Executive Summary
- Word embeddings transform discrete linguistic tokens into continuous high-dimensional vectors, capturing semantic and syntactic relationships.
- They enable Generative Engine Optimization (GEO) by allowing AI models to calculate the mathematical proximity between user queries and web content.
- Modern embeddings utilize transformer-based architectures to provide context-aware representations, essential for Retrieval-Augmented Generation (RAG).
What is Word Embedding?
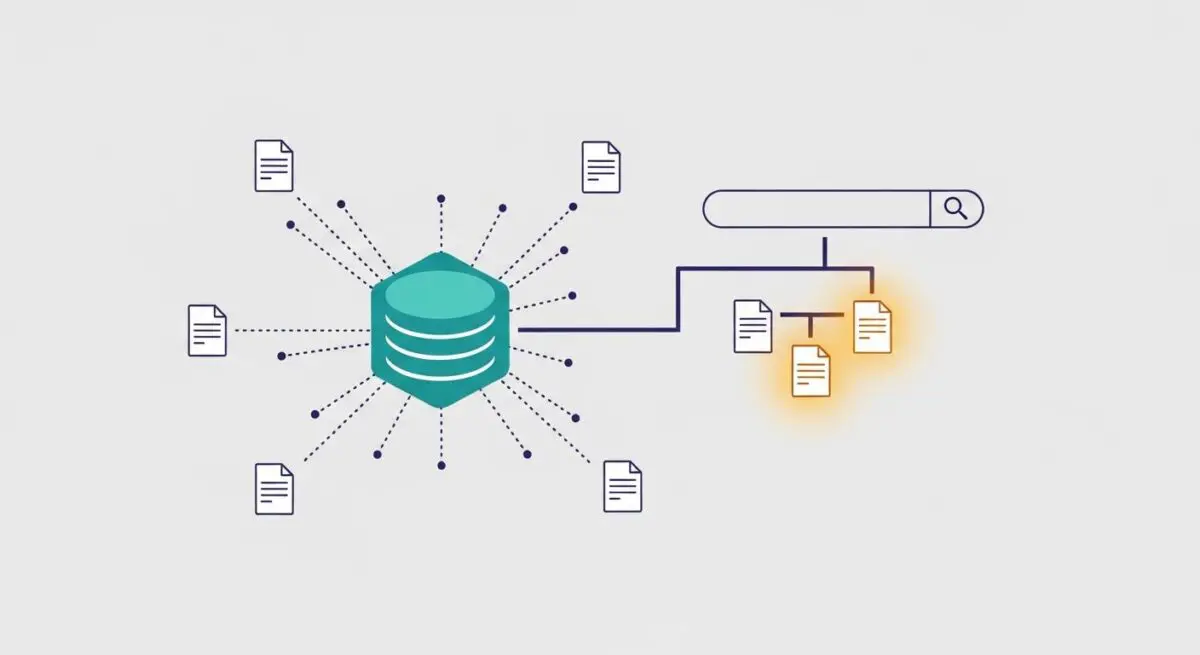
Word embedding is a fundamental Natural Language Processing (NLP) technique where words or phrases from a vocabulary are mapped to vectors of real numbers in a high-dimensional continuous space. Unlike traditional one-hot encoding, which treats words as isolated units, word embeddings capture the semantic and syntactic relationships between words. This is achieved by ensuring that words with similar meanings or those that appear in similar contexts are positioned in close proximity within the vector space, typically measured by cosine similarity or Euclidean distance.
In the context of Large Language Models (LLMs) and modern search architectures, embeddings are generated using neural networks. Early models like Word2Vec and GloVe provided static embeddings, whereas contemporary transformer-based models like BERT or GPT-4 generate contextualized embeddings. These dynamic representations allow the same word to have different vector values depending on its surrounding text, which is critical for resolving polysemy and understanding complex intent in AI-driven search environments.
The Real-World Analogy
Imagine a massive, multi-dimensional library where books are not organized by title or author, but by their precise conceptual content. In this library, every book has a specific set of GPS coordinates. A book about ‘Organic Gardening’ would be physically located very close to a book about ‘Composting,’ but far away from a book about ‘Quantum Physics.’ Word embedding is the mathematical system that assigns these coordinates. It allows an AI ‘librarian’ to find relevant information not by looking for a specific word on a cover, but by navigating to the exact neighborhood of an idea, ensuring that even if the user asks for ‘soil health,’ the system knows to look near ‘fertilizer’ and ‘earthworms.’
Why is Word Embedding Important for GEO and LLMs?
Word embeddings are the engine behind Generative Engine Optimization (GEO) because they shift the focus from keyword matching to semantic relevance. When an LLM processes a query, it converts that query into a vector and searches its internal knowledge or an external index (via RAG) for content with the highest vector similarity. For brands, this means that appearing in AI-generated responses depends on how closely the embedding of their content aligns with the embedding of the user’s intent.
Furthermore, embeddings facilitate Entity Authority. By consistently associating a brand or product with specific technical concepts in a high-dimensional space, the AI begins to recognize that entity as a relevant ‘neighbor’ to those topics. This mathematical proximity is a primary factor in source attribution within AI search engines like Perplexity or SearchGPT, where the system prioritizes content that provides the most precise semantic match to the generated output.
Best Practices & Implementation
- Develop Semantic Clusters: Organize content around comprehensive topic clusters rather than isolated keywords to strengthen the semantic signal for embedding models.
- Optimize for Contextual Relevance: Use precise, industry-specific terminology that helps AI models categorize your content within the correct high-dimensional vector space.
- Implement Structured Data: Use Schema.org markup to explicitly define relationships between entities, providing a clear roadmap for embedding algorithms to follow.
- Enhance Content Depth: Provide exhaustive answers to complex queries to ensure the resulting vector representation is robust and covers multiple facets of a topic.
Common Mistakes to Avoid
One frequent error is keyword stuffing, which disrupts the natural linguistic patterns that embedding models rely on to determine meaning, often resulting in a fragmented or ‘noisy’ vector representation. Another mistake is failing to update legacy content; as embedding models evolve (e.g., moving from Word2Vec to Ada-002), content that lacks depth or clear entity relationships may lose its proximity to high-value search clusters in modern AI indices.
Conclusion
Word embedding is the mathematical bridge that allows AI systems to quantify human language, making it the foundational layer for semantic search and GEO. Mastering the nuances of vector proximity is essential for maintaining visibility in an era dominated by generative search engines.