Key Points
- API Resilience: Capitalize on date-based CRM endpoints and advanced workflow task isolation to guarantee uninterrupted programmatic extraction pipelines.
- Hallucination Defense: Deploy multi-model AI validation workflows to cross-reference generated narratives against raw numeric CRM fields, preventing costly factual errors.
- Indexing Velocity: Combine automated JSON-LD entity injection with real-time indexing APIs to ensure massive programmatic content rollouts are crawled and ranked instantly.
Table of Contents
The Invisible Tax of Manual Success Stories
The invisible tax of manual SEO execution is paid in missed opportunities and delayed indexing. Marketing teams spend countless hours interviewing sales representatives, digging through fragmented spreadsheets, and manually drafting success stories.
This archaic process creates a massive bottleneck that starves your website of highly authoritative, conversion-focused content. When you rely on human intervention for every piece of bottom-of-the-funnel collateral, scaling your organic footprint becomes mathematically impossible.
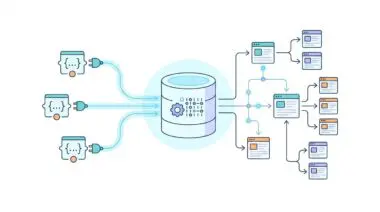
Enter CRM-driven programmatic case study generation, the ultimate architectural solution for this bottleneck. This methodology transforms your customer relationship management platform from a static repository into a dynamic, high-velocity publishing engine.
By connecting your sales data directly to advanced automation workflows, you can generate hundreds of hyper-relevant success stories at scale. It effectively eliminates the structural gap between unstructured CRM deal data and high-fidelity, narrative-driven SEO content.
The real magic lies in satisfying search engine guidelines without triggering thin content penalties. Modern algorithms demand profound expertise, experience, authoritativeness, and trustworthiness.
By feeding raw, verified data into sophisticated storytelling models, you produce rich, factual narratives that prove your value proposition. This approach turns scattered deal properties into a cohesive, highly indexable library of proof.
Engineering Resilient Data Extraction Pipelines
Scaling programmatic content requires an infrastructure that will not collapse under its own weight. Server performance, rendering speed, and operational efficiency are heavily dictated by the stability of your data extraction pipelines.
When dealing with high-volume case study generation, the underlying database and API connections must operate with absolute precision. Any latency or unexpected schema change can bring your publishing engine to a grinding halt.
One of the most critical metrics for operational efficiency is the API version stability window. By leveraging HubSpot’s date-based API versioning, programmatic SEO pipelines secure a guaranteed eighteen-month support window.
This immutable endpoint stability means your automated extraction logic remains functional without sudden breaking changes. You no longer have to worry about silent API deprecations destroying your content generation workflows overnight.
On the server performance side, processing thousands of unstructured data points demands serious computational power. With the introduction of advanced architectural upgrades, including Task Runner isolation in n8n v2.0, systems now benefit from SQLite pooling drivers that deliver up to a 10x database performance lift.
This massive acceleration is essential for data-intensive JSON transformations. It ensures that your workflow automation platform can ingest, process, and map massive CRM payloads in milliseconds, keeping your publishing rhythm entirely uninterrupted.
Bridging Unstructured Deals to High-Fidelity Content
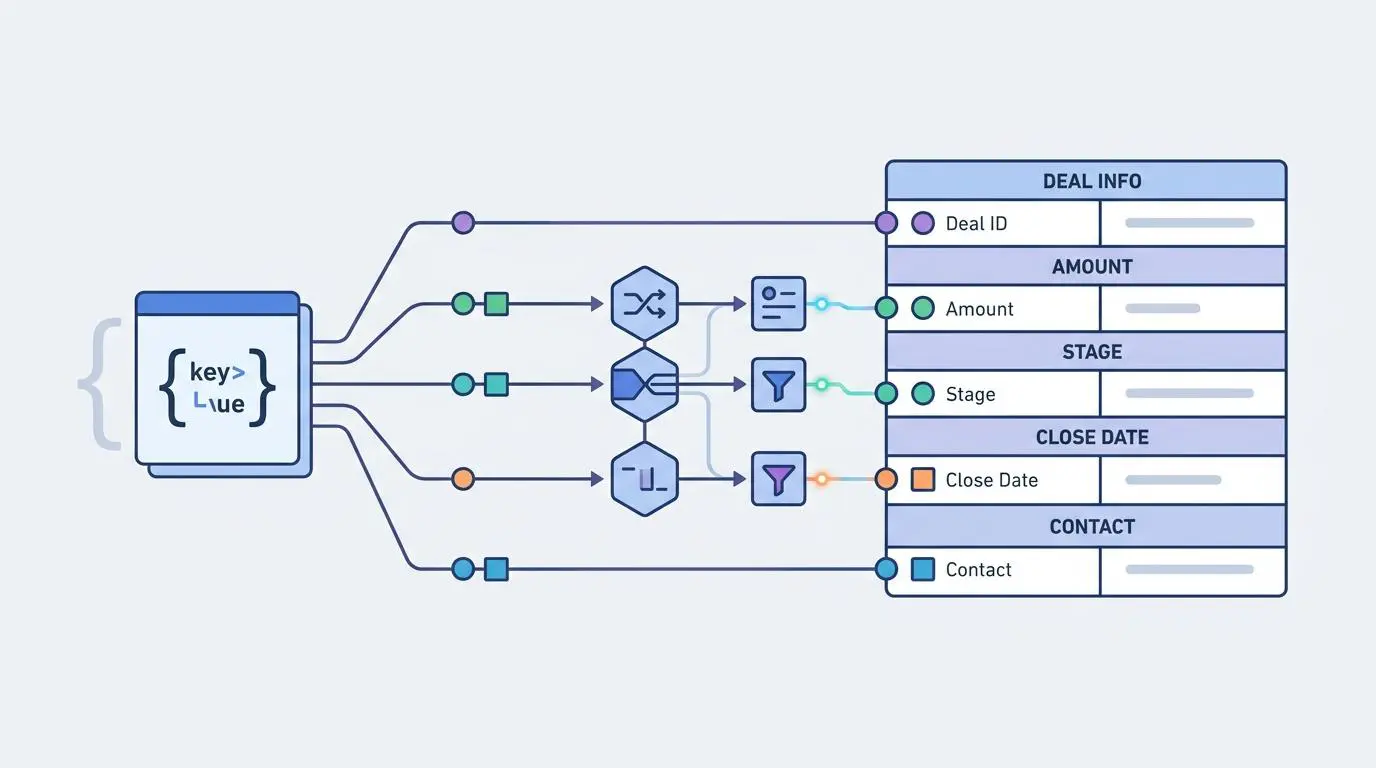
The foundational layer of programmatic architecture relies on seamless API communication. Utilizing the HubSpot March 2026 date-based API ensures that your endpoints remain rock solid.
Automation platforms like n8n use private app tokens for secure, internal authentication without the overhead of complex OAuth2 handshakes. Data is systematically pulled via specific read scopes to map associations between companies and their corresponding deals.
The primary friction in this process is mapping non-standardized custom properties from legacy CRM instances. Unstructured deal data often exists in a chaotic state, filled with internal jargon and inconsistent formatting.
Translating this raw data into a structured JSON schema that language models can digest is akin to translating multiple dialects into a single universal language. Without this normalization, crucial numeric context is lost before the storytelling even begins.
Fortunately, technological advancements are smoothing out this friction. HubSpot’s 2026 Breeze Assistant integration allows automation workflows to query the CRM using natural language.
This effectively replaces complex object ID mapping with intent-based data retrieval. By seamlessly pulling the exact narrative drafts needed, the system bridges the gap between raw data and high-fidelity content effortlessly.
Securing the Narrative Through Multi-Model Validation
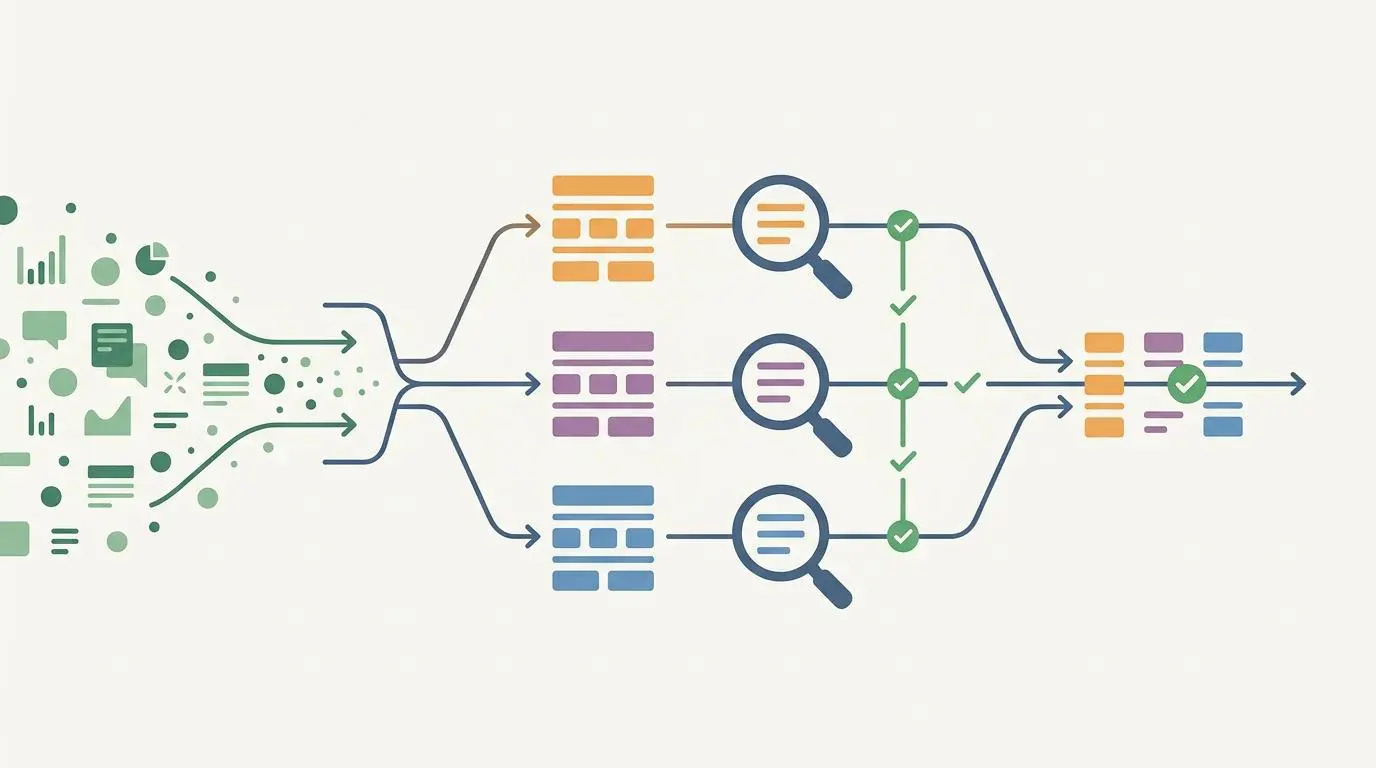
Generating content at scale introduces the severe risk of AI hallucination. To combat this, advanced pipelines deploy multi-model nodes to cross-reference generated narratives against raw numeric fields.
By utilizing models like Claude 3.7, the system evaluates the storytelling output against the rigid financial data pulled from forecast APIs. This creates a rigorous quality assurance layer.
Artificial intelligence agents frequently misinterpret raw revenue figures as return on investment percentages. This real-world friction can lead to publishing inaccurate financial claims, which severely damages brand trust and algorithmic authority. An automated workflow must act as a strict financial auditor, verifying every single metric before the content moves to the publishing stage.
To solve this, workflows incorporate an automated source of truth check. This isolation mechanism evaluates the generated text and halts the publishing process if the delta between the CRM data and the narrative exceeds a strict one percent threshold. This guarantees that your programmatic case studies are not only compelling but mathematically flawless.
Injecting Automated Schema for Rich Result Dominance
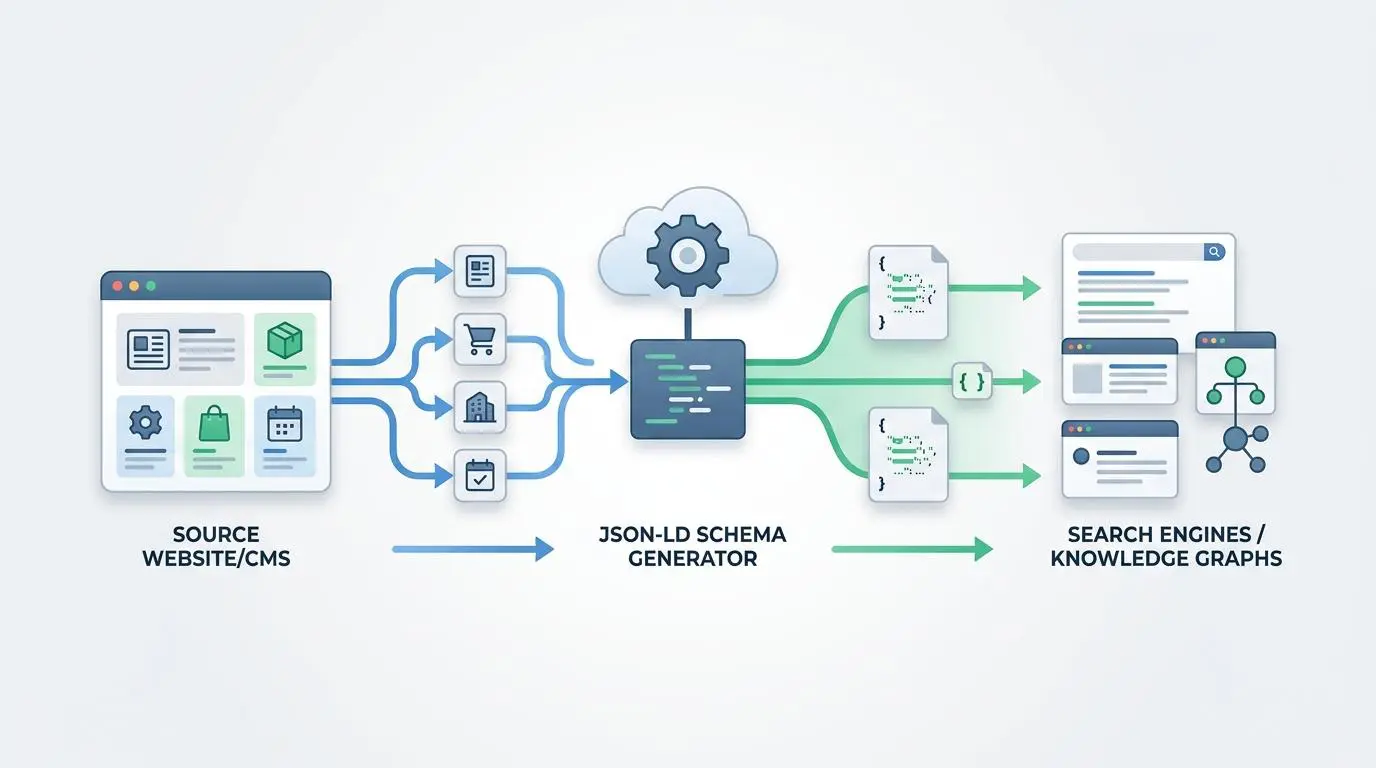
Structuring your data for search engines is just as important as structuring your narrative for human readers. Automated injection of specific schema markup via JSON-LD transforms a standard webpage into a rich, machine-readable entity. Workflows dynamically populate about and mentions entities using industry classification codes to provide precise context to search crawlers.
The real-world friction here lies in aligning varied CRM industry descriptions with the formal vocabulary required by schema standards. Sales teams often use colloquial industry terms that do not match standard classification codes. Improper entity mapping leads to failed rich result eligibility, leaving your case studies invisible in advanced search console reports.
By utilizing expression editors within the automation platform, the pipeline translates internal CRM jargon into standardized NAICS or SIC codes. This gives search engines a perfectly labeled map of your content’s DNA. As a result, your programmatic case studies become highly eligible for rich snippets, driving higher click-through rates from the search engine results pages.
Orchestrating Rapid Indexing and Crawl Rhythms
Creating hundreds of high-quality case studies is useless if search engines never discover them. Integration of real-time indexing APIs provides immediate pinging for newly published URLs. Workflows utilize HTTP request nodes to alert search engines the moment a programmatic asset goes live, entirely bypassing the traditional waiting period for organic crawling.
High-volume programmatic publishing often triggers a frustrating discovered but currently not indexed status. This real-world friction occurs when the internal link architecture fails to provide sufficient PageRank flow to deep-level URLs. Search engines see the pages but deem them too structurally isolated to warrant immediate indexation.
To overcome this, workflows are strategically gated by wait nodes to manage crawl frequency and avoid rate-limiting penalties. Furthermore, the automation must dynamically update internal linking hubs, laying down a high-speed rail line directly to the new content. This ensures that authority flows seamlessly to the deepest programmatic URLs, forcing rapid indexation.
The 2027 Horizon of Agentic Content Maintenance
The future of programmatic SEO is moving far beyond static content generation. By early 2027, the industry will shift entirely toward agentic content maintenance.
Autonomous agents will continuously monitor advanced CRM endpoints for real-time deal status changes. When a client renews a contract or achieves a higher return on investment, the system will detect this shift instantly.
These autonomous agents will automatically update live case studies with the freshest data available. This ensures perpetual freshness and real-time authority, signaling to search engines that your content is an actively maintained source of truth. Your programmatic architecture will evolve from a one-time publishing pipeline into a living, breathing digital ecosystem.
Navigating the intersection of technical SEO, programmatic architecture, and workflow automation requires a sharp strategy. To future-proof your site’s architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is CRM-driven programmatic case study generation?
CRM-driven programmatic case study generation is an architectural methodology that transforms raw sales data and deal metrics into high-fidelity SEO content. By connecting CRM platforms directly to automation workflows, organizations can eliminate content creation bottlenecks and scale their authoritative organic footprint at a rate that is mathematically impossible through manual drafting.
How do you prevent AI hallucinations in automated case study pipelines?
Accuracy is maintained through multi-model validation nodes, such as Claude 3.7, which cross-reference generated narratives against raw financial data. Workflows incorporate a strict “source of truth” check that halts the publishing process if the narrative delta between the CRM data and the generated text exceeds a one percent threshold.
Why is HubSpot’s date-based API versioning critical for programmatic SEO?
Date-based API versioning provides a guaranteed eighteen-month stability window for endpoints. This ensures that the underlying data extraction logic remains functional without breaking due to silent API deprecations, allowing programmatic pipelines to operate with absolute precision and long-term reliability.
How does n8n v2.0 improve the performance of content automation?
n8n v2.0 introduces Task Runner isolation and SQLite pooling drivers that deliver up to a 10x lift in database performance. This acceleration is essential for processing high-volume JSON transformations and mapping massive CRM payloads in milliseconds, ensuring the content publishing rhythm remains uninterrupted.
What role does schema injection play in programmatic case studies?
Automated JSON-LD schema injection transforms case studies into machine-readable entities by mapping internal CRM jargon to standardized NAICS or SIC codes. This precise entity labeling makes the content highly eligible for rich snippets in search results, significantly increasing click-through rates and authority.
What is the future of agentic content maintenance in 2027?
By 2027, programmatic SEO will shift toward agentic maintenance where autonomous agents monitor CRM endpoints for real-time changes in deal status or ROI. These agents will automatically update live case studies with the freshest data, signaling to search engines that the content is an actively maintained and perpetually fresh source of truth.