

Key Points
- Automated Data Injection: Integrating synthetic data generation directly into CI/CD pipelines eliminates the 48-hour staging stagnation bottleneck.
- Zero-Risk Compliance: Utilizing Generative Adversarial Networks (GANs) ensures mathematically valid test data without exposing production PII.
- Autonomous Schema Adaptation: AI agents dynamically monitor database deployments to instantly update data generation scripts and prevent schema drift.
Table of Contents
- The Invisible Cost of Stale Staging Environments
- Data-Backed Realities of Modern Deployment Pipelines
- Eradicating the Daily Friction of Manual Data Seeding
- Fortifying Security and Privacy Compliance
- Autonomous AI Agents and Schema Drift Prevention
- Orchestrating High-Speed Data Synchronization
- Measuring ROI and Reclaiming Engineering Hours
- The Horizon of Self-Healing Testbeds
- Pioneering the Next Era of Deployment Automation
The Invisible Cost of Stale Staging Environments
The invisible tax of manual data management is quietly suffocating deployment velocity. Every time a developer pushes code, an unseen clock starts ticking. Highly paid engineers sit idle while database administrators scrub, mask, and port production data into non-production environments.
This manual data seeding creates a massive bottleneck known as staging stagnation. Instead of rapid iteration, deployment velocity is crippled by the sheer logistical weight of preparing test environments.
Relying on manual processes also introduces severe legal risks associated with using production personally identifiable information in testing zones. When human error inevitably occurs, the exposure of sensitive data can trigger catastrophic compliance violations.
The definitive solution to reclaim this lost time and eliminate privacy debt is AI-driven CI/CD synthetic data orchestration. By automating the instant generation of synthetic test data triggered by real-time staging deployments, engineering teams can test faster, deploy safer, and scale without friction.
Data-Backed Realities of Modern Deployment Pipelines
Market Intelligence & Data
Compliance Mandate Adoption
According to a 2025 Deloitte survey, 92% of enterprise DevOps teams now mandate synthetic data for staging to avoid the $4.8M average cost of a production-data leak.
Reduction in Lead Time
The 2025 State of DevOps report by DORA confirms that teams using automated synthetic data generation see a 60% reduction in lead time for software changes.
Projected Market Valuation
IDC forecasts the global AI-synthetic data market will reach $12.4 billion by the end of 2026, driven by the surge in LLM fine-tuning and secure testing needs.
Weekly Labor Reclaimed
A 2026 IEEE software engineering study demonstrated that senior QA engineers reclaim 14 hours per week when data seeding is triggered automatically by staging deployments.
The financial and legal repercussions of mishandling test environments have reached an absolute tipping point for modern enterprises. The vast majority of DevOps teams are now enforcing strict synthetic data mandates. This shift completely bypasses the multi-million dollar penalties associated with accidental production data leaks.
Beyond securing sensitive information, the sheer speed of software delivery is being fundamentally transformed by automated testing workflows. The State of DevOps report by DORA confirms that organizations adopting these synthetic generation strategies experience a dramatic reduction in the lead time required for software changes.
Recognizing this massive operational shift, financial markets are aggressively backing intelligent data generation platforms to support enterprise infrastructure. Industry analysts project the global market for these AI-driven testing tools will explode over the next few years. This growth is heavily driven by the necessity of secure LLM fine-tuning.
The human impact of this automation is perhaps the most compelling metric for engineering leadership looking to optimize their workforce. Efficiency is drastically amplified when modern data tools are integrated directly into GitHub Actions and GitLab CI/CD. This integration creates a seamless, zero-touch deployment pipeline.
Eradicating the Daily Friction of Manual Data Seeding
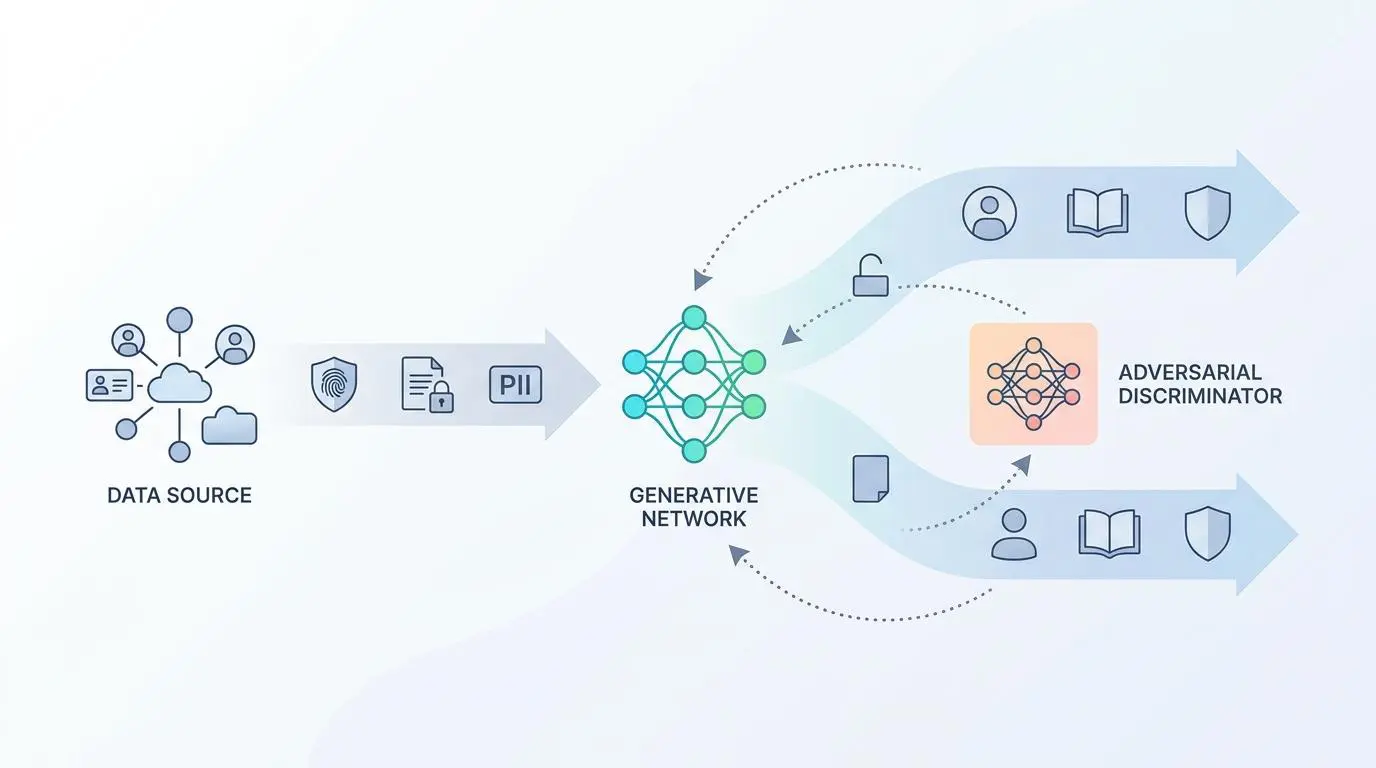
Developers currently waste up to a third of their sprint cycles manually crafting complex SQL scripts or attempting to clean old data dumps for staging servers. This tedious process drains creative energy and diverts focus away from shipping core product features.
DevOps teams frequently find their staging environments becoming completely stale or dirty within just 48 hours of a manual refresh. This degradation leads directly to false-positive test results. It confuses developers and causes late-stage deployment failures that could have been easily avoided.
By orchestrating synthetic data generation within the continuous integration pipeline, these environments are refreshed instantly and flawlessly upon every deployment. This ensures that every single pull request is tested against pristine, mathematically accurate datasets without requiring any human intervention.
Fortifying Security and Privacy Compliance

With the strict 2025 updates to global privacy frameworks, utilizing actual production data in staging environments without irreversible masking is now classified as a critical compliance violation. Regulators are actively penalizing companies that fail to isolate their testing zones from live user data.
Manual masking techniques frequently miss edge-case fields, nested JSON objects, or hidden log files, creating a massive privacy debt. This oversight leaves organizations highly vulnerable to devastating audits and massive fines under GDPR and CCPA regulations.
Modern synthetic data generation leverages generative adversarial networks to create entirely fake identities that are mathematically valid but contain zero real-world information. This approach completely severs the link to actual users while maintaining the complex statistical distribution required for rigorous software testing.
Autonomous AI Agents and Schema Drift Prevention
When a developer adds a new column or alters a relationship in a database, traditional manual test data scripts break instantly. This fragility forces database administrators to constantly rewrite data generation rules, slowing down the entire engineering department.
Today, cognitive agents utilizing advanced API wrappers actively crawl database schemas at the exact moment of deployment to detect any structural changes. These intelligent agents autonomously identify schema drift and instantly adapt to the new architectural realities.
Once a structural change is detected, the AI agents autonomously update the data-generation prompts in real-time to match the new schema. This self-correcting loop ensures that the synthetic data generator never fails, regardless of how drastically the underlying database architecture evolves.
Orchestrating High-Speed Data Synchronization

Traditional ETL processes for moving test data are entirely too slow for the continuous deployment era. They often take hours to port information when developers need it in minutes. This latency completely breaks the agile feedback loop required by high-performing engineering teams.
Modern pipelines utilize advanced orchestration tools to manage a streamlined clean, generate, and inject workflow. As soon as a staging server is provisioned, a webhook triggers an automated sequence that immediately calls the synthetic data API.
This automated flow can securely stream massive volumes of relational data via encrypted tunnels directly into the new environment. A 2025 study by the DevOps Institute revealed that referential integrity AI has achieved 99.9% accuracy in maintaining complex multi-cloud database relationships in synthetic sets. This effectively makes production clones obsolete for the vast majority of use cases.
Measuring ROI and Reclaiming Engineering Hours
The financial cost of idle time is staggering when dozens of developers are forced to wait for a database administrator to refresh a staging environment. For a medium-sized firm, this wasted labor can easily exceed tens of thousands of dollars every single month.
Enterprise teams utilizing automated synthetic generation report a massive increase in testing frequency. This allows them to catch critical bugs much earlier in the development lifecycle. Proactive testing drastically reduces the cost of fixing defects found in production.
While enterprise AI data tools require a monthly subscription investment, the operational savings are profound. These automated systems easily offset their costs by saving the equivalent of multiple full-time senior engineering salaries. This allows those experts to focus on revenue-generating architecture.
The Horizon of Self-Healing Testbeds
Looking toward late 2026, the industry is rapidly moving toward the concept of self-healing testbeds. In this paradigm, synthetic data is not just generated randomly. It is dynamically adjusted based on the specific code changes detected within a developer’s pull request.
Generic synthetic data often misses the highly specific edge cases required to thoroughly test a brand-new feature or complex logic branch. Future AI systems will literally read the proposed code changes. They will autonomously generate data specifically engineered to try and break that exact new logic.
This evolution will usher in an era of context-aware synthetic streams where AI agents continuously monitor production error logs in real-time. These agents will then generate matching failure-pattern data in staging environments. This allows teams to proactively hunt bugs before users ever experience an issue.
Pioneering the Next Era of Deployment Automation
The days of relying on manual data scrubbing and accepting the risks of stale staging environments are rapidly coming to an end. Embracing AI-driven orchestration transforms your deployment pipeline from a fragile bottleneck into a resilient, high-speed engine of innovation.
By completely removing human intervention from the data seeding process, engineering teams unlock unprecedented agility and ironclad compliance. The future belongs to organizations that treat test data not as a static asset, but as a dynamic, autonomous stream that adapts instantly to code changes.
Navigating the intersection of technology, workflows, and operational efficiency requires a sharp strategy. To future-proof your business architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is the invisible cost of stale staging environments?
Stale staging environments create a bottleneck known as Staging Stagnation, where manual data scrubbing and porting delay deployment velocity. This results in significant idle time for engineers and high legal risks if production PII is accidentally exposed in non-production zones.
How does AI-driven synthetic data improve CI/CD efficiency?
By orchestrating synthetic data generation directly within the CI/CD pipeline, organizations can achieve a 60% reduction in lead time for software changes. This automation ensures every pull request is tested against pristine, mathematically accurate datasets without manual intervention.
Is using production data for testing a compliance violation?
Under 2025 updates to global privacy frameworks like GDPR and CCPA, using actual production data in staging without irreversible masking is classified as a critical violation. Synthetic data eliminates this risk by using GANs to create fake identities that maintain statistical integrity without real user info.
How do AI agents handle database schema drift?
Cognitive agents use API wrappers to crawl database schemas at the moment of deployment. If structural changes like new columns or relationship shifts are detected, the AI autonomously updates the data-generation prompts in real-time to prevent pipeline failure.
What is the ROI of automated synthetic data orchestration?
Enterprise teams using automated synthetic generation reclaim an average of 14 hours of labor per week for senior engineers. The system pays for itself by increasing testing frequency, catching bugs earlier, and avoiding the average $4.8M cost of a production data leak.
What are self-healing testbeds in DevOps?
Self-healing testbeds are an emerging paradigm where AI reads a developer’s proposed code changes and generates specific edge-case data tailored to test that new logic. These systems can also monitor production error logs to recreate failure patterns in staging automatically.