Key Points
- Crawl Budget Exhaustion: Auto-generated taxonomy pages create massive URI bloat, forcing Googlebot to waste resources rendering duplicate, low-value archives instead of primary pillar content.
- AI Search Suppression: Large Language Models crawling for RAG grounding struggle with the noise of near-empty tag pages, leading to hallucination-prone indexing and a drop in Generative Engine Optimization (GEO) visibility.
- Server-Level Directives: Resolving the desync requires multi-layered engineering, including X-Robots-Tag NGINX headers, programmatic term pruning, and mitigating GraphQL metadata desyncs in headless architectures.
Table of Contents
The Core Conflict: Taxonomy Bloat vs. Crawl Efficiency
According to a 2025 technical SEO study by Botify, enterprise websites that aggressively prune low-value taxonomy pages see an average 28% increase in the crawl frequency of their primary pages within 30 days.
This metric underscores a critical vulnerability in modern server architecture. When a search engine’s rendering engine spends disproportionate resources on auto-generated tag or category pages, it triggers a cascade of indexing failures.
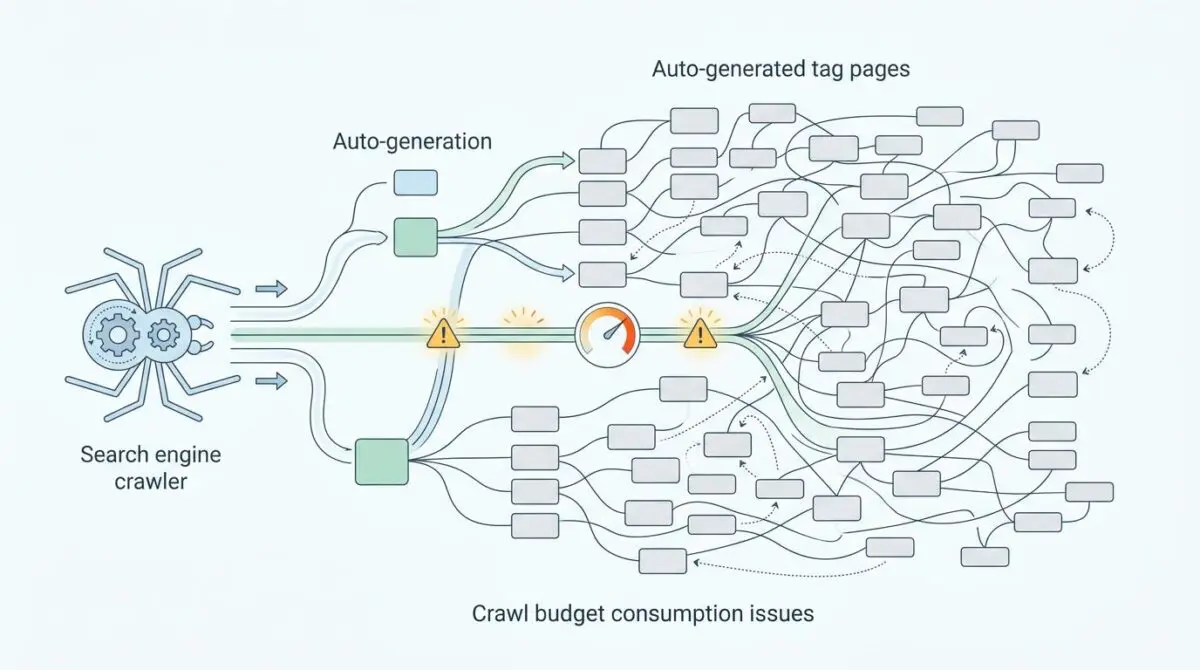
This phenomenon is known as Low-Value Taxonomy Crawl Bloat. It occurs when automated systems generate a 1:1 ratio between tags and posts, creating thousands of near-empty archive pages.
These pages lack unique content or intent-matching value.
In Google Search Console, this manifests as a massive spike in the ‘Crawled – currently not indexed’ status. Server log analysis will typically reveal high crawl frequencies for URIs with zero organic click conversion.
Search engine bots end up hitting these taxonomy archives more frequently than the actual revenue-generating articles.
From a Generative Engine Optimization perspective, these low-value pages create severe noise for Large Language Models. When an LLM crawls a site for RAG grounding, an abundance of near-empty tag pages results in hallucination-prone indexing.
By allowing these pages to be indexed, site owners increase crawl latency and lower the signal-to-noise ratio. This ultimately leads to site-wide suppression in AI-driven search results.
Diagnostic Checkpoints: Identifying the Desync
Taxonomy bloat is rarely a single point of failure. It is usually a desynchronization across the server layer, the edge cache, and the CMS application itself.
Diagnostic Checkpoints
Aggressive Plugin Sitemap Defaults
XML sitemaps prioritize discovery over natural internal linking signals.
Internal Link Equity Dilution
Hardcoded tag links signal false architectural importance to crawlers.
Database Transient Fragmentation
Unoptimized term queries increase TTFB and crawl budget loss.
Duplicate Content Canonical Conflicts
Identical archive structures trigger aggressive resource-saving crawl filters.
At the application layer, SEO plugins often default to aggressive XML sitemap generation. They submit every registered taxonomy directly to the Search Console API.
This forces a discovery priority on junk data, overriding natural crawl prioritization.
Simultaneously, themes hardcode tag clouds or metadata sections into the bottom of every post. This creates a massive web of internal dofollow links pointing to low-value archives.
It sends a false signal to bots that these pages are architecturally significant.
At the database layer, WordPress stores taxonomy counts as transients. When thousands of tags are generated, the database queries required to resolve these archives become painfully slow.
If a bot hits these pages and the TTFB exceeds two seconds due to unoptimized JOIN queries, the crawl budget is heavily penalized.
Finally, duplicate content canonical conflicts arise because auto-generated tag pages display the exact same post snippets as category feeds. Without unique introductory text, the HTML structure is nearly identical.
As search engine guidelines explicitly state, an overabundance of low-value-add URLs can negatively affect a site’s crawling efficiency.
The Engineering Resolution Roadmap
Resolving this crawl anomaly requires a multi-layered approach. You must sever the discovery pathways while preserving the flow of internal link equity.
Engineering Resolution Roadmap
Implement X-Robots-Tag via Server Config
Modify the NGINX or .htaccess file to send a ‘noindex, follow’ header specifically for the /tag/ subdirectory. This stops indexing while allowing bots to pass link equity through to the posts.
Disable Taxonomy Sitemaps
Navigate to SEO > Sitemap Settings in the WordPress dashboard. Toggle ‘Tags’ to ‘Off’. Ensure the ‘sitemap-tags.xml’ returns a 404 status to signal to Search Console that the resource is deprecated.
Programmatic Term Pruning
Run a SQL query or use a plugin like ‘Term Management Tools’ to delete any tags associated with fewer than 3 posts. This reduces the number of URIs the bot needs to process.
Modify Internal Link Attributes
Update the theme’s ‘single.php’ template. Replace the standard tag output with a custom function that adds ‘rel=”nofollow”‘ to all taxonomy archive links.
The first phase involves direct server configuration to issue strict directives. By implementing an X-Robots-Tag header at the NGINX or Apache level, you stop indexing immediately.
This is far more efficient than relying on application-level meta tags.
Next, you must deprecate the discovery mechanisms. Disabling taxonomy sitemaps and ensuring they return a 404 status code signals to search engines that the resource is permanently gone.
This is a crucial step in trimming “dead wood” pages to allow crawlers to move through your site with agility.
Programmatic term pruning cleans up the database fragmentation. Deleting tags associated with fewer than three posts drastically reduces the URI count.
Finally, modifying internal link attributes in the theme template prevents bots from infinitely crawling these dead-end paths.
Resolution Execution: Server & Application Layer
Executing this fix requires surgical modifications to both your server configuration and your WordPress theme logic. Do not rely solely on SEO plugin toggles, as they often fail to process edge-cached responses.
Fixing via WordPress and Server Configuration
The most robust method is to combine a WordPress action hook with a server-level override. The application layer handles the standard meta output, while the server block acts as a fail-safe.
add_action('wp_head', function() { if (is_tag()) { echo ''; } }); /* Alternative NGINX block */ /* location ~* /tag/.* { */ /* add_header X-Robots-Tag "noindex, follow"; */ /* } */Validation Protocol & Edge Cases
Implementation is only half the battle. You must rigorously validate the headers to ensure edge caches or CDNs are not stripping your directives.
Validation Protocol
- Execute curl -I command to verify X-Robots-Tag headers.
- Perform GSC Live Test to confirm ‘noindex’ visibility.
- Monitor GSC Crawl Stats for reduced taxonomy request volume.
Headless WordPress architectures present a unique and dangerous edge case. In a decoupled setup using Next.js or Nuxt, a severe metadata desync can occur.
The WordPress backend might correctly set a noindex directive for the tag archive. However, if the frontend fetches data via GraphQL and renders the page with default index meta tags, the bot sees an indexable page.
Resolving this requires explicit mapping. You must ensure the SEO metadata is explicitly passed through the GraphQL query and injected directly into the frontend head component.
Autonomous Monitoring & Prevention
Preventing taxonomy bloat requires shifting from reactive cleanup to proactive governance. Establish a strict Editorial Taxonomy Governance policy.
In this model, tags can only be created by system administrators or senior editors, completely locking out standard authors. This stops the exponential growth of one-off tags at the source.
For enterprise environments, implement a CI/CD check or a GitHub Action that scans the XML sitemap for unexpected taxonomy bloat before any deployment. Pair this with server-side log monitoring using the ELK Stack or Loggly.
Configure custom alerts to trigger when bot hits on the /tag/ directory exceed ten percent of your total crawl volume.
At Andres SEO Expert, we heavily utilize these advanced automation pipelines to monitor entity integrity and protect enterprise crawl budgets.
Conclusion
Low-Value Taxonomy Crawl Bloat is a silent killer of technical SEO performance. By implementing strict server-side directives, pruning database transients, and monitoring edge-case rendering, you can reclaim your crawl budget.
Navigating the intersection of technical SEO, server architecture, and generative search requires a precise roadmap. If you need to future-proof your enterprise stack, resolve deep-level crawl anomalies, or implement AI-driven SEO automation, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is low-value taxonomy crawl bloat?
Low-value taxonomy crawl bloat occurs when automated systems or plugins generate thousands of near-empty tag and category archive pages. This creates a high ratio of archive pages to unique content, leading to indexing failures and inefficient resource allocation by search engine crawlers.
How does taxonomy bloat impact a website’s crawl budget?
When crawlers spend resources on thousands of low-value taxonomy URLs, they hit “dead wood” pages more frequently than revenue-generating articles. This triggers crawl latency and penalizes the crawl budget, often resulting in primary content remaining unindexed.
Why should I use X-Robots-Tag instead of standard meta tags for taxonomy pages?
Using the X-Robots-Tag via server configuration (NGINX or .htaccess) is more efficient than application-level meta tags. It allows the server to issue a “noindex, follow” directive immediately, which is more reliable for edge-cached responses and reduces processing load on the CMS.
What are the primary diagnostic signs of taxonomy-related SEO issues?
Key indicators include a massive spike in “Crawled – currently not indexed” status within Google Search Console, high TTFB (Time to First Byte) on archive URIs due to unoptimized database queries, and server logs showing frequent bot hits on tags with zero organic click conversion.
How do low-value archive pages affect AI-driven search results and LLMs?
In Generative Engine Optimization (GEO), an abundance of thin taxonomy pages increases noise for Large Language Models during RAG (Retrieval-Augmented Generation) grounding. This can lead to hallucination-prone indexing and site-wide suppression in AI-driven search results.
How can headless WordPress architectures cause metadata desynchronization?
In a headless setup using Next.js or Nuxt, the WordPress backend might set a noindex directive, but if the frontend fetches data via GraphQL without explicitly mapping that SEO metadata, the frontend may render the page as indexable, confusing search bots.