Key Points
- Entity Disambiguation Failure: Legacy @id URIs and stale object caching force the Knowledge Vault to maintain split entities, returning legacy IDs despite on-page updates.
- Resolution Protocol: Explicitly remap the new canonical URL via JSON-LD, update Wikidata P1366 properties, and trigger a GSC Change of Address to merge entity signals.
- Validation Execution: Execute cURL requests against the Knowledge Graph Search API to verify the new resultScore and confirm authoritative entity reconciliation.
Table of Contents
The Core Conflict: Entity Disambiguation Failure
According to a technical SEO study by Milestone Research, entity-based search optimization can increase organic click-through rates by up to 30% for branded queries. Proper alignment of your corporate identity is critical for search visibility. When a corporate entity rebrands, a severe technical conflict known as Knowledge Graph Entity ID Disambiguation often occurs.
Knowledge Graph Entity ID Disambiguation is the process by which Google’s Reconciliation Engine maps unstructured and structured data to a unique Machine-Readable Entity ID (MREID). During a rebrand, the Knowledge Vault may maintain a legacy mapping between the brand’s topic and its previous identifiers. This results in a split entity state where the API returns a legacy ID despite updated on-page metadata.
The primary symptom is the Google Knowledge Graph Search API returning a result score lower than 100 for the new brand name. In raw server logs, this manifests as Googlebot performing high-frequency crawls on legacy URLs that have been redirected. Despite valid schema enhancements in Google Search Console, the Knowledge Panel UI fails to update.
Diagnostic Checkpoints: Identifying the Disconnect
This error is fundamentally a desynchronization across your server, cache, and semantic web layers. The Knowledge Graph requires absolute consensus to assign high confidence scores.
Diagnostic Checkpoints
Stale Linked Data URI Mismatch
Legacy @id URIs create duplicate or mismatched entity records.
Asynchronous Wikidata/DBpedia Reconciliation
Stale external RDF triples prevent Knowledge Vault updates.
Stale Object Cache in Schema Output
Server-side caching serves legacy brand metadata to Googlebot.
Redirection Loop of Authoritative Signals
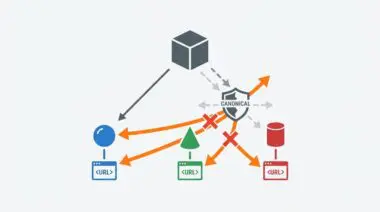
Missing sameAs links degrade new domain entity confidence.
Server and Cache Layer Issues
High-performance servers utilizing Redis or Memcached may store the generated JSON-LD block for the homepage. If the object cache isn’t flushed at the initialization level, Googlebot continues to scrape the old entity metadata. This forces the crawler to process conflicting signals during every visit.
Furthermore, incorrect redirection loops break the chain of entity trust. When rebranding involves a domain migration, failing to provide authoritative links to the old domain prevents Google from merging the entities. The API will subsequently treat the new domain as a low-confidence entity.
External RDF and URI Mismatches
Stale Linked Data URIs cause immense confusion for search crawlers. Google uses the ‘@id’ property as a persistent identifier across the web. If a rebrand changes the canonical URL but the ‘@id’ remains the old URL, the graph defaults to the older ID. This directly violates the W3C specification for JSON-LD persistent URIs.
Additionally, Google’s Knowledge Vault relies heavily on external RDF triples from Wikidata. If the official website property on the Wikidata Q-item isn’t updated, the API surfaces the legacy ID. This creates a manual discrepancy between your site identity and the global Linked Open Data cloud.
The Engineering Resolution Roadmap
Resolving this disambiguation requires a multi-layered engineering approach. You must force the reconciliation engine to process the new entity data.
Engineering Resolution Roadmap
Explicit Entity Mapping via JSON-LD
Inject a specific ‘Organization’ schema into the WordPress header. Explicitly define the ‘@id’ as the new canonical URL and use the ‘sameAs’ array to include the legacy domain and the specific Wikidata Q-item ID.
Wikidata Statement Update
Navigate to the Wikidata item for the legacy entity. Add a ‘replaced by’ (P1366) property pointing to the new entity entry, or update the ‘official website’ (P856) and ‘named as’ properties to the new brand.
Google Search Console ‘Change of Address’
Use the Google Search Console Change of Address tool if the rebrand involved a domain move. This signals the Knowledge Graph to transfer the ‘authority’ signals from the old MREID to the new one.
API Request for Entity Re-evaluation
Use the Knowledge Graph Search API ‘Feedback’ mechanism or the ‘Suggest an Edit’ feature on the Knowledge Panel while logged into a verified GSC account to trigger a manual reconciliation queue.
You must explicitly define the ‘@id’ as the new canonical URL. This establishes a new source of truth for the crawler. It also utilizes the schema.org sameAs property for entity reconciliation to bridge the gap between old and new identities.
Executing the JSON-LD Fix
To execute this fix, you must update the JSON-LD payload injected into your header. Ensure the ‘@id’ matches the new brand URL exactly. Include the legacy domain and the specific Wikidata Q-item ID in the sameAs array.
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://newbrand.com/#organization",
"name": "New Brand Name",
"url": "https://newbrand.com",
"logo": "https://newbrand.com/logo.png",
"sameAs": [
"https://twitter.com/newbrand",
"https://www.wikidata.org/wiki/Q12345",
"https://oldbrand.com"
]
}Validation Protocol and Edge Cases
Once the JSON-LD is deployed and caches are cleared, immediate validation is required. You cannot rely on standard SERP checks to confirm entity resolution.
Validation Protocol
- Execute KG API cURL request to verify entity search returns.
- Validate resultScore and @id in the JSON API response.
- Run Rich Results Test to confirm indexed JSON-LD @id.
- Verify schema freshness via GSC Google-InspectionTool user-agent.
Use the Google Knowledge Graph Search API documentation to structure your cURL request. Check the ‘resultScore’ and ‘@id’ in the JSON response to ensure the new MREID is recognized.
Be aware of edge cases involving Cloudflare Edge Workers. A worker might programmatically inject a different JSON-LD block for specific user-agents. This leads to fragmented entity indexing where the SERP pulls the legacy ID from a cached edge fragment.
Autonomous Monitoring and Prevention
Preventing entity fragmentation requires an automated knowledge management pipeline. You should sync your site identity settings with an external Wikidata bridge automatically. This ensures your internal database and external RDF triples remain perfectly aligned.
Monitor the Knowledge Graph API continuously using a Python script or Make.com pipeline. This allows you to detect confidence score drops for your brand’s KGID in real-time. At Andres SEO Expert, we architect these precise automated safeguards for enterprise clients to ensure absolute entity integrity.
Conclusion
Resolving disambiguation errors requires strict alignment between your server configuration, schema markup, and external knowledge bases. By explicitly mapping your entities and validating the API output, you restore authoritative brand signals across the web.
Navigating the intersection of technical SEO, server architecture, and generative search requires a precise roadmap. If you need to future-proof your enterprise stack, resolve deep-level crawl anomalies, or implement AI-driven SEO automation, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is Knowledge Graph Entity ID Disambiguation?
Knowledge Graph Entity ID Disambiguation is the technical process where Google’s Reconciliation Engine maps structured and unstructured data to a unique Machine-Readable Entity ID (MREID). A failure in this process, common during rebranding, occurs when the Knowledge Vault maintains legacy mapping, resulting in a split entity state and reduced search visibility.
How do you diagnose a brand entity mismatch in search results?
You can identify a mismatch by checking the Google Knowledge Graph Search API for a result score lower than 100 for the new brand name. Other signs include Googlebot performing high-frequency crawls on redirected legacy URLs and the Knowledge Panel UI failing to reflect updated metadata from Google Search Console.
Why is the @id property in JSON-LD crucial for SEO rebranding?
The @id property serves as a persistent URI for an entity. According to W3C specifications, if the @id remains linked to a legacy URL after a rebrand, the Knowledge Graph will continue to default to the old entity record, preventing the authoritative signals from transferring to the new brand domain.
How does Wikidata influence Google Knowledge Graph updates?
Google’s Knowledge Vault relies on external RDF triples from databases like Wikidata. If the Wikidata Q-item for a brand is not updated with the new ‘official website’ or a ‘replaced by’ property, the Knowledge Graph API will surface legacy identifiers, creating a manual discrepancy in the Linked Open Data cloud.
What are the engineering steps to resolve entity fragmentation?
To resolve fragmentation, you must: 1. Inject ‘Organization’ schema with a new canonical @id. 2. Use the ‘sameAs’ array to link legacy domains and Wikidata IDs. 3. Update Wikidata statements. 4. Use the Google Search Console Change of Address tool. 5. Trigger manual reconciliation via the Knowledge Graph API feedback mechanism.
How can technical teams validate that an entity has been reconciled?
Validation requires executing a cURL request to the Knowledge Graph Search API to verify that the @id and resultScore are correct. Additionally, teams should run a Rich Results Test to confirm the indexed JSON-LD @id and use the Google-InspectionTool user-agent in GSC to verify schema freshness.