Key Points
- CMS Desynchronization: Conflicts between WordPress core visibility settings and SEO plugin sitemap generation create contradictory indexing directives.
- Server-Level Overrides: Staging environment security headers migrating to production can silently override page-level meta tags.
- Cache Validation: Persistent object caching without automatic post-save purging serves stale robots metadata to crawlers, requiring rigorous HTTP header auditing.
Table of Contents
The Core Conflict: Sitemap Directives vs. Meta Constraints
A recent technical SEO study indicates that approximately 10.6% of websites have at least one page in their submitted XML sitemap explicitly marked ‘noindex’. This staggering metric highlights a severe depletion of crawl efficiency on enterprise-scale domains.
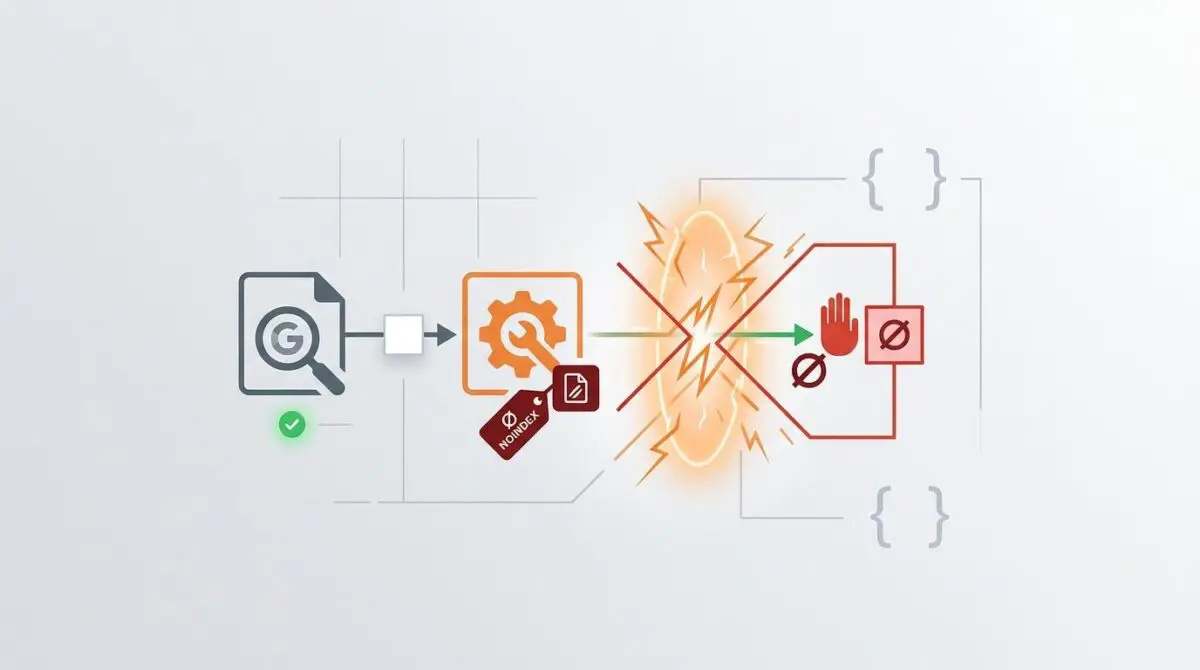
At the heart of this issue is the ‘Submitted URL marked noindex’ error. This anomaly occurs when a URL included in an XML sitemap contains a contradictory noindex directive in its HTML meta tags or HTTP response headers.
This creates a strict logical contradiction for Googlebot. The sitemap requests priority inclusion, while the page-level directive strictly forbids indexing.
Consequently, Googlebot is forced to fetch, parse, and render the page only to discover it cannot be indexed. This wastes critical crawl budget and delays the discovery of high-value content across your server.
From a Generative Engine Optimization perspective, this error is catastrophic. Generative engines and LLM-based crawlers prioritize sitemap-listed URLs for their initial training sets.
When a core landing page is excluded via a rogue noindex tag, it is effectively purged from the Knowledge Graph. This prevents the brand from appearing in AI-generated responses and citations.
Diagnostic Checkpoints: Isolating the Desync
This error is fundamentally a desynchronization within your technical stack. It manifests in the Google Search Console Indexing report under the Excluded category.
In raw server logs, you will observe crawlers requesting these URLs with a 200 OK status code. However, the rendered page displays a noindex meta tag, or a terminal request reveals an X-Robots-Tag entry.
Diagnostic Checkpoints
SEO Plugin & WP Core Global Conflict
WP Reading settings conflict with SEO plugin sitemaps.
Server-Level X-Robots-Tag Injection
Server headers override page-level meta robots tags.
Database Transient & Cache Desync
Stale cache serves outdated database robots metadata.
Category/Tag Archive Logical Loop
Empty archives trigger logical conflicts between plugin modules.
CMS and Server-Level Conflicts
The most common culprit is a global conflict between the CMS core and the SEO plugin. For instance, if the WordPress ‘Discourage search engines’ setting is active, it injects a global noindex directive.
If the SEO plugin generates a sitemap but fails to override this core database option, the sitemap lists actively blocked URLs. You can often see developers resolving this exact conflict in popular SEO plugins by carefully untangling these visibility settings.
Server-level injections also play a critical role in this desynchronization. Security headers in NGINX or Apache might force an X-Robots-Tag during staging or UAT phases.
If these environment-specific rules migrate to production via a configuration file, they will override any page-level meta tags set by the SEO plugin.
Database and Archive Loops
Database transient and cache desynchronization can serve stale robots directives to search engines. If a page’s indexability status changes but the object cache retains the old header state, crawlers receive contradictory signals.
The sitemap queries the database directly, while the crawler hits the stale cached page.
Category and tag archive logical loops present another layer of complexity. Many SEO plugins allow noindex for empty archives to save crawl budget.
If a category is empty, it may be marked noindex by the plugin logic. However, it might still be included in the XML sitemap because the generator does not perform a real-time count of posts assigned to that term.
Engineering Resolution Roadmap
Resolving this conflict requires a systematic approach to align your CMS database, plugin logic, and server configurations. You must trace the directive from the database layer all the way to the edge server.
Engineering Resolution Roadmap
Identify and Cross-Reference URLs
Export the list of affected URLs from the GSC Indexing report. Compare this list against your XML sitemap (usually found at /sitemap_index.xml) to confirm which sitemap file is the source of the contradiction.
Audit HTTP Response Headers
Run ‘curl -I https://example.com/affected-url’ in your terminal. Look for the ‘X-Robots-Tag’. If present, check your .htaccess, nginx.conf, or Cloudflare Transform Rules to locate and remove the directive.
Synchronize CMS Visibility Settings
Navigate to WP Admin > Settings > Reading. Ensure ‘Discourage search engines from indexing this site’ is unchecked. Then, go to your SEO plugin settings (e.g., RankMath > Titles & Meta) and ensure the specific Post Type is set to ‘Index’.
Rebuild Sitemap and Purge Cache
In your SEO plugin, toggle the Sitemap functionality off and back on to force a rebuild of the XML file. Flush all server-side caches (Nginx FastCGI, Redis, and CDN) to ensure Googlebot receives the updated headers and content.
Contextualizing the Fix
Identifying and cross-referencing URLs is the mandatory first step in troubleshooting. Exporting the GSC Indexing report allows you to pinpoint the exact sitemap generating the contradiction.
Auditing HTTP response headers ensures that no hidden server-level directives are overriding your application layer.
This is where terminal commands become invaluable for bypassing browser cache and CDN layers. Synchronizing CMS visibility settings ensures the database truth matches your intended SEO strategy.
Rebuilding the sitemap and purging all server-side caches guarantees that Googlebot receives the updated payload during its next crawl.
Resolution Execution: Programmatic Overrides
While UI toggles resolve basic conflicts, enterprise environments often require programmatic enforcement. This ensures that metadata and sitemap generation logic remain perfectly coupled at all times.
If you need to programmatically exclude noindexed pages from sitemaps in headless builds or custom WordPress setups, you must intervene at the hook level.
Fixing via WordPress Hooks
You can explicitly define robots directives using the wp_robots filter to prevent rogue post meta from slipping into the sitemap without the corresponding on-page tag.
add_filter( 'wp_robots', function( $robots ) { if ( is_singular() && get_post_meta( get_the_ID(), '_example_seo_noindex_key', true ) ) { $robots['noindex'] = true; } return $robots; }, 999 );Validation Protocol & Edge Cases
Implementing the fix is only half the battle. You must rigorously validate the output to ensure the desynchronization is fully resolved across all caching layers.
Search engines will not drop the error until the next successful crawl validates the clean headers.
Validation Protocol
- Use the Google Search Console ‘URL Inspection Tool’ to check if ‘noindex’ persists.
- Verify that Response Headers in Chrome DevTools lack the X-Robots-Tag.
- Confirm that rendered HTML in Rich Result Test contains no ‘noindex’ meta.
Edge Case Anomalies
A complex edge case involves Cloudflare Edge Workers or Varnish VCL rules. These are sometimes configured to serve noindex headers based strictly on the User-Agent string.
If a rule incorrectly scopes Googlebot while excluding standard browser agents, the site appears perfectly fine to developers testing in Chrome.
However, GSC will persistently report noindex errors. This happens because the edge server targets the crawler with a uniquely restrictive header configuration.
You must audit your Cloudflare Transform Rules and Varnish logic to ensure crawler parity with standard user agents.
Autonomous Monitoring & Prevention
Manual audits are insufficient for enterprise-scale domains. Preventing this error requires proactive, autonomous monitoring systems integrated directly into your deployment pipeline.
Implement a pre-deployment crawl audit using tools like Screaming Frog or Sitebulb.
This scans the XML sitemap for any URLs returning a noindex status before merging to production. Set up a server-side monitor or a GitHub Action that runs a cURL check against critical landing pages.
This verifies the absence of noindex headers programmatically during the CI/CD process.
Leveraging platforms like Make.com allows you to build custom API alerts that trigger the moment a core entity drops from the index.
A deep dive into an Ahrefs SEO statistics study reveals that automated pipeline monitoring drastically reduces time-to-resolution for these specific indexing anomalies.
At Andres SEO Expert, we architect these precise automated safeguards to ensure your entity integrity remains uncompromised.
Conclusion
The ‘Submitted URL marked noindex’ error is a critical roadblock for both traditional crawling and generative AI ingestion. By aligning your CMS settings, server headers, and caching layers, you restore logical harmony to your indexing directives.
Execute the diagnostic checkpoints, apply the necessary programmatic overrides, and validate your headers relentlessly.
Navigating the intersection of technical SEO, server architecture, and generative search requires a precise roadmap. If you need to future-proof your enterprise stack, resolve deep-level crawl anomalies, or implement AI-driven SEO automation, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What does the “Submitted URL marked noindex” error mean?
This error occurs when a URL included in your XML sitemap contains a contradictory directive in its HTML meta tags or HTTP response headers that tells search engines not to index the page. This logical conflict forces search engines to crawl pages they cannot use, wasting crawl budget and harming site efficiency.
How does the noindex sitemap error impact Generative AI and LLMs?
From a GEO (Generative Engine Optimization) perspective, this error is critical because LLM-based crawlers prioritize sitemap-listed URLs for their training sets. If a core page is marked noindex, it is effectively purged from the Knowledge Graph, preventing your brand from appearing in AI-generated responses and citations.
Can WordPress settings cause a submitted URL marked noindex conflict?
Yes, global CMS settings such as the WordPress ‘Discourage search engines from indexing this site’ option can inject site-wide noindex tags. If an SEO plugin generates a sitemap while this core setting is active, it creates a direct conflict between the sitemap directives and the site visibility settings.
How do I check for hidden server-level noindex directives?
You can identify hidden directives by auditing HTTP response headers. Use a terminal command like ‘curl -I [URL]’ to look for an ‘X-Robots-Tag’. These are often injected by server configurations in NGINX, Apache, or Cloudflare Edge Workers and can override on-page meta tags.
Why are empty category archives causing indexing errors?
Many SEO plugins automatically apply a noindex tag to empty archive pages to preserve crawl budget. However, because sitemap generators do not always perform real-time post counts, they may still include these empty categories in the XML sitemap, triggering the ‘submitted URL marked noindex’ error.
What is the best way to prevent indexing conflicts in enterprise environments?
Enterprise domains should implement autonomous monitoring within their CI/CD pipelines. This includes using pre-deployment crawl audits to scan XML sitemaps for noindex statuses and setting up server-side monitors to verify the absence of restrictive headers before code merges to production.