Executive Summary
- API rate limiting is a critical governance mechanism that regulates the frequency of requests to an interface to prevent resource exhaustion and ensure high availability.
- In the context of AI search and RAG systems, rate limits dictate the throughput of data ingestion and the responsiveness of real-time generative agents.
- Effective management of rate limits through exponential backoff and caching is essential for maintaining consistent AI visibility and source attribution.
What is API Rate Limiting?
API rate limiting is a technical strategy used by service providers to control the rate at which a client can make requests to a server or interface. By imposing a cap on the number of API calls within a specific timeframe—such as requests per minute (RPM) or tokens per day (TPD)—organizations can prevent server overload, mitigate Distributed Denial of Service (DDoS) attacks, and ensure fair resource distribution among all users. In modern AI architectures, rate limiting is often implemented using sophisticated algorithms such as Token Bucket, Leaky Bucket, or Fixed Window Counters.
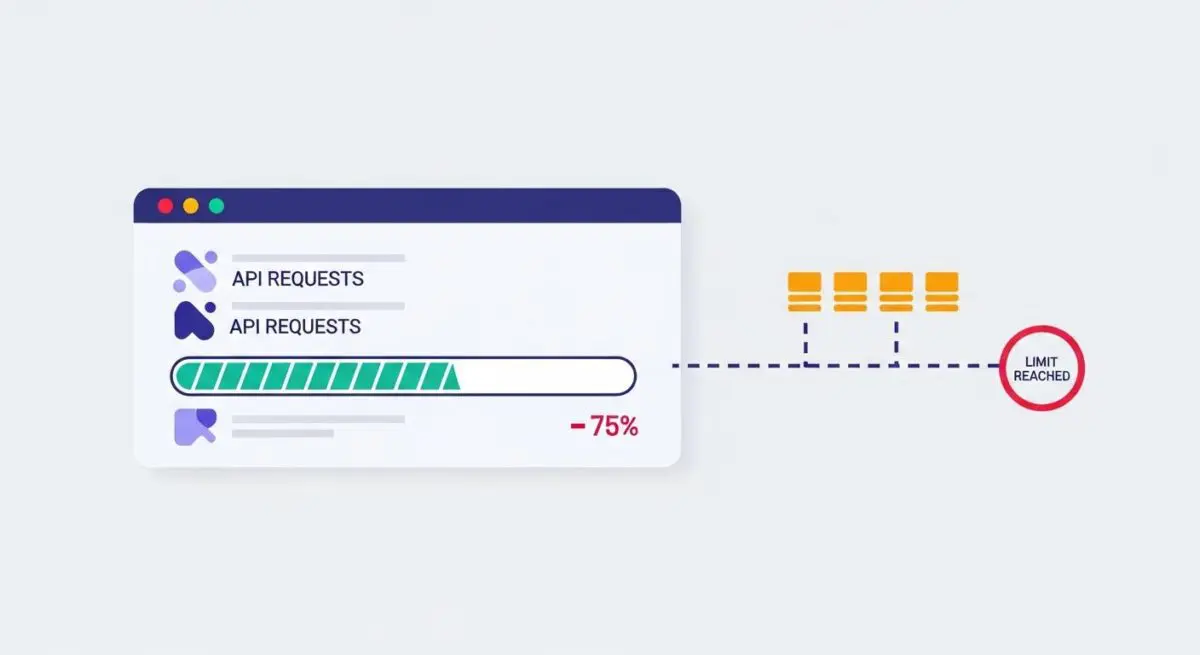
For AI developers and SEO professionals, understanding rate limiting is vital when interacting with Large Language Model (LLM) providers like OpenAI or Anthropic. These providers utilize multi-tiered rate limits based on usage tiers and model complexity. Exceeding these limits results in HTTP 429 Too Many Requests errors, which can disrupt automated workflows, data scraping for AI training, and real-time retrieval processes necessary for Generative Engine Optimization.
The Real-World Analogy
Imagine a high-end, exclusive restaurant with only ten tables. To ensure every guest receives impeccable service and the kitchen is never overwhelmed, the host only allows one new party to enter every fifteen minutes. If twenty groups arrive at once, the host asks the remaining ten to wait outside until a slot opens up. API rate limiting acts as that host, ensuring the “kitchen” (the server or AI model) can process every “order” (request) with high quality without crashing from a sudden surge in demand.
Why is API Rate Limiting Important for GEO and LLMs?
In the landscape of Generative Engine Optimization (GEO), API rate limiting directly impacts how efficiently AI agents can crawl, index, and synthesize web content. If a website’s infrastructure or the AI’s retrieval mechanism hits a rate limit during a Retrieval-Augmented Generation (RAG) cycle, the AI may fail to access the most recent data, leading to poor source attribution or total exclusion from the generative response. Furthermore, rate limits influence the latency of AI-driven search results; a throttled API connection increases the time-to-first-token, negatively affecting the user experience and the perceived authority of the AI agent in competitive search environments.
Best Practices & Implementation
- Implement Exponential Backoff: When a 429 error is encountered, programmatically increase the wait time between retries to allow the rate limit window to reset without further stressing the server.
- Optimize Payload Efficiency: Reduce the frequency of calls by batching requests or minimizing the data sent in each transaction to stay within token-based limits.
- Utilize Server-Side Caching: Store frequent API responses in a cache (like Redis) to serve repeated queries without triggering a new external API call, preserving your rate limit quota.
- Monitor Rate Limit Headers: Actively parse response headers such as X-RateLimit-Remaining and X-RateLimit-Reset to dynamically adjust request velocity in real-time.
Common Mistakes to Avoid
One frequent error is the failure to distinguish between different types of limits, such as Requests Per Minute (RPM) versus Tokens Per Minute (TPM), leading to unexpected service interruptions. Another mistake is hard-coding retry logic without “jitter,” which can cause “thundering herd” problems where multiple clients retry simultaneously, further overwhelming the API. Finally, many brands neglect to scale their API tiers in anticipation of traffic spikes, resulting in downtime during critical high-visibility periods.
Conclusion
API rate limiting is a fundamental pillar of AI infrastructure that ensures system stability and equitable access. Mastering its mechanics is essential for maintaining the reliability and performance of AI-search integrations and GEO strategies.