Key Points
- Automated Prompt Distillation: Transition from manual prompt engineering to automated compilation layers like DSPy 3.0, reducing redundant token overhead by up to 90%.
- Model Cascading Economics: Implement dynamic routing architectures to offload trivial tasks to micro-models, reserving high-cost frontier models strictly for complex reasoning.
- Zero-Token Architectures: Shift toward a State-as-a-Service paradigm by leveraging persistent provider-side KV-caches to eliminate the financial drain of re-transmitting conversation histories.
Table of Contents
The Core Friction: The Inference Cost Crisis
Global AI spending is on track to hit $2.59 trillion this year. Yet, behind this staggering capital deployment lies a silent infrastructure crisis.
A projected 40% of agentic AI projects face cancellation by 2027 due to unsustainable token costs and unmanaged inference overhead. The era of recklessly dumping massive datasets into context windows is officially over.
Enterprises are colliding with a phenomenon known as Context Inflation. This friction occurs when autonomous agents consume exorbitant compute power to execute basic reasoning loops.
Driven by a fear of AI hallucination, engineers often default to injecting entire company wikis into a single prompt. This brute-force approach creates an invisible, compounding tax on every API call.
To survive this margin-crushing reality, smart money is pivoting toward Prompt Token Optimization (PTO) and Inference FinOps. This emerging discipline treats API tokens as a strict financial budget rather than an infinite resource.
PTO is no longer a niche engineering trick. It is a fundamental business mandate required to keep high-scale Retrieval-Augmented Generation (RAG) commercially viable.
Market Intelligence: Where the Smart Money is Flowing
Market Intelligence & Data
Multi-Model Cost Reduction
Enterprises using multi-model routing and aggregation platforms saw a 67% year-over-year drop in effective token costs as of April 2026, according to the AI API Infrastructure Report.
Agentic Token Demand
Gartner research from March 2026 warns that autonomous AI agents consume between 5 and 30 times more tokens per task than standard 2024-era chatbots.
Inference Spending Dominance
Data from Oplexa indicates that AI inference now represents 85% of total enterprise AI budgets in 2026, up from less than 20% during the experimental phases of 2023.
Efficiency-Focused Capital
Crunchbase data reveals that AI startups secured $242 billion in Q1 2026, with a massive shift in capital toward infrastructure tools designed to manage and optimize API consumption.
The data reveals a seismic shift in venture capital allocation. AI startups captured 80% of all global funding in early 2026, reaching a historic peak of $242 billion.
However, investors are no longer solely chasing foundational models. Smart capital is aggressively flowing into Inference Efficiency infrastructure.
Foundational giants are defending their moats by integrating native prompt caching. This forces a rapid evolution in how developers structure API calls to maintain competitive margins.
Simultaneously, efficiency disruptors are capturing massive market share. Innovative startups are utilizing nature-inspired algorithms to compress massive models for localized deployment.
Meanwhile, specialized platforms are reducing API integration latency by up to 70%. These innovations are essential because unoptimized systems are rapidly becoming financial liabilities.
Without these infrastructure upgrades, ambitious enterprise initiatives are forecasted for cancellation due to unsustainable token costs. The market is ruthlessly punishing inefficient compute consumption.
The Strategic Deep Dive: From Artisanal Prompts to Automated Distillation
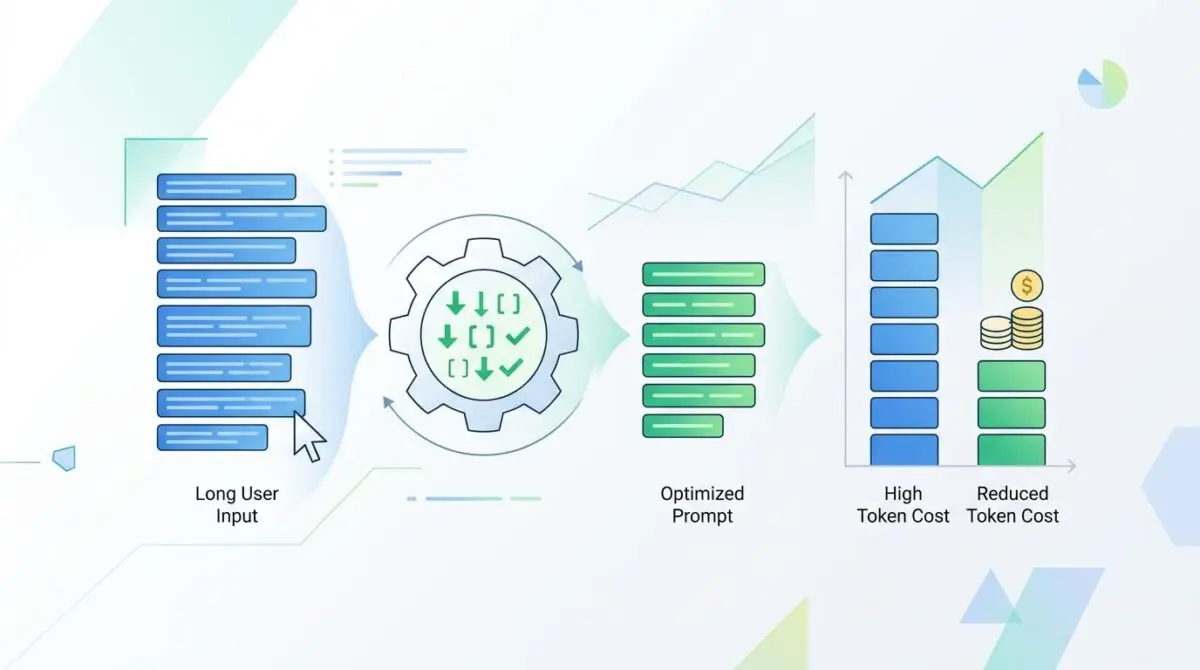
Prompt optimization has completely evolved. The industry has moved away from manual, artisanal writing toward automated compilation layers.
Advanced frameworks are leading this charge. Enterprises now deploy Prompt Distillation pipelines that aggressively strip redundant linguistic tokens before they reach high-cost APIs.
This automated curation process achieves up to 90% savings on inference costs. It transforms bloated, human-readable prompts into highly compressed, machine-optimized data payloads.
By treating prompts as compiled code rather than natural language, businesses remove the unpredictable human element from their inference budgets. This guarantees a mathematically optimized context window for every query.
Model Cascading and Semantic Caching
One of the most potent strategies in the PTO arsenal is Semantic Caching. This architectural safeguard prevents enterprises from paying for repeated queries by recalling identical semantic intents from local memory.
Coupled with Context Window Rationing, businesses can strictly limit the amount of historical data fed into each query. This directly combats the compounding costs of long-running agentic workflows.
Furthermore, Model Cascading has become the gold standard for routing efficiency. This technique dynamically routes simple sub-tasks to ultra-cheap micro-models, which cost mere fractions of a cent per million tokens.
By offloading trivial cognitive load to these micro-models, organizations can reserve frontier models strictly for final, high-stakes reasoning. This creates a highly resilient and cost-effective AI architecture.
The Volatility of Unoptimized Agentic Systems
The financial risk of ignoring Inference FinOps cannot be overstated. Agentic AI introduces a massive token multiplier compared to standard chatbots.
Recent industry audits have revealed the terrifying volatility of unoptimized systems. Some major tech firms have reportedly exhausted their entire annual AI compute budgets in just several weeks.
These financial catastrophes occur when internal engineering agents trigger runaway token consumption loops. Without strict financial guardrails, autonomous agents will blindly consume API credits until the budget evaporates.
This is why Semantic Pruning is no longer optional. Enterprises must actively monitor and slice context windows in real-time to prevent these catastrophic runaway loops.
The Executive Action Plan: Pioneering Zero-Token Architectures
The next evolution of Inference FinOps requires a complete paradigm shift. The industry is rapidly moving toward Autonomous Token Budgeting.
In this near-future state, AI agents are assigned dynamic financial quotas. They are programmed to self-optimize their own prompt complexity based on the economic value of the specific task at hand.
Strategic Trajectory
- Deploy ‘Autonomous Token Budgeting’ systems to assign dynamic financial quotas to AI agents.
- Empower agents to self-optimize prompt complexity based on the economic value of the task.
- Transition to ‘Zero-Token’ architectures using persistent provider-side KV-cache states.
- Eliminate redundant data overhead by ending the re-transmission of conversation histories.
- Pivot organizational infrastructure toward a ‘State-as-a-Service’ model for inference management.
Founders must immediately begin transitioning toward Zero-Token architectures. This involves maintaining persistent KV-cache states on the provider side.
By holding the context state active on the server, developers effectively end the era of re-sending massive conversation histories with every API ping. This drastically reduces payload sizes and subsequent billing.
Ultimately, this shifts the entire industry toward a State-as-a-Service model. Organizations that master this transition will secure a permanent competitive advantage in compute efficiency.
Conclusion: The State-as-a-Service Paradigm
The battle for AI supremacy is no longer just about parameter count or reasoning benchmarks. It is fundamentally a war of inference economics.
Prompt Token Optimization and Inference FinOps represent the critical bridge between experimental AI and scalable enterprise reality. Those who fail to optimize will be priced out of the autonomous future.
By embracing model cascading, prompt distillation, and zero-token architectures, visionary leaders can transform compute overhead into a strategic moat.
Navigating the intersection of technology, capital, and market psychology requires a sharp strategy. To future-proof your business architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is Context Inflation in AI systems?
Context Inflation is a phenomenon where autonomous agents consume excessive amounts of compute and tokens to execute basic reasoning loops. It often occurs when engineers inject massive datasets into a context window to prevent hallucinations, creating an invisible, compounding tax on every API call.
How does Prompt Token Optimization (PTO) reduce inference costs?
PTO uses automated compilation layers and frameworks like DSPy 3.0 to strip redundant linguistic tokens from prompts. By treating prompts as compiled code rather than natural language, organizations can achieve up to 90% savings on inference by transforming bloated prompts into machine-optimized data payloads.
Why are enterprise agentic AI projects at risk of cancellation?
Approximately 40% of agentic AI projects are forecasted for cancellation by 2027 due to unsustainable token costs. Autonomous agents typically consume 5 to 30 times more tokens than standard chatbots, which can lead to rapid budget exhaustion if inference overhead is not managed through FinOps.
What is the difference between Model Cascading and Semantic Caching?
Model Cascading routes simple tasks to cheaper models while reserving frontier models for high-stakes reasoning. Semantic Caching prevents redundant spending by recalling identical semantic intents from local memory instead of re-processing the same query through an expensive API.
What are Zero-Token architectures in AI infrastructure?
Zero-Token architectures rely on persistent provider-side KV-cache states. By maintaining the context state active on the server, developers eliminate the need to re-transmit long conversation histories with every API ping, drastically reducing payload sizes and subsequent costs.
How significant is inference spending in 2026 AI budgets?
By 2026, AI inference represents 85% of total enterprise AI budgets, a massive increase from less than 20% in 2023. This shift has led to a surge in venture capital toward infrastructure tools designed to optimize API consumption and manage compute efficiency.