Key Points
- High-Concurrency Pipelines: Utilize n8n workflows to bridge OpenAI embeddings and the WordPress REST API for sub-second vector storage.
- Dynamic Link Sculpting: Cross-reference Search Console API click-through data with text-embedding-3-large semantic similarity scores.
- Real-Time Indexing: Trigger IndexNow and Google Indexing API pings via webhooks immediately after successful CMS post requests.
Table of Contents
- The Hidden Tax of the Latent Semantic Gap
- Quantifying Semantic Relevance and Workflow Velocity
- Architecting the Vector Pipeline via n8n
- Sculpting PageRank with Search Console Data
- Enriching Site Structures for RAG Crawlers
- Forcing Bot Discovery with Real-Time Indexing Pipelines
- The 2027 Horizon of Edge-Side Contextual Injection
The Hidden Tax of the Latent Semantic Gap
Every day your editorial team publishes new content, a silent tax is levied against your crawl budget and topical authority. This is the invisible cost of manual SEO execution within large-scale CMS architectures. High-authority legacy content remains entirely isolated from new programmatic pages because human interlinking simply cannot scale with daily publishing velocity.
This architectural failure creates what we call the latent semantic gap. Newly published nodes are starved of historical link equity, while legacy pages slowly lose their contextual relevance in the eyes of search engine crawlers. The resulting stagnant PageRank distribution deeply fragments your site’s overall topical authority.
The ultimate architectural solution to this bottleneck is Semantic Vector-Based Internal Link Orchestration. By transitioning from manual keyword matching to automated mathematical coordinate mapping, engineering teams can instantly bridge disparate content silos. This programmatic approach ensures that link equity flows dynamically to the exact URLs that require crawling and indexing.
Quantifying Semantic Relevance and Workflow Velocity
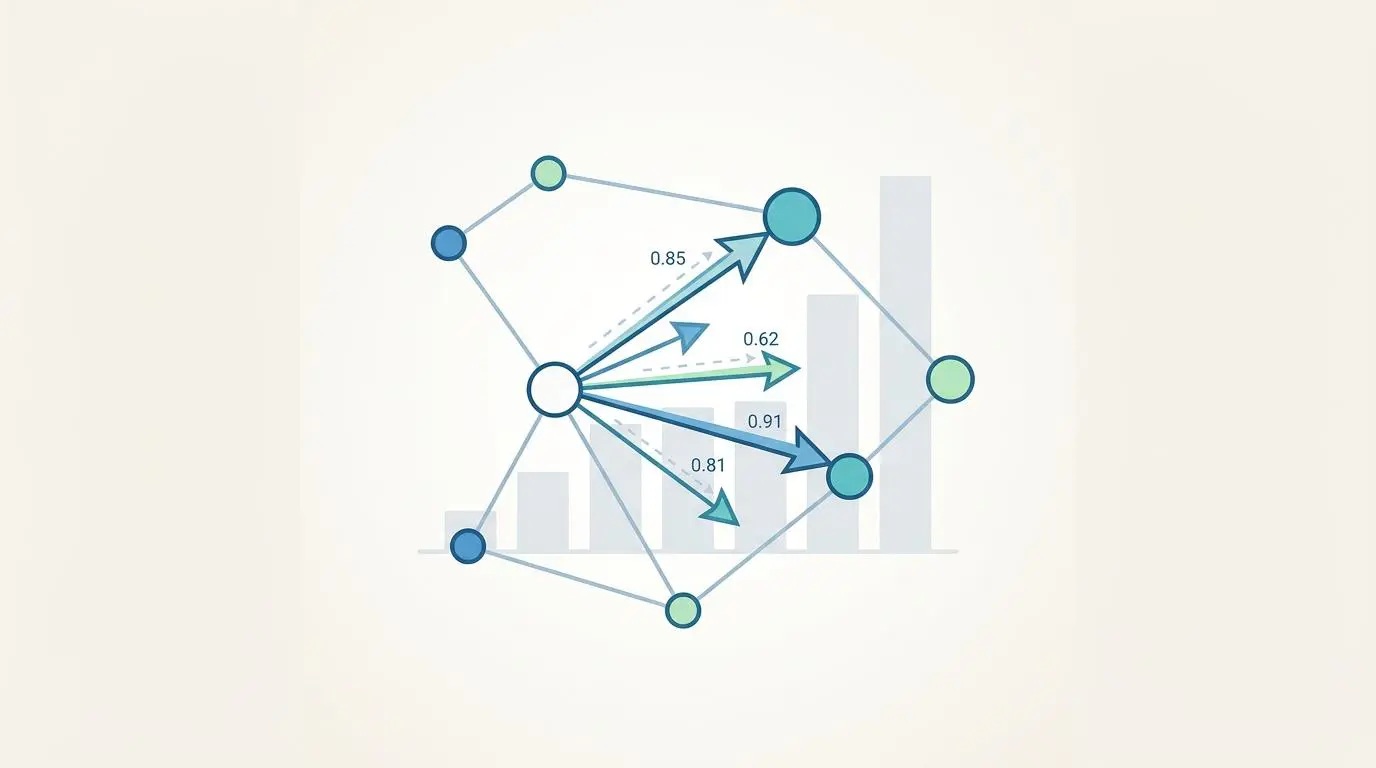
Transitioning to vector-based link orchestration requires a deep understanding of the underlying mathematical precision. A Q1 2026 benchmark by Search Engine Journal confirms that vector-based linking using text-embedding-3-large yields a staggering 92 percent relevance match. This completely eclipses the 44 percent accuracy rate of traditional TF-IDF keyword matching.
Legacy TF-IDF systems often force search engine bots into low-context crawl paths by matching superficial text strings rather than underlying entity relationships. Vector embeddings solve this by mapping content into a 3072-dimensional space where semantic distance dictates link placement. However, executing this high-dimensional math at scale requires serious computational efficiency to prevent database bottlenecks.
A 2026 technical audit by Ahrefs reveals a brilliant optimization for enterprise architectures. The audit shows that utilizing OpenAI’s Matryoshka Representation Learning allows SEOs to truncate text-embedding-3-large vectors from 3072 down to 256 dimensions. This aggressive truncation results in only a minimal two percent loss in link relevance.
More importantly, this dimensional reduction reduces n8n vector database storage costs by 85 percent for enterprise-scale deployments. By shrinking the payload size, the entire data pipeline becomes significantly lighter and more agile. This allows for higher concurrency rates without overwhelming the host server’s memory allocation.
Consequently, n8n Enterprise performance data from 2026 shows that multi-node semantic workflows now average under 450ms per transaction. When utilizing native vector nodes, the entire cycle of embedding extraction, cosine similarity comparison, and WordPress database updating executes with sub-second latency. This speed is critical for processing thousands of programmatic pages in real-time.
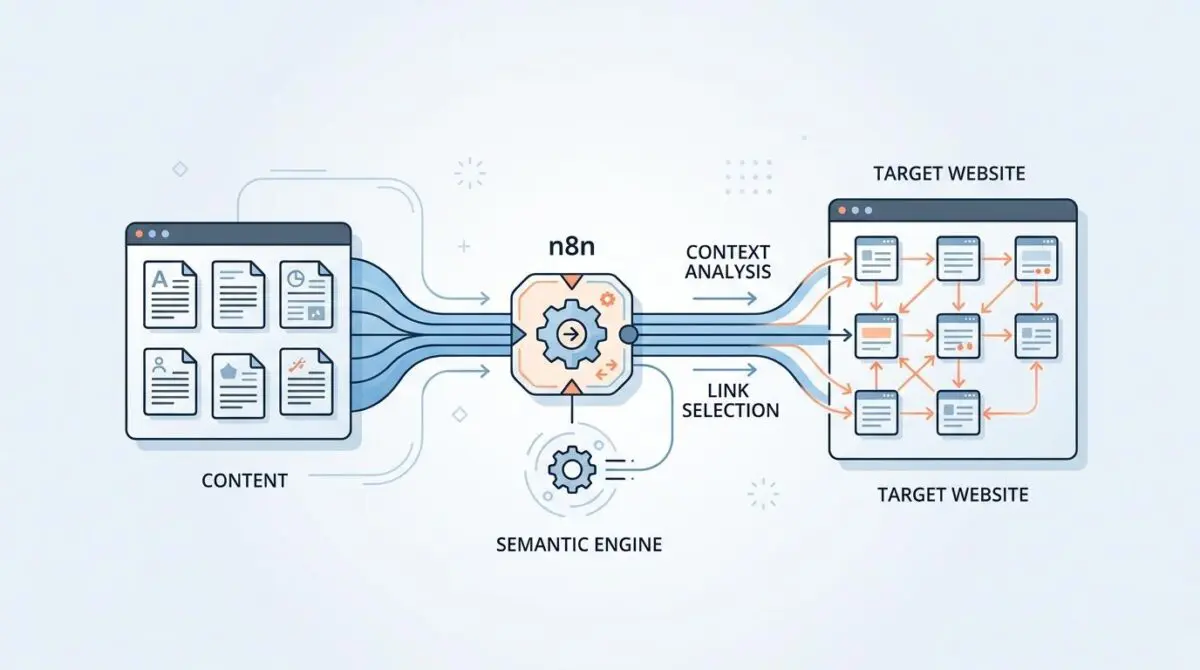
Architecting the Vector Pipeline via n8n
To bridge the OpenAI v4 Embeddings API and the WordPress REST API v2, engineering teams are deploying n8n v2.15 high-concurrency workflows. This integration serves as the central nervous system for automated semantic link injection. The workflow enables sub-second content fetching and rapid vector storage in dedicated Pinecone or Milvus nodes.
The automation completely bypasses the need for manual CMS intervention. As soon as a new post is published, a webhook triggers the n8n pipeline to extract the raw HTML and strip it down to plain text. This clean text is then passed to the OpenAI API, which transforms the narrative into a mathematical vector payload.
However, executing this orchestration at scale introduces significant real-world friction at the database level. Rate-limiting bottlenecks on the WordPress REST API frequently trigger 429 Too Many Requests errors. This catastrophic failure happens when n8n attempts to batch-update thousands of posts simultaneously, overwhelming the origin server’s connection limits.
To prevent server crashes and database lockouts, architects must implement sophisticated retry-logic within their HTTP request nodes. This involves programming the workflow to detect 429 status codes and temporarily pause the execution of that specific branch. Without this logic, the entire automation sequence will fail and drop valuable link injections.
Furthermore, teams must deploy exponential backoff strategies to stagger the payload delivery. By progressively increasing the wait time between failed request attempts, the system ensures stable link injection without triggering the host’s DDoS protection mechanisms.
Advanced engineering teams are even beginning to bypass the WordPress REST API entirely to avoid these rate limits. By deploying Cloudflare Workers HTMLRewriter, architects can intercept the HTML response and inject the vector-matched links directly at the edge. This hybrid approach significantly reduces the load on the origin server while maintaining high throughput for the vector database.
Sculpting PageRank with Search Console Data
True PageRank sculpting requires more than just semantic similarity between two documents. It demands a programmatic understanding of organic traffic potential and user engagement metrics. Automated systems can now calculate true link equity potential by cross-referencing Search Console API click-through data with semantic similarity scores.
This dual-layered approach fundamentally changes how internal links are prioritized within a large architecture. Instead of simply linking to the most topically relevant page, the algorithm prioritizes link injections toward high-converting nodes that already possess momentum in the SERPs. The text-embedding-3-large model ensures the connection makes contextual sense, while the Search Console data ensures the connection drives ROI.
Yet, programmatic linking carries the severe architectural risk of creating self-referential silos. These link-loops occur when automated scripts continuously cross-link the exact same cluster of high-similarity pages. Over time, this creates an isolated web of URLs that hoard PageRank but refuse to pass it downward.
When this happens, search engine bots become trapped in an endless crawl cycle within a singular topic cluster. They completely ignore deeper, newly published site layers because the automated internal links never point outward. This effectively wastes your daily crawl budget on URLs that have already been thoroughly indexed.
To mitigate this structural trap, n8n workflows must incorporate sophisticated decay algorithms and historical link-checkers. Before a new link is injected via the REST API, the system must query the database to ensure the target URL has not exceeded its inbound link quota. This logic forces the equity to flow downward into orphaned architecture, ensuring a balanced distribution of PageRank.
Enriching Site Structures for RAG Crawlers
Injecting semantic metadata via text-embedding-3-large prepares your site architecture for the next generation of generative search engines. By leveraging high-dimensional vectors, technical SEOs can optimize their content for AI-powered Search Generative Experiences. This structural enrichment ensures that generative engines deeply understand the contextual relationship between disparate entity clusters.
Large Language Model crawlers like GPTBot do not parse HTML the way traditional Googlebot does. They look for dense semantic clusters and mathematical relationships between concepts to train their retrieval-augmented generation models. By interlinking your site based on vector similarity, you are essentially feeding these LLM crawlers a pre-mapped knowledge graph.
The primary friction here is the exorbitant computational cost of maintaining this semantic map. Re-embedding an entire ten thousand page site every time a global semantic taxonomy update is deployed is financially unsustainable. The API overhead for processing that much text through OpenAI can easily exceed hundreds of dollars per run.
To maintain profitability and operational efficiency, engineering teams must build efficient delta-syncing protocols into their n8n pipelines. Instead of re-processing the entire WordPress database, the workflow must be designed to only trigger embedding updates for modified content. This requires querying the CMS for recent timestamp changes before initiating the API call.
By isolating the embedding process to only new or recently updated nodes, the computational cost plummets. The delta-syncing mechanism ensures that your vector database remains perfectly aligned with your live site architecture without wasting API credits. This leaner approach is mandatory for scaling semantic link orchestration across enterprise portfolios.
Forcing Bot Discovery with Real-Time Indexing Pipelines
A programmatic link injection is mathematically useless if search engine crawlers never actually discover it. Delayed bot-discovery often renders dynamic links ineffective for weeks at a time. This delay leaves valuable link equity stranded in the database, doing nothing to improve your organic rankings or crawl efficiency.
To combat this latency, automation architects are wiring real-time indexing pipelines directly into their n8n vector workflows. The process of injecting a link cannot end at the database level; it must extend all the way to the search engine’s indexing queue. Immediately after a semantic link injection is confirmed via a successful WordPress POST request, the system must take action.
The n8n workflow is configured to fire outbound webhooks the millisecond the CMS returns a 200 OK status code. These webhooks carry the exact URLs of the newly updated pages that now contain the injected internal links. The payload is formatted specifically for search engine ingestion protocols.
These automated webhooks trigger instant pings to both the IndexNow API and the Google Indexing API. By bypassing the traditional XML sitemap waiting period, this pipeline forces an immediate crawl of the updated nodes. The newly injected link equity is then recalculated by search engine algorithms in near real-time.
This rapid recalculation is the holy grail of programmatic SEO architecture. It ensures that the semantic relevance and PageRank you just orchestrated are immediately recognized and rewarded by the SERPs. Without this final indexing step, your sophisticated vector pipeline is essentially operating in a vacuum.
The 2027 Horizon of Edge-Side Contextual Injection
By 2027, the landscape of internal linking will move entirely beyond static database updates and traditional CMS limitations. The industry is rapidly shifting toward Edge-Side Contextual Injection, a paradigm that bypasses the WordPress database entirely. This evolution will fundamentally change how search engines experience site architecture.
In this future state, edge computing layers like Vercel Middleware will use lightweight, on-device models to dynamically inject links directly into the HTML stream. This injection will be executed based on real-time user intent and real-time crawl budget availability. The server will read the incoming bot’s user-agent and tailor the internal link structure perfectly to what that specific crawler needs to see.
Engineers are already experimenting with edge-native HTML rewriting APIs to parse and modify DOM elements on the fly. This happens before the page ever reaches the client or the search engine bot. By manipulating the HTML stream at the edge, sites can serve deeply personalized internal link graphs without ever writing a single line of code to the origin database.
This edge-native approach will completely eliminate database bloat and the 429 error bottlenecks that plague current REST API workflows. It ensures perfect contextual relevance for every unique bot session, maximizing crawl efficiency to its absolute limit. The era of static internal linking is ending, making way for fluid, mathematically perfect edge routing.
Navigating the intersection of technical SEO, programmatic architecture, and workflow automation requires a sharp strategy. To future-proof your site’s architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is the latent semantic gap in SEO architecture?
The latent semantic gap occurs when legacy content remains isolated from new programmatic pages because manual interlinking cannot scale with high publishing velocity. This creates a bottleneck where link equity is trapped, fragmenting topical authority and reducing crawl efficiency.
Why is vector-based internal linking superior to TF-IDF matching?
Vector-based linking uses high-dimensional embeddings like OpenAI’s text-embedding-3-large to map content relationships mathematically, achieving up to 92% relevance accuracy. In contrast, traditional TF-IDF relies on superficial keyword matching, which leads to low-context crawl paths and lower accuracy.
How does Matryoshka Representation Learning reduce SEO automation costs?
Matryoshka Representation Learning allows for truncating high-dimensional vectors (e.g., from 3072 to 256 dimensions) with minimal relevance loss. This optimization reduces vector database storage costs by up to 85% and lowers the computational load on automation pipelines like n8n.
How can architects prevent WordPress REST API 429 errors during link injection?
To avoid “Too Many Requests” errors, engineering teams should implement retry-logic and exponential backoff strategies within their n8n HTTP nodes. Alternatively, deploying Cloudflare Workers HTMLRewriter allows for link injection at the edge, bypassing origin server connection limits.
Why is the Indexing API critical for programmatic internal link strategies?
Programmatic links are only effective if discovered by crawlers. Real-time indexing pipelines using the IndexNow and Google Indexing APIs force search engines to crawl updated nodes immediately, ensuring that new link equity and semantic relevance are recognized by the SERPs without delay.
What is Edge-Side Contextual Injection in technical SEO?
Edge-Side Contextual Injection is an architectural shift where internal links are dynamically injected into the HTML stream at the CDN or edge layer. This allows for real-time, bot-specific link structures that maximize crawl budget without creating database bloat or REST API bottlenecks.