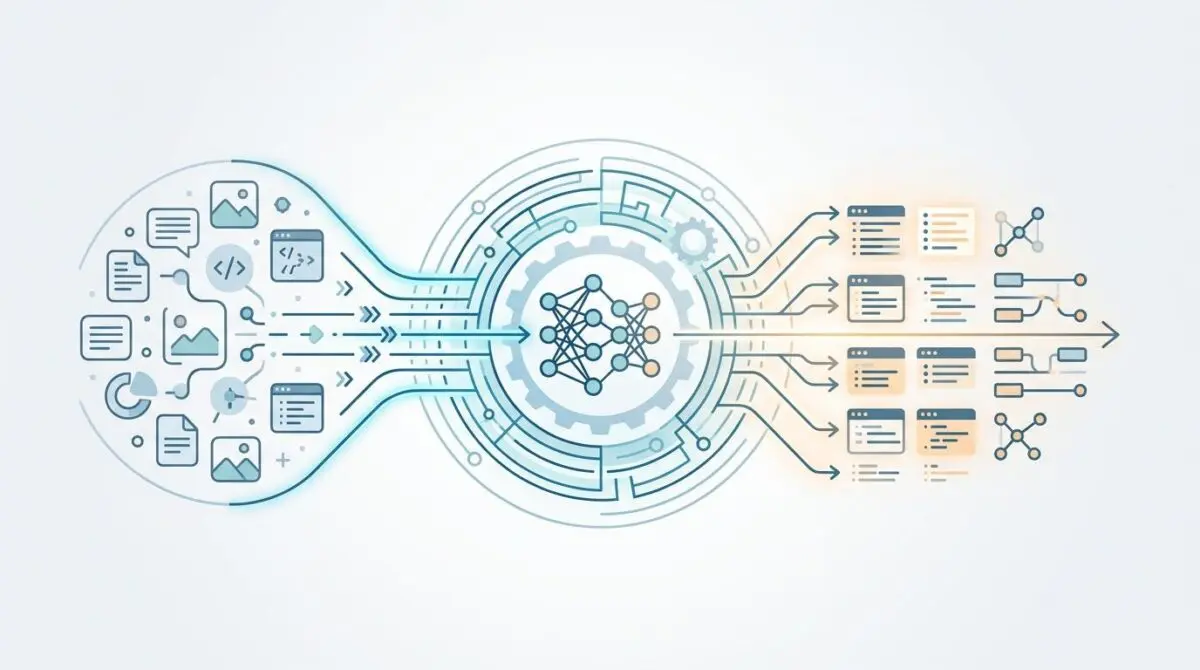
Brands are experiencing a massive drop in traditional organic click-through rates for informational queries. Their content lacks the structural hooks required for AI engines to extract and cite them as primary sources.
Google’s Gemini 3 and Perplexity’s Search as Code SDK prioritize definition-first prose and modular comparison tables. Direct extraction via API-led ingestion pipelines is the new standard.
Google’s Gemini 3.0 uses a technique called Definition-First Extraction. The model specifically scans for the first 40-60 words of a section to find a standalone fact-unit that can be repurposed in AI Overviews.
Content lacking this specific structure sees a 50% lower citation rate regardless of its traditional SEO ranking. The GenOptima AI Visibility Study confirms that front-loading machine-parsable facts is non-negotiable.
Agentic Chunking in RAG Pipelines
Standard HTML-heavy content often breaks during LLM ingestion. This leads to hallucinated omissions where key brand facts are skipped by AI agents.
The semantic relationship between entities is frequently lost during naive chunking. Modern RAG pipelines have moved away from fixed-size chunking to solve this exact bottleneck.
We are now in the era of Agentic Semantic Chunking. LLMs like Claude 4.6 dynamically determine context boundaries before vectorization in databases like Pinecone or Weaviate.
Content must be authored with clear, self-contained semantic boundaries to survive this ingestion process. If your paragraphs do not encapsulate complete thoughts, the vector database will shatter your context.
Building Source Authority Schemas
Websites without automated claim-verification schemas are being systematically de-prioritized by AI engines. These engines now treat citation-worthiness as the primary metric for top-of-funnel visibility.
SearchGPT and Google AI Overviews utilize Text Fragment Anchoring to verify claims against high-authority knowledge graphs. This is how they determine what data deserves to be surfaced to the user.
This system weighs first-party data and statistics three times higher for citation selection than standard prose. By structuring your AI content creation around verifiable, machine-parsable facts, you build an automated source authority pipeline.
Pre-Publish Hallucination Filters
Content with high hallucination risk is being blacklisted by Google’s core quality systems. This generic AI-generated fluff causes entire domains to lose up to 80% of their visibility within single-update cycles.
The 2026 Clean Content standard demands a rigorous, programmatic approach to accuracy. Brands can no longer afford to publish unverified AI outputs.
Engineering teams are now deploying automated pre-publish agents via OpenAI or Anthropic APIs. These agents perform cross-reference validation against live web indices.
This ensures near perfect factual accuracy before a page is even indexed. Machine-parsable fact density acts as an immune system against these algorithmic quality penalties.
The Search As Code Horizon
By 2027, the industry will pivot entirely to Search as Code. SEO will move from managing web pages to managing programmable search primitives.
Your content will serve as an execution layer for autonomous AI agents. These agents will not just read data, but use it to perform real-time transactions and decision-making on behalf of users.
Navigating the intersection of Generative Engine Optimization, AI Search architecture, and workflow automation requires a sharp strategy. To future-proof your brand’s visibility in LLMs and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is Generative Engine Optimization (GEO)?
Generative Engine Optimization (GEO) is a strategic approach to content architecture designed to maximize visibility within LLMs and AI Overviews. It prioritizes structuring data at the fragment level with high machine-parsable fact density, ensuring that AI synthesizers can easily extract and cite the information as a primary source.
How does the zero-click collapse affect traditional SEO?
The zero-click collapse refers to the shift where AI agents handle informational queries natively, reducing traditional organic traffic. To survive, brands must pivot from building content for crawlers to creating modular, synthesizer-ready data that can be surfaced directly within AI-generated responses.
What is Definition-First Extraction in AI Search?
Definition-First Extraction is a technique used by models like Gemini 3.0 to identify standalone fact-units within the first 40-60 words of a section. Content that lacks this specific front-loaded structure typically experiences a 50% lower citation rate in generative search features.
How does Agentic Semantic Chunking improve RAG accuracy?
Agentic Semantic Chunking replaces fixed-size chunking by using LLMs to dynamically identify context boundaries before data is stored in vector databases like Pinecone. This prevents the loss of semantic relationships between entities, reducing the risk of hallucinated omissions during the retrieval process.
Why is cross-encoder re-ranking important for technical citations?
Cross-encoder re-ranking increases the probability of being selected as an AI citation by 42% because it evaluates the semantic relationship between a query and a document simultaneously. This higher computational precision ensures technical content meets the strict retrieval standards of modern RAG pipelines.
What is the Search as Code horizon?
The Search as Code horizon represents a shift toward managing programmable search primitives where content acts as an execution layer for autonomous AI agents. By 2027, SEO will evolve from managing web visibility to enabling real-time transactions and decision-making via machine-readable data structures.