Key Points
- Fan-Out Query Expansion: Voice queries trigger 2 to 5 silent background expansions in LLMs; failing to optimize for these latent vector clusters results in complete exclusion from AI Overviews.
- Semantic Chunking Architecture: Overcoming the conversational ‘Entropy Gap’ requires recursive character splitting at 400 tokens with a 100-token overlap to prevent severing question-reasoning intent from conclusions.
- Auditory Attribution Deficit: Voice assistants only read the first cited source aloud, rendering traditional top-10 rankings obsolete and demanding absolute primacy in the LLM context window.
Table of Contents
- The Invisible Cost of the Entropy Gap
- Quantifying the Voice-First Retrieval Shift
- Escaping the Citation Blackout in AI Overviews
- Semantic Chunking for Voice Context Retention
- Mapping Latent Fan-Out in Conversational Queries
- Automating Sentiment Injection to Counter Perception Drift
- The Post-Query Era of Anticipatory Agentic GEO
The Invisible Cost of the Entropy Gap
The harsh truth about modern search architecture is that perfectly structured vector databases are often deaf to natural human speech. While typed queries arrive in neat keyword packages, voice prompts in 2026 average nine to eleven words. These spoken requests are heavily laden with vague pronouns, conversational filler, and ambient noise fragments.
This creates a massive entropy gap between natural speech and the rigid vector-space requirements of traditional RAG pipelines. Current large language model retrieval systems frequently fail to map these messy conversational artifacts to relevant brand entities. The result is a catastrophic citation blackout for brands relying on legacy optimization.
High-authority pages are entirely ignored because their semantic chunks lack the natural prosody found in voice-first training sets. To bridge this divide, engineering teams must pivot toward conversational entity retrieval and Voice-to-Action optimization. This is not merely a content update, but a fundamental restructuring of how data is parsed, stored, and retrieved.
V2A optimization ensures that when a user mumbles a complex question into their smartwatch, the LLM instantly recognizes your brand as the definitive answer. Think of traditional keyword matching as a rigid train track. In contrast, conversational entity retrieval is an all-terrain vehicle capable of navigating the unpredictable landscape of human speech.
Quantifying the Voice-First Retrieval Shift
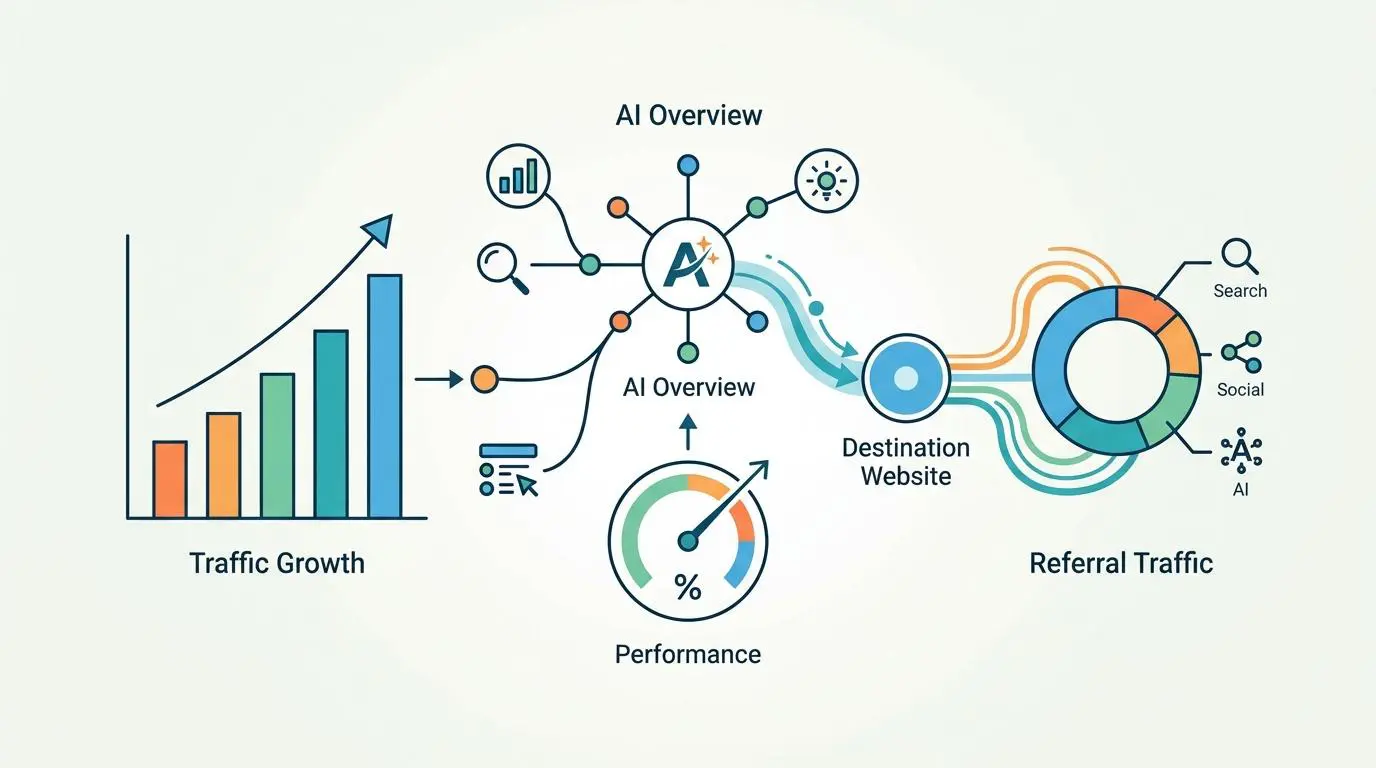
The transition from screen-based search to conversational retrieval is actively cannibalizing traditional organic traffic. We are witnessing a fundamental rewiring of user behavior driven by frictionless voice interfaces and highly capable multi-modal LLMs. The data points toward a future where visual search engine results pages are a secondary fallback rather than the primary destination.
According to recent industry reports, referral sessions from LLMs like ChatGPT, Perplexity, and Gemini have surged by 527% year-over-year. This indicates that conversational search has fully transitioned from an experimental feature to a primary traffic driver. Users are bypassing traditional search engines entirely to opt for direct answers from generative engines.
However, this surge in LLM usage comes with a steep penalty for legacy SEO strategies. A Conductor analysis from Q1 2026 reveals that when a voice-compatible AI Overview is present, the click-through rate for the top organic result drops to just 2.6%. This shifts all value from traditional ranking to source attribution within the AI answer, rendering the visual real estate below effectively dead.
If your brand is not explicitly cited in the generative response, you effectively do not exist in the voice-first ecosystem. The metrics dictate a hard pivot away from blue-link optimization toward machine-parsable entity dominance. Brands must engineer their content to be the foundational substrate of the LLM’s answer rather than just a link on a page.
Escaping the Citation Blackout in AI Overviews
As of June 2026, AI Overviews dominate the landscape by appearing in over half of all informational and comparison-based queries. Developers are actively utilizing advanced APIs from Perplexity and Google to simulate voice-triggered RAG responses. The ultimate goal is to provide immediate, synthesized answers without requiring the user to click or scroll.
To survive this environment, content must achieve strict citation depth. This means appearing in the top three to five sources used for an LLM’s synthesis. However, voice assistants introduce a brutal real-world friction point that visually-based SEO professionals often overlook.
Unlike visual interfaces where users can scan a list of footnotes, voice assistants typically only read the first cited source aloud. If a brand is cited but placed at the end of the citation list, it receives zero auditory attribution. Being the fourth reference in a synthesized answer is functionally equivalent to being invisible.
This renders traditional ranking metrics strategically irrelevant for voice search. Optimization must now focus on absolute primacy within the context window. Your content must be so semantically dense and factually authoritative that the LLM is forced to use it as the primary anchor for its spoken response.
Semantic Chunking for Voice Context Retention
Modern generative engine optimization strategies have abandoned arbitrary character limits in favor of semantic chunking APIs from providers like Voyage AI, Pinecone, and Weaviate. These advanced tools split content based on natural topic shifts rather than hard character counts. This ensures that discrete ideas remain perfectly intact within the vector database.
Successful architectures now employ recursive character splitting at 400 tokens with a 100-token overlap. This specific configuration ensures that conversational context is preserved seamlessly for voice retrieval. It captures the natural flow of human speech, allowing the LLM to retrieve complete thoughts rather than fragmented sentences.
Naive chunking is a massive liability in Voice-to-Action optimization. It often severs a voice prompt’s question-reasoning intent from its ultimate conclusion. When an idea is split awkwardly across two different chunks, the LLM struggles to assemble a coherent and confident answer.
When a user asks a follow-up question via voice, a poorly chunked database fails to maintain the conversational thread. This forces the AI to lose the context of your brand and cite generic competitors instead. Ultimately, this breaks the conversational chain and loses the user entirely.
Mapping Latent Fan-Out in Conversational Queries
Recent industry studies have uncovered a critical mechanic in voice search where AI engines perform fan-out query expansion for every voice prompt. Tools like Semrush Prompt Research and Surfer AI now analyze this hidden architecture. This allows marketers to map the true intent behind spoken words accurately.
In practice, every single voice query triggers multiple silent background expansions within the LLM to verify context and intent. This process silently expands a single user question into a complex context map before generating a single word of the response. The LLM is essentially interviewing itself to ensure it understands the user’s vague spoken prompt.
Brands that do not occupy the top tier of the vector cluster for these hidden queries are excluded from the final answer. This happens even if they hold the number one organic rank for the primary keyword. Optimizing for these latent clusters is the only way to ensure brand salience in multi-turn AI search.
Unfortunately, traditional keyword research tools are entirely blind to these hidden queries. SEO professionals who over-optimize for the spoken prompt while ignoring latent semantic expansions will find their content orphaned by the LLM’s final source selection algorithm. You must map the entire semantic neighborhood rather than just the front door.
Automating Sentiment Injection to Counter Perception Drift
Securing a citation is only half the battle, as the LLM must actually recommend your entity. Advanced moderation APIs and constitutional AI frameworks are now being utilized by brands to track perception drift in real-time. It is no longer enough to be mentioned; you must be positioned as the optimal solution.
Forward-thinking brands automate sentiment tracking across voice assistant outputs. This ensures they are not just passively mentioned, but actively recommended as best-in-class in zero-click voice environments. They monitor how LLMs describe their products to identify negative framing before it impacts consumer behavior.
The danger lies in an LLM’s internal bias, which is often trained on outdated forum data or historical threads. If the model associates a brand with a legacy bug or a resolved controversy, the voice assistant will subtly steer users toward competitors. This happens invisibly, without the brand ever knowing they lost a potential customer.
Currently, brands have no manual veto button for this algorithmic bias. They must deploy automated entity injection and continuous semantic reinforcement to correct the narrative. By consistently feeding the LLM updated and machine-parsable facts, brands can maintain a pristine Voice-to-Action reputation.
The Post-Query Era of Anticipatory Agentic GEO
By 2027, the industry will pivot sharply toward anticipatory agentic generative engine optimization. AI agents embedded in smart wearables will move far beyond reactive voice answers to proactive, autonomous task fulfillment. These agents will not wait for a prompt, but will instead anticipate needs based on environmental context and biometric data.
This impending post-query era will ruthlessly prioritize content that exists within agentic reach. Specifically, LLMs will favor data optimized for rapid retrieval latency that carries verifiable cryptographic proof of authorship to bypass aggressive AI hallucination filters. Trust and speed will soon be the only currencies that matter.
If your semantic architecture cannot prove its own validity at the speed of thought, autonomous agents will simply bypass your brand in favor of a faster, verified competitor. The future of search is no longer about traditional ranking. Instead, it is about being the most accessible and trusted node in a global neural network.
Navigating the intersection of generative engine optimization, AI search architecture, and workflow automation requires a sharp strategy. To future-proof your brand’s visibility in LLMs and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is the Entropy Gap in generative AI search?
The Entropy Gap is the disconnect between the high-entropy, messy nature of human speech and the rigid vector-space requirements of traditional RAG pipelines. Bridging this gap requires restructuring content so that semantic chunks match the natural prosody and context found in voice-first training sets.
How does V2A Optimization impact brand visibility?
Voice-to-Action (V2A) Optimization ensures that LLMs recognize a specific brand as the definitive, actionable answer when users provide complex, conversational prompts via voice. It moves beyond keyword matching to focus on conversational entity retrieval, preventing brands from being ignored in voice-triggered responses.
What causes a Citation Blackout in AI Overviews?
A Citation Blackout occurs when high-authority content is ignored by LLMs because it lacks the conversational structure required for modern retrieval. In voice-first environments, this is exacerbated because voice assistants typically only read the first cited source aloud, rendering lower-ranked citations effectively invisible.
Why is semantic chunking critical for voice context retention?
Unlike traditional character-based splitting, semantic chunking uses topic shifts to divide content. This preserves the complete ‘Question-Reasoning-Conclusion’ intent of a prompt within a vector database, allowing the AI to maintain conversational threads and provide more accurate multi-turn answers.
What is Fan-Out Query Expansion in voice search?
Fan-Out Query Expansion is a process where AI engines silently generate 2 to 5 background queries for every single voice prompt to verify intent and context. Brands must optimize for these latent semantic clusters, not just the primary spoken prompt, to remain salience in the final AI-generated answer.
How can brands counter Perception Drift in LLM responses?
Brands can counter Perception Drift by using automated entity injection and sentiment tracking to monitor how LLMs describe them in real-time. This helps correct algorithmic biases or outdated training data that might subtly steer users toward competitors in zero-click voice environments.