Key Points
- Semantic Chunking Architecture: Transitioning to 150-word answer chunks eliminates semantic drift and aligns perfectly with the RAG retrieval windows favored by the 2026 Pathfinder algorithm.
- Automated Entity Resolution: Leveraging Diffbot Knowledge Graph APIs and Wikidata RDF injection bypasses generative trust filters, securing deterministic brand disambiguation in LLM latent space.
- Agentic Protocol Alignment: Adopting the llms.txt protocol and reconfiguring legacy CDN rules prevents OAI-SearchBot blocking, ensuring seamless ingestion into the AI Citation Economy.
Table of Contents
- The Citation Disconnect in Modern Retrieval
- Analyzing the AI Visibility Chasm
- Engineering for AI Overviews and Grounding APIs
- RAG-Friendly Architecture and Semantic Chunking
- Knowledge Graph Automation and Entity Resolution
- Agentic Crawler Management and Protocol Alignment
- The 2027 Horizon of Agentic Negotiation
The Citation Disconnect in Modern Retrieval
The invisible cost of relying on legacy SEO metrics is quietly bleeding enterprise visibility dry. Brands are pouring millions into outdated content strategies, only to find themselves completely omitted from modern LLM synthesis.
This systemic failure stems from a fundamental misunderstanding of how search engine algorithms have evolved. We are no longer operating in an era governed strictly by PageRank, keyword density, and lexical matching.
The architecture of discovery has fundamentally transformed into a mathematical evaluation of context. The modern landscape is now dictated by Generative Search Ranking Signal Weights.
This new architectural paradigm requires a radical shift in how we structure, expose, and validate data for machine consumption. When an LLM evaluates a brand’s digital footprint, it looks for deterministic truth rather than probabilistic keyword matches.
It maps relationships in high-dimensional vector space to validate claims and establish trust. Failing to align with these generative signals results in the ultimate technical friction.
Content becomes orphaned in the latent space, lacking the semantic gravity to be pulled into a retrieval window. We call this the citation disconnect, a harsh reality where traditional organic rankings offer absolutely zero guarantee of inclusion in AI-generated answers.
Analyzing the AI Visibility Chasm

To truly understand the urgency of this architectural shift, we must examine the data driving the current citation economy. The divergence between legacy search and generative retrieval is staggering.
A recent 2026 study by BrightEdge confirmed this massive architectural shift, revealing that only 17% of AI Overview sources overlap with traditional organic top-10 rankings. This means that optimizing for ten blue links is now a statistically failing strategy for AI visibility.
High domain authority and extensive backlink profiles are no longer sufficient to guarantee a place in the synthesis layer. LLMs bypass these vanity metrics in favor of semantic density, factual consensus, and entity validation.
The implications for enterprise SEO are profound. If your engineering team is still building architectures designed to capture traditional crawler attention, they are building for a web that no longer exists.
Furthermore, the 2026 AI Citation Economy report by OtterlyAI uncovered a massive technical barrier. A shocking 73% of enterprise websites fail to be cited due to technical roadblocks blocking modern AI agents.
These sites are entirely invisible to crawlers like OAI-SearchBot due to outdated CDN rules and restrictive robots.txt configurations. Security protocols designed to stop malicious scraping are inadvertently executing a digital blackout on the brand.
This invisibility tax is entirely preventable with proper protocol alignment. However, it requires a unified effort between SEO strategists, DevOps, and cloud security teams.
Engineering for AI Overviews and Grounding APIs
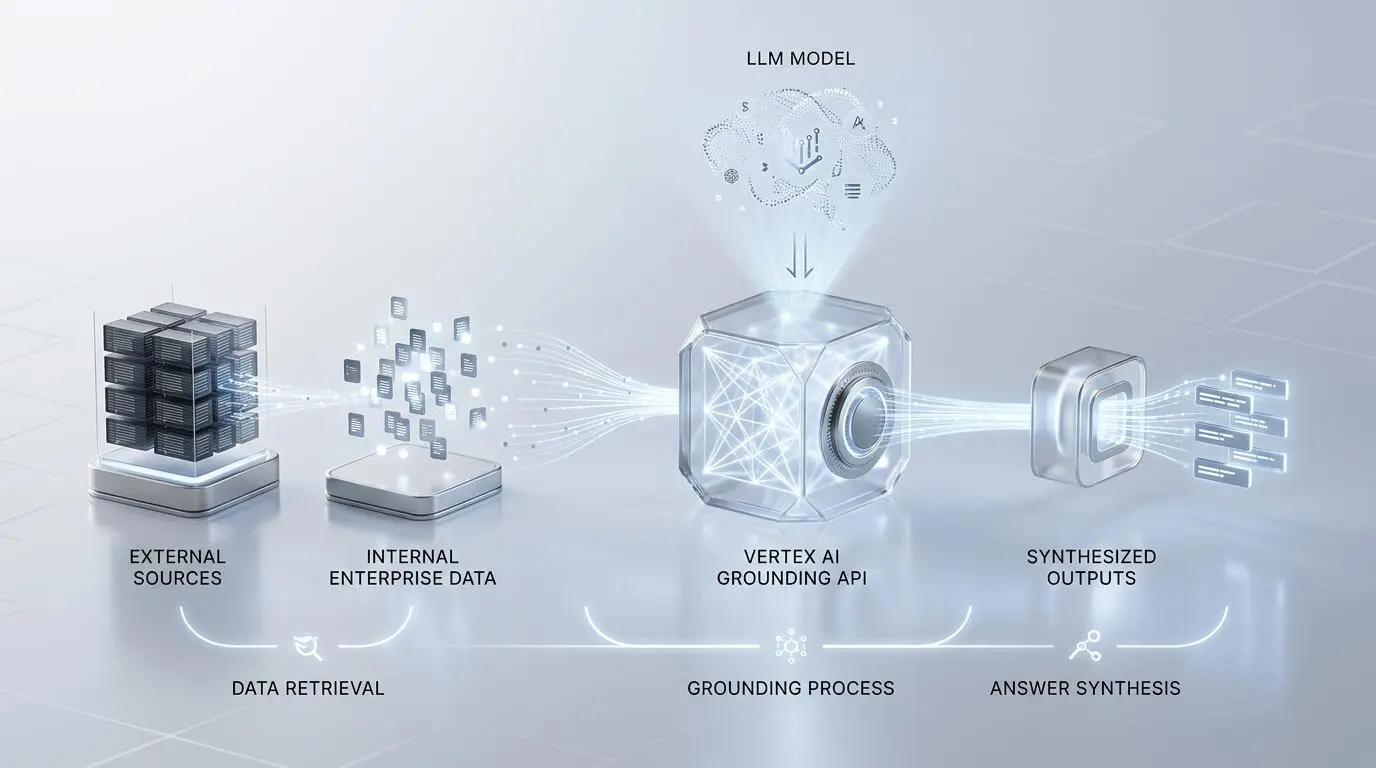
Google’s aggressive transition to Gemini 3.5 Flash as the default model for AI Mode in May 2026 has redefined the search interface. Speed, token efficiency, and real-time synthesis are now the foundational pillars of discovery.
This shift is heavily supported by the integration of real-time search grounding via the Vertex AI Grounding API. Content must now be structured to feed directly into these grounding mechanisms to be considered authoritative.
The Vertex AI Grounding API cross-references enterprise data against foundational models in real-time. If your content is buried beneath heavy DOM structures or bloated JavaScript, it will fail the grounding latency thresholds.
Engineering teams must prioritize server-side rendering and flattened DOM trees to ensure rapid token extraction. The real-world friction of this update is highly visible on the search engine results page.
The average AI Overview height has expanded to 1,200 pixels. This massive interface expansion pushes first-position organic results significantly below the fold.
Users rarely scroll past the generative synthesis, making traditional ranking positions practically irrelevant for top-of-funnel queries. To survive this interface shift, engineering teams must adopt citation-first content architectures.
This involves structuring data payloads specifically for immediate extraction and grounding by Gemini. A citation-first approach strips away marketing fluff and delivers high-density factual statements tailored for machine reading.
RAG-Friendly Architecture and Semantic Chunking
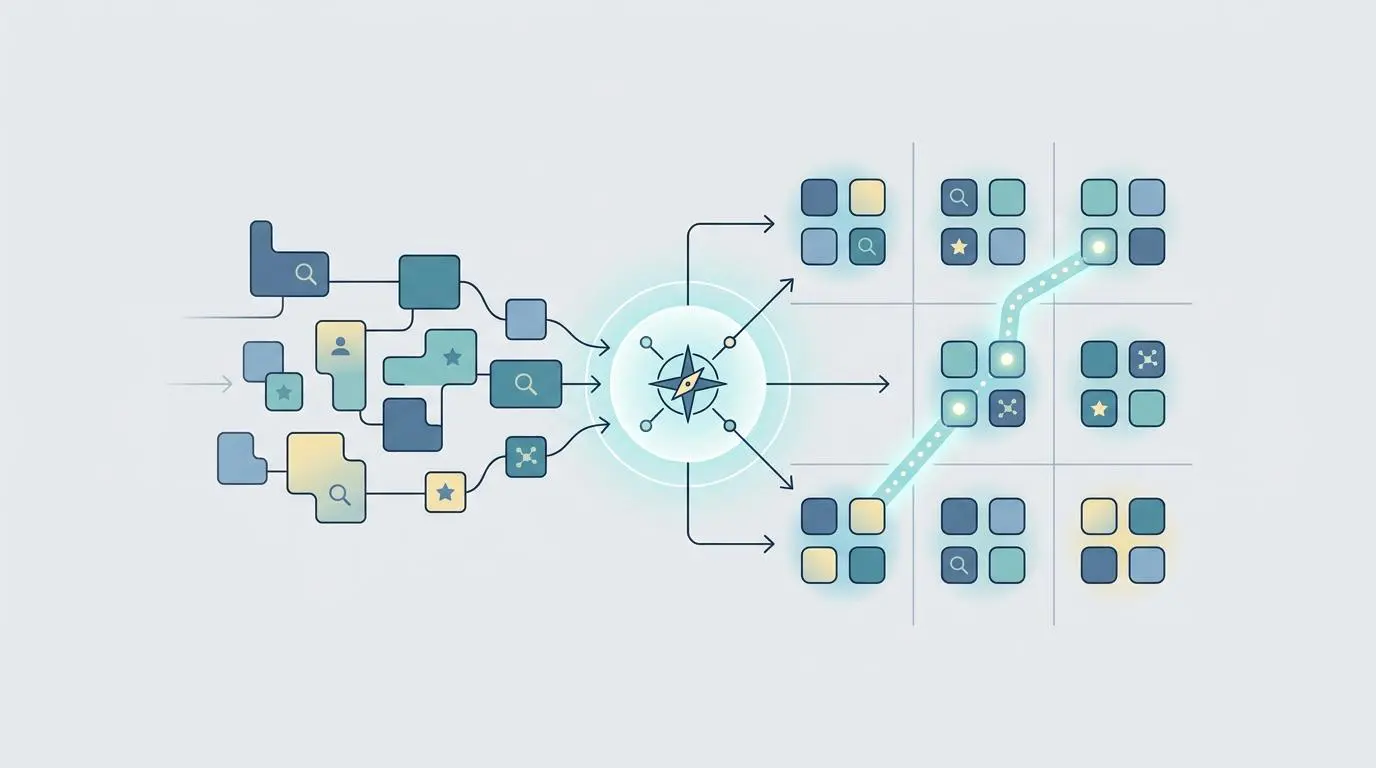
Retrieval-Augmented Generation relies on highly specific contextual windows to pull accurate information from vector databases. The deployment of Google’s Pathfinder algorithm in 2026 directly rewards this structural semantic completeness.
Semantic Completeness has emerged as the most powerful generative ranking factor with a correlation coefficient of r=0.87. Content that scores 8.5/10 on completeness is 4.2 times more likely to be cited in AI Overviews than content optimized for keyword density.
To capitalize on this, architects must move toward 150-word answer chunks. These dense, highly specific micro-documents perfectly satisfy RAG retrieval windows without overwhelming the model’s token limit.
Long-form content is increasingly suffering from semantic drift in modern LLM ingestion pipelines. This occurs when LLMs fail to attribute facts correctly because key entities are separated by too many non-authoritative tokens.
When an LLM chunks a sprawling article, the distance between the core entity and the supporting fact often exceeds the vector threshold. The resulting embedding loses its specific brand attribution.
By implementing semantic chunking, you isolate core concepts into easily digestible vectors. Each chunk acts as a standalone knowledge payload with its own distinct semantic signature.
This ensures that the LLM retrieves the exact payload needed for accurate brand attribution. It transforms your content library from a traditional text document into a precision-engineered vector database.
Knowledge Graph Automation and Entity Resolution
Entity resolution is the backbone of trust in the generative search ecosystem. Search engine algorithms now rely heavily on deterministic knowledge graphs to disambiguate brands, products, and abstract concepts.
Forward-thinking teams are utilizing Diffbot Knowledge Graph APIs for automated entity mapping. This process creates a machine-readable layer of truth that LLMs can query with absolute confidence.
Coupled with Wikidata 2026 RDF injection, this strategy stabilizes brand disambiguation deep within the LLM latent space. By injecting RDF triples into Wikidata, you are essentially hardcoding your brand’s relationships into the foundational training data.
This creates a permanent, undeniable mathematical link between your brand entity and its core competencies. Without this mathematical validation, an LLM treats your brand name as just another string of probabilistic text.
The real-world friction here is severe for entities lacking this structured validation. Brands with ambiguous names or weak entity-schema mapping are being actively suppressed by the algorithms.
These brands are being filtered out by trust filters in Perplexity and ChatGPT Search. Even if they possess high traditional domain authority, the lack of graph validation renders them untrustworthy to the AI.
Automating this resolution process bridges the gap between unstructured web text and structured AI comprehension. It is the ultimate technical safeguard against algorithmic erasure.
Agentic Crawler Management and Protocol Alignment
The crawling landscape has fractured into highly specialized, agentic bots. The rise of OAI-SearchBot and ClaudeBot as distinct entities requires a completely new approach to bot management and server routing.
Traditional robots.txt files were designed for indexers that map the web, not synthesizers that consume it. We are now seeing the introduction of ‘llms.txt’ as a semi-structured communication protocol specifically built for LLM ingestion control.
This new protocol allows site owners to direct agentic crawlers to the most semantically dense, RAG-friendly content. It prevents bots from wasting valuable crawl budget on boilerplate HTML or redundant product pages.
As previously noted, legacy CDN rules are inadvertently blocking these crucial modern crawlers. Security teams often misclassify agentic bots as aggressive scrapers or DDoS threats.
This misclassification cuts off the brand from the AI Citation Economy entirely. If the bot cannot read the payload, the LLM cannot cache the entity.
Engineering and SEO teams must collaborate to whitelist these specific user agents at the edge layer. Implementing specialized routing for AI crawlers ensures your data is ingested cleanly and continuously.
Advanced architectures are now serving distinct, markdown-optimized payloads directly to these bots via edge workers. This edge-level negotiation guarantees that the LLM receives the highest-fidelity version of your data without the overhead of CSS or JavaScript execution.
The 2027 Horizon of Agentic Negotiation
By 2027, the concept of search will evolve entirely into agentic negotiation. AI Discovery Protocols will allow personal AI agents to query brand-owned APIs directly, eliminating the middleman of the search engine interface.
This shift will bypass traditional HTML-based search result pages entirely. Real-time inventory, pricing, and complex entity data will be negotiated machine-to-machine in milliseconds.
Brands that fail to structure their data for Generative Search Ranking Signal Weights today will be locked out of this autonomous future. The time to architect your semantic foundation and deploy RAG-friendly content is right now.
The transition from visual web pages to machine-readable knowledge endpoints is not just an SEO tactic; it is a fundamental business survival strategy. Those who master this alignment will dominate the next decade of discovery.
Navigating the intersection of Generative Engine Optimization, AI Search architecture, and workflow automation requires a sharp strategy. To future-proof your brand’s visibility in LLMs and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is the citation disconnect in AI search?
The citation disconnect refers to the phenomenon where traditional high-ranking organic pages are excluded from AI-generated synthesis. This occurs because modern LLMs prioritize mathematical context and generative search ranking signals over legacy metrics like PageRank and keyword density.
Why do traditional SEO rankings fail to appear in AI Overviews?
Data indicates only a 17% overlap between traditional top-10 rankings and AI sources. LLMs bypass vanity metrics like backlink profiles in favor of semantic density, factual consensus, and entity validation, rendering traditional SEO strategies insufficient for AI visibility.
How does semantic chunking improve AI retrieval?
Semantic chunking breaks content into 150-word segments to satisfy Retrieval-Augmented Generation (RAG) windows. This prevents semantic drift and ensures that entities and their supporting facts remain mathematically linked within the model’s high-dimensional vector space.
What are the technical requirements for content grounding in Vertex AI?
To support real-time grounding, sites must minimize technical friction by implementing server-side rendering and flattened DOM trees. These optimizations ensure rapid token extraction and help content meet the strict latency thresholds required by the Vertex AI Grounding API.
What role does the llms.txt protocol play in bot management?
The llms.txt protocol is a semi-structured standard that directs agentic crawlers like OAI-SearchBot to semantically dense, RAG-friendly content. It helps prevent crawl budget waste on redundant HTML and ensures that AI models ingest the most authoritative data payloads.