Key Points
- Identify Infinite Loops: Monitor server access logs for exponential spikes in GET requests targeting sequential date parameters.
- Control Crawl Paths: Implement strict robots.txt Disallow rules alongside X-Robots-Tag headers to halt recursive discovery.
- Validate Edge Cache: Ensure CDN layers like Cloudflare are not serving stale HTML that bypasses origin server canonicalization directives.
Table of Contents
The Core Conflict: Infinite Crawl Loops
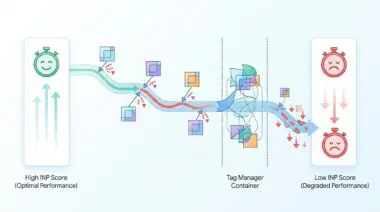
Search engines can miss up to half of your website’s most important pages if they get stuck. This often happens when they fall into endless loops created by unmanaged calendar widgets.
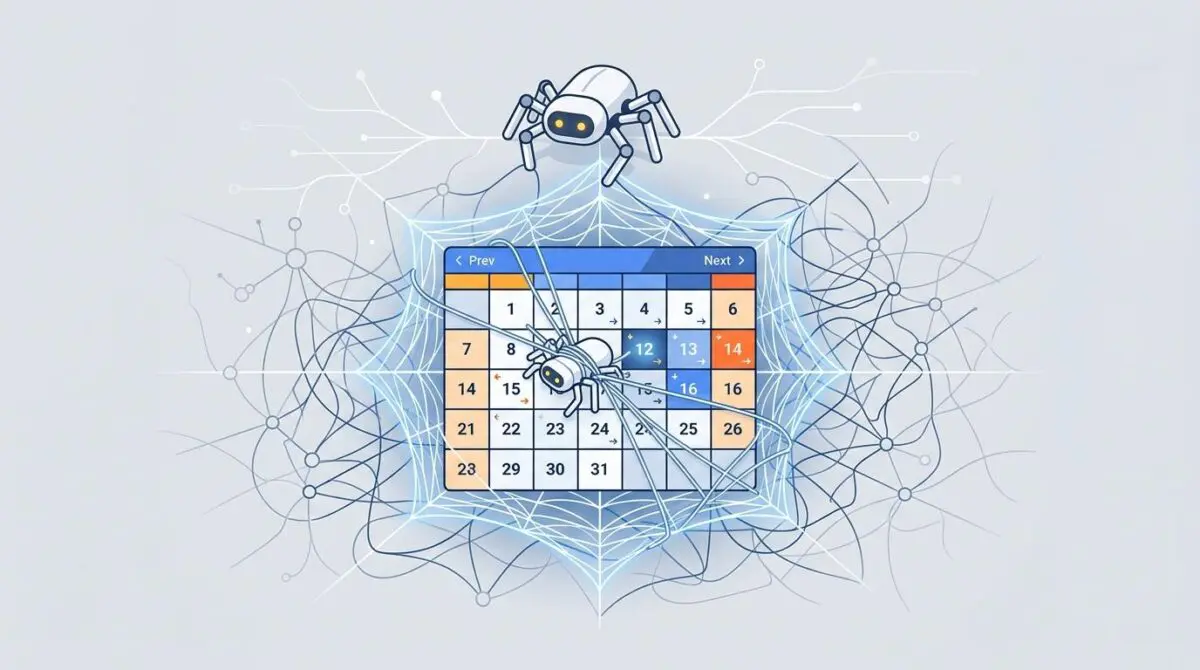
This structural flaw generates a virtually infinite number of unique web addresses. It causes search engine crawlers like Googlebot to enter a never-ending cycle, commonly known as a Spider Trap.
These traps often happen when calendar links for next or previous months are generated without an end date. The bot crawls deep into the future or past where no actual content exists.
This behavior effectively hijacks the crawler’s resources. It prevents the discovery of high-value pages and severely impacts your overall crawl budget.
These traps also dilute the website’s overall meaning and focus. They bloat the search index with thin, repetitive data, making it harder for AI models to understand your true expertise.
Diagnostic Checkpoints and Root Causes
Identifying a Spider Trap requires a deep dive into your server access logs and Google Search Console data. You will typically see a massive spike in crawl requests for web addresses containing sequential dates.
These server logs often show heavy Googlebot activity on specific calendar views. The server returns a successful status code even when there is absolutely no event data present.
Diagnostic Checkpoints
Unconstrained Recursive Link Generation
Mathematical link logic creates infinite unique crawlable URLs.
Session ID and Timestamp Appending
Unique URL parameters create redundant views for crawlers.
JS-Rendered Link Discovery
Crawlers execute scripts to find infinite calendar navigation paths.
Lack of Self-Referencing Canonical Tags
Missing canonicals allow every date permutation to be indexed.
Server and Application Desynchronization
The root cause is usually a mismatch between your application logic and your server’s routing rules. These endless loops are often unintentionally created by dynamic calendar widgets that rely on math rather than actual database content.
Because the web address changes with each click, the crawler treats every new month as a brand new page. This problem is compounded by modern web rendering services that execute JavaScript to discover links within interactive interfaces.
Furthermore, session identifiers or timestamps are frequently added to internal navigation links. This creates a completely new web address for the exact same calendar view.
The Engineering Resolution
Resolving an infinite crawl loop requires a multi-layered approach to restrict crawler access. You must address the issue at the robots.txt level, the application level, and the server header level.
Engineering Resolution Roadmap
Implement Robots.txt Disallow
Add a Disallow rule to your robots.txt file using wildcards to block the specific query parameter used by the calendar (e.g., Disallow: /*?calendar_month=*).
Apply rel=’nofollow’ to Navigation Links
Modify the calendar template file (e.g., in your WP child theme) to add rel=’nofollow’ to the HTML anchors for ‘Next’ and ‘Previous’ month links.
Configure X-Robots-Tag for Dynamic Views
Inject a ‘noindex, follow’ header via the functions.php file or server config for any URL that contains calendar-related query parameters.
Set Hard Limits in Plugin Settings
Navigate to the specific calendar plugin’s settings and restrict the navigation range to a maximum of 12-24 months in the future.
Controlling Crawler Behavior
Implementing a Disallow rule in your robots.txt file is the first line of defense. It stops Googlebot from initiating new requests to those endless calendar links.
However, robots.txt rules do not prevent pages from being indexed if they are linked externally. You must also modify the calendar template files to ensure proper link attributes are in place.
Injecting a strict server response ensures that any dynamically generated view is dropped from the search index. Finally, setting hard limits within the plugin settings prevents the application from generating future links entirely.
Resolution Execution: Code Implementation
To execute this fix permanently, we must intercept the server response before the page even loads. This ensures that search engines receive the correct indexing instructions immediately.
Fixing via WordPress Functions
If you are operating on a WordPress website, you can utilize core hooks to modify the server headers. The following function intercepts requests containing specific calendar parameters.
By hooking into the header initialization phase, we forcefully apply a strict rule. This tells the crawler to immediately discard the web address and halt link discovery.
add_action('send_headers', 'prevent_calendar_indexing'); function prevent_calendar_indexing() { if (isset($_GET['month']) || isset($_GET['calendar_year'])) { header('X-Robots-Tag: noindex, nofollow', true); } }Validation Protocol & Edge Cases
Once the technical fix is deployed, immediate validation is required. You must confirm that the server is broadcasting the new instructions correctly.
Validation Protocol
- Run Google Search Console URL Inspection on dynamic links.
- Execute Live Test to confirm ‘Excluded by robots.txt’ status.
- Use CLI curl -I command to inspect server response headers.
- Verify presence of X-Robots-Tag: noindex, nofollow in output.
Handling CDN and Cache Conflicts
A rare but critical conflict occurs when a Content Delivery Network like Cloudflare has aggressive caching enabled. The network may serve an old, cached version of the calendar without the new header.
If your site uses Edge Workers to rewrite web addresses, the worker might accidentally create new crawlable paths. These paths can completely bypass the rules defined at your main server.
When edge cache ignores your instructions, search engines may fail to crawl up to half of your most important pages due to rapid resource depletion. Always purge your cache and test directly against the main server to isolate the response.
Autonomous Monitoring & Prevention
Preventing future spider traps requires establishing a regular log analysis routine. Specialized tools are essential to identify high-frequency link patterns before they exhaust your crawl budget.
At Andres SEO Expert, we recommend implementing automated monitoring for your search console. This allows you to trigger instant alerts on sudden increases in excluded pages.
Building an automated pipeline ensures that your technical team is notified the moment a plugin update breaks your link structure. Proactive monitoring is the ultimate way to maintain website health at the enterprise level.
Conclusion
Spider traps generated by dynamic calendar widgets represent a severe threat to your server health and search visibility. By implementing strict crawler rules and validating your server headers, you can successfully collapse the infinite loop.
Reclaiming your crawl budget allows search engines to focus on your high-value content. Continuous log monitoring will ensure that future application updates do not reintroduce these endless pathways.
Navigating the intersection of technical SEO, server architecture, and generative search requires a precise roadmap. If you need to future-proof your website, resolve deep-level crawl anomalies, or implement AI-driven SEO automation, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is an infinite crawl loop in SEO?
An infinite crawl loop, or spider trap, is a structural flaw in a website’s architecture that generates a virtually endless number of unique URLs. This recursive loop hijacks search engine crawler resources, preventing them from discovering or updating critical, high-value pages on the site.
How do calendar widgets create spider traps for search engine bots?
Calendar widgets create spider traps when navigation links for next or previous months are programmatically generated without a terminal date. Search engine bots follow these mathematical links into the infinite future or past, crawling pages where no actual content exists.
How can I identify a spider trap using server access logs?
To identify a spider trap, look for exponential spikes in crawl requests for URLs containing sequential date parameters. Server logs typically reveal heavy Googlebot activity on specific patterns where the server returns a successful HTTP status code despite a complete absence of data.
What are the technical methods to stop infinite calendar crawling?
Resolving infinite crawling requires a multi-layered approach: implementing robots.txt Disallow rules for calendar parameters, applying rel=’nofollow’ to month-to-month navigation links, and configuring an X-Robots-Tag: noindex HTTP header for all dynamic calendar views.
How does a spider trap impact Generative Engine Optimization (GEO)?
From a GEO perspective, spider traps dilute a website’s semantic density and bloat the index with thin, repetitive data. This makes it harder for Large Language Models (LLMs) to determine topical authority and accurately understand the site’s content entities.
Can a CDN cause a crawl loop resolution to fail?
Yes, if a CDN has aggressive caching enabled, it may serve a cached version of a calendar view that lacks the new indexing directives. This can allow search engines to bypass origin server robots.txt rules or X-Robots-Tag headers until the edge cache is fully purged.