Key Points
- Semantic Chunking: Moving from fixed-token splitting to layout-aware parsing boosts AI retrieval accuracy from 25% to 60%.
- Query Fan-Out Optimization: 88% of AI citations stem from hidden sub-queries, requiring multi-layered content architectures.
- Bot Routing: Serving lightweight Markdown via RAG-ready edges ensures critical data bypasses traditional ingestion barriers.
Table of Contents
The Silent Retrieval Crisis
Every single day, your brand loses high-intent traffic without a single warning light flashing on your analytics dashboard. This is the invisible cost of the impending retrieval crisis. Highly visible organic content is suddenly failing to trigger citations in modern AI assistants.
Brands are quickly discovering that ranking on traditional search engines means nothing if generative engines ignore their authority. Naive Retrieval-Augmented Generation pipelines are currently failing at an alarming rate. This massive drop is primarily driven by stale metadata and arbitrary text chunking methods.
The result is a staggering volume of unbranded queries failing to trigger citations for top-tier companies. The AI simply cannot digest the unstructured information properly. Think of traditional SEO as painting a massive billboard on a busy highway.
RAG-Based Generative Engine Optimization operates on an entirely different level. It is like handing a perfectly organized, highly factual dossier directly to a busy executive assistant. If the dossier is messy or filled with fluff, the assistant simply throws it away.
Metrics Defining AI Visibility
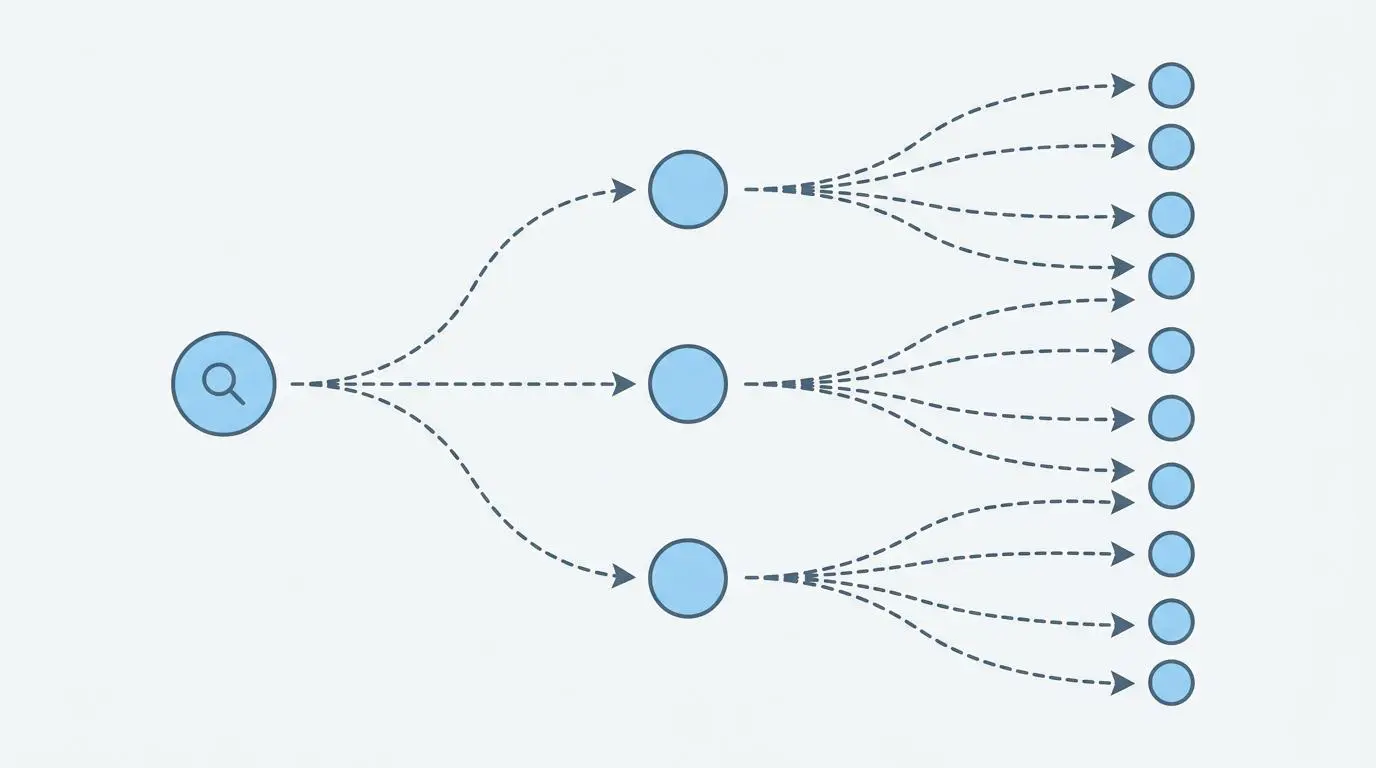
To truly understand this shift, we must examine the underlying data driving generative engines. Recent forensics reveal that the vast majority of citations in AI answers originate from hidden, multi-hop sub-queries. This phenomenon is widely known as the fan-out citation gap.
Users are no longer just asking a single question. The AI actively breaks their prompt into dozens of invisible, parallel searches. Furthermore, data from recent evaluations shows a massive shift in retrieval success.
Systems utilizing semantic chunking with metadata filtering consistently reach higher accuracy benchmarks. This is a monumental leap from the poor performance seen with older, fixed-size chunking strategies. This operational shift is clearly validated by recent evaluations of chunking strategies on financial datasets.
As the industry aggressively moves toward these advanced retrieval methods, the architecture of search is fundamentally changing. We are witnessing a rapid transition toward complex agentic frameworks designed for long-context tasks. Brands that fail to structure their data for these specific frameworks will simply disappear from the generative landscape.
Semantic Chunking Architecture
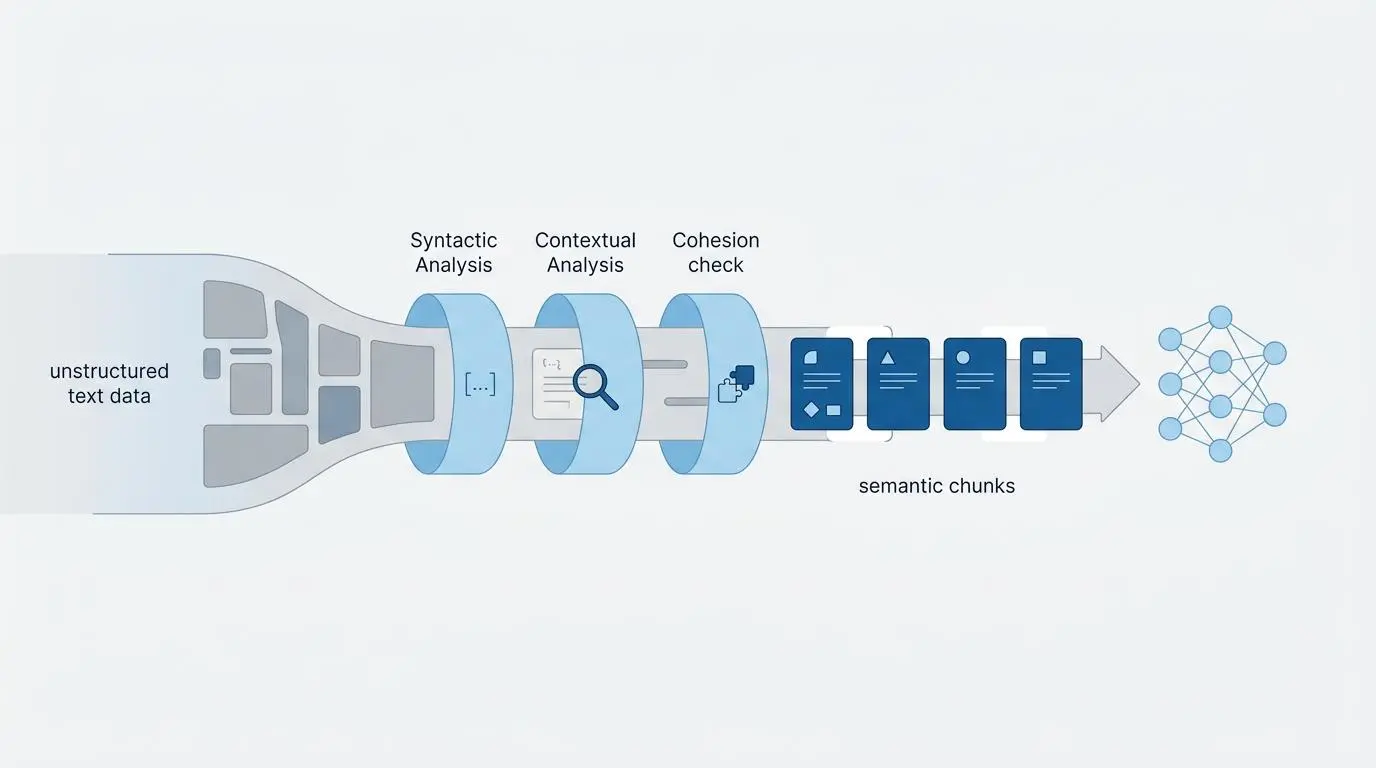
Transitioning from fixed-token splitting to semantic chunking is now a mandatory baseline for digital visibility. Modern Large Language Models require deep context, not just raw text fragments. Advanced parsing tools allow for recursive, layout-aware data extraction.
This ensures that tables, lists, and core facts are ingested as cohesive, logical units. The primary real-world friction here is macro-optimized content bloat. Traditional SEO content was heavily designed to maximize user dwell time.
It is often filled with narrative fluff and lengthy introductions that severely dilute vector centrality. When an AI reads this bloated content, it experiences significant retrieval interference. The vector weight of the actual fact becomes buried under paragraphs of storytelling.
As a result, the AI agent misses the core claim entirely. Generative Engine Optimization requires stripping away this unnecessary fluff. Content must be engineered as dense, high-signal knowledge graphs that an LLM can instantly parse and weigh.
Automated Citation Pipelines
Establishing trust with an AI requires mathematical proof, not just persuasive writing. Integrating claim-grounding schemas and verified statistic APIs is the new standard for source authority. Adding peer-reviewed citations and numeric data directly into your content architecture is highly effective.
This structured approach has been shown to significantly increase citation probability in AI Overviews. The major hurdle brands face in this arena is verification latency. Generative engines now perform rigorous multi-source verification in real time.
These systems cross-reference every factual claim against a recognized trust layer. If a brand makes a proprietary claim that cannot be validated across trusted hubs, the AI simply discards it. The engine labels the unverified claim as a potential hallucination.
Building an automated pipeline that grounds your claims in external, authoritative data is essential. It is the only reliable way to survive this strict algorithmic filter.
Mastering Query Fan-Out
Optimizing for the query fan-out process is arguably the most critical technical pivot of the decade. When a user submits a single prompt, the AI orchestrates dozens of parallel sub-searches. The vast majority of cited content actually targets these invisible sub-queries rather than the primary user keyword.
Failing to optimize for these sub-queries leads to a devastating click-through rate collapse. A significant portion of modern searches now result in zero clicks to external websites. If your brand is not featured in the primary AI Overview context, you become entirely invisible.
Brands missing from these overviews are experiencing a massive drop in organic traffic. Citation-exclusive optimization is no longer an experimental marketing tactic. It is a strict survival requirement for any business relying on digital discovery.
Intelligent Bot Routing
The best content in the world is completely useless if the AI crawler cannot read it. Dynamic routing for specific AI agents is now an essential technical requirement. This process requires dedicated agentic-headers and intelligent server configurations.
Modern content delivery networks now offer specialized edges that detect these bots instantly. Instead of serving heavy, JavaScript-laden web pages, these networks serve lightweight Markdown. This streamlined format is specifically optimized for rapid AI ingestion.
It strips away the visual layer and delivers pure, structured data directly to the crawler. The real-world friction preventing this seamless transfer is the ingestion barrier. A shocking number of enterprise websites still have technical blocks in place.
Legacy crawling rules and complex client-side rendering create massive roadblocks. These outdated setups prevent AI crawlers from accessing the high-quality data needed for accurate answers.
Predictive Intent Sharding
In the near future, Generative Engine Optimization will evolve into predictive intent sharding. AI search engines will pre-calculate and cache retrieval branches before a user even finishes typing their prompt. Brands will inevitably move away from traditional crawling mechanisms entirely.
Instead, they will rely on continuous data streams to push real-time information directly into the latent space of major LLMs. We are already seeing memory-first architectures replace the traditional retrieval orthodoxy. Industry analysts confirm that standard retrieval will soon become a supplementary layer.
It will support agentic long-context memory windows capable of holding millions of tokens. This allows the AI to ingest entire site structures at once. Navigating the intersection of Generative Engine Optimization and AI Search architecture requires a sharp strategy.
To future-proof your brand’s visibility in LLMs and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is the retrieval crisis in generative search?
The retrieval crisis refers to the 40% failure rate of naive RAG pipelines where AI assistants fail to cite high-intent content due to improper chunking, stale metadata, and a lack of recognized authority.
How does semantic chunking improve AI retrieval accuracy?
Semantic chunking uses layout-aware parsing to maintain context, increasing retrieval success to a 60% accuracy benchmark compared to the 25% accuracy seen with older, fixed-size chunking strategies.
What role does query fan-out play in AI citations?
Query fan-out occurs when an AI breaks a prompt into invisible, parallel sub-queries; forensics reveal that 88% of all citations in AI answers originate from these hidden, multi-hop sub-searches.
Why does content fluff negatively impact Generative Engine Optimization (GEO)?
Narrative fluff and lengthy introductions dilute vector centrality, creating retrieval interference that causes AI agents to miss core claims buried under paragraphs of storytelling.
How can brands increase citation probability in AI Overviews?
Integrating claim-grounding schemas and verified statistic APIs can increase citation probability by up to 40% by providing the mathematical proof and external validation AI engines require.
What is the benefit of intelligent bot routing for AI agents?
Intelligent bot routing identifies specific crawlers like OAI-SearchBot and serves lightweight, structured Markdown instead of JavaScript-laden pages, optimizing the data for immediate AI ingestion.