Key Points
- Transitioning from proprietary APIs to fine-tuned open-source models eliminates API Token Inflation and secures absolute data sovereignty for the enterprise.
- The market is shifting toward Deep Domain Distillation, using frontier models to generate synthetic data for hyper-efficient, task-specific Mixture-of-Experts architectures.
- Future-proof enterprise infrastructures will rely on Model Fragments and Live Weight Adaptation rather than static, monolithic general-purpose language models.
Table of Contents
The Core Friction: API Token Inflation
According to data from Index.dev, enterprise LLM adoption has surged from under 5% in 2023 to over 80% by mid-2026. This signals a definitive shift from experimental pilots to core business infrastructure. This hyper-adoption has fundamentally altered the technological landscape while exposing a massive structural flaw in how modern companies consume artificial intelligence.
We are currently witnessing the crippling reality of API Token Inflation across the digital economy. Proprietary API costs for GPT-5.2 class models have reached $21 per million tokens, leaving enterprises with an unsustainable scaling trajectory. Relying exclusively on closed ecosystems is no longer a viable long-term strategy for high-volume, mission-critical operations.
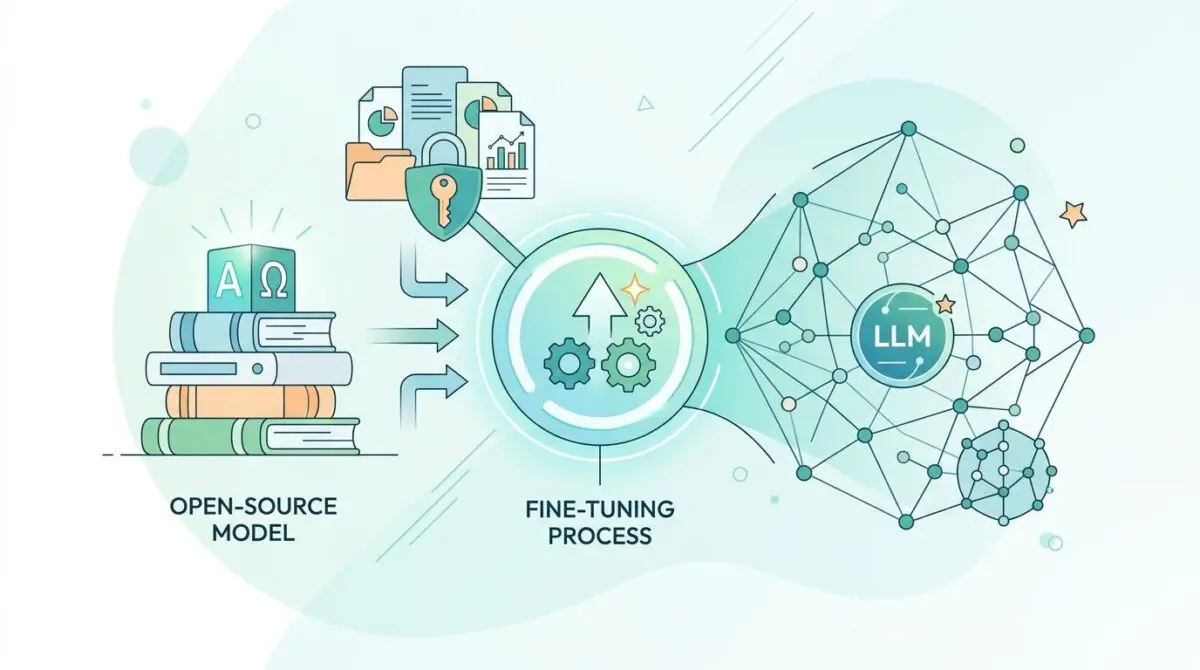
The strategic solution to this market friction lies in Enterprise Open-Source LLM Customization. By fine-tuning open-weight models on proprietary data, companies are aggressively taking back control of their intellectual property. This decentralized approach ensures that sensitive corporate data never leaves the air-gapped environment of a private cloud.
Furthermore, general-purpose models are currently failing on 61% of enterprise-specific tasks due to a severe lack of domain-specific data readiness. Fine-tuning solves this exact friction by transforming generic reasoning engines into hyper-specialized vertical experts. The era of renting generic intelligence is rapidly giving way to owning customized cognitive assets.
Market Intelligence & Smart Capital
Market Intelligence & Data
Inference Cost Savings
Enterprises transitioning from proprietary GPT-5.1 APIs to fine-tuned open-source models like DeepSeek V3.2 report up to 85% reduction in total cost of ownership according to WhatLLM.org.
AI Infrastructure Market
The global market for the hardware and software needed to train and deploy these custom models is projected to reach $75.4 billion by the end of 2026 per Fortune Business Insights.
Small Model Dominance
Gartner predicts that by 2027, specialized, task-specific small language models (SLMs) will outnumber general-purpose frontier models 3-to-1 in enterprise production environments.
Strategic Model Migration
A January 2026 survey from MakeBot.ai reveals that 41% of organizations plan to move entirely from closed to open-source architectures once specific domain performance targets are hit.
The data presented above paints a remarkably clear picture of where the smart money is moving in the tech sector. Capital is aggressively flowing away from general-purpose model labs and toward specialized infrastructure providers. Analysts confirm that the global AI infrastructure market is projected to reach $75.40 billion by 2026, driven entirely by the demand for sovereign computing.
We are seeing a massive reallocation of enterprise IT budgets across every major industry. Companies are realizing that renting intelligence by the token is a depreciating asset, whereas owning a fine-tuned model builds compounding proprietary value. This psychological shift explains why enterprise LLM adoption has surged from under 5% in 2023 to over 80% by 2026, heavily weighted toward customized deployments.
Venture capital is taking note of this massive infrastructural pivot. Investments are pouring into platforms that reduce the friction of deploying open-source models at scale. The market is rewarding companies that provide the picks and shovels for this new era of digital sovereignty.
The Strategic Deep Dive: Deep Domain Distillation
The artificial intelligence landscape has fundamentally shifted from simple Retrieval-Augmented Generation to what industry insiders call Deep Domain Distillation. Enterprises are now leveraging massive frontier models like Llama 4 Behemoth as powerful teacher models. These behemoths generate high-fidelity synthetic datasets that perfectly map to a company’s internal logic and workflows.
These highly curated synthetic datasets are then used to fine-tune hyper-efficient Mixture-of-Experts models. Models like Llama 4 Maverick or DeepSeek V3 are becoming the standard for these distilled deployments. The end result is a highly capable system with a staggering 10-million-token context window.
These distilled models possess a native, deeply ingrained understanding of internal proprietary codebases and specialized industry jargon. They consistently outperform general-purpose APIs in vertical-specific reasoning because their weights have been physically altered to understand the business. This represents a leap from surface-level data retrieval to foundational structural comprehension.
The Sovereign AI Infrastructure Shift
This architectural pivot toward customized models requires a completely new breed of hardware orchestration. Companies like Together AI have emerged as dominant market disruptors in this space. They recently hit an estimated $1 billion annualized revenue in February 2026 by providing specialized GPU clusters specifically built for enterprise fine-tuning.
The ecosystem is rapidly maturing around platforms like SiliconFlow and Featherless AI. These platforms now offer one-click fine-tuning pipelines that abstract away the brutal complexity of cluster management. Meanwhile, Hugging Face remains the central ecosystem hub, hosting over two million public models and supporting verified accounts for 30% of the Fortune 500.
The efficiency gains of these new customized architectures are nothing short of staggering. Meta’s Llama 4 Maverick achieved performance parity with GPT-4o across multimodal benchmarks while utilizing only 17 billion active parameters per forward pass. This allows enterprises to run frontier-grade intelligence on a single NVIDIA H100 GPU according to Meta AI’s 2026 performance documentation.
This means the financial and technical barrier to entry for enterprise-grade sovereign AI has effectively collapsed. You no longer need a massive supercomputer to run world-class intelligence within your own firewalls. Smart money is capitalizing on this hardware efficiency to deploy AI into environments previously considered too constrained.
The Death of the Monolithic Model
The psychological shift occurring within the modern C-suite is equally profound. Executives are rapidly moving away from the dangerous allure of a single, monolithic artificial intelligence that handles every business function. That centralized approach creates single points of failure and massive latency bottlenecks.
Instead, forward-thinking leaders are preparing for Model Fragment architectures. In this decentralized paradigm, companies maintain thousands of tiny, task-specific LoRA adapters rather than one massive neural network. These adapters act as modular brain structures that can be swapped out on demand.
These micro-adapters are swapped in milliseconds to handle highly specific, localized business functions. This ranges from real-time legal compliance verification to automated agentic codebase refactoring. By fragmenting the intelligence, companies achieve unprecedented speed, security, and specialized accuracy.
The Executive Action Plan: Live Weight Adaptation
The next major evolution of this technology is Live Weight Adaptation. Models will no longer remain static after their initial fine-tuning phase is complete. Instead, they will continuously update their weights in real-time through online learning loops driven directly by user feedback.
Strategic Trajectory
- Implement Live Weight Adaptation to transition from static models to real-time weight updates.
- Establish continuous online learning loops driven by direct user feedback.
- Architect for Model Fragment environments rather than monolithic LLM deployments.
- Orchestrate thousands of task-specific LoRA adapters for hyper-specialized business functions.
- Optimize infrastructure for millisecond-latency adapter swapping.
- Scale specialized AI capabilities for real-time legal compliance and automated agentic refactoring.
Implementing this aggressive trajectory requires a fundamental rethinking of your engineering culture. Leaders must prioritize infrastructure that supports millisecond-latency adapter swapping over brute-force compute power. Agility and specialization are the new metrics for AI success.
The winners in this next economic cycle will be those who can hyper-specialize their AI capabilities faster than their competitors. You must build a feedback loop where every customer interaction makes your proprietary model incrementally smarter. This creates a data flywheel that becomes mathematically impossible for competitors to replicate.
Conclusion: Architecting for the Future
The era of renting generic intelligence from centralized tech monopolies is drawing to a close. The future of enterprise technology belongs to organizations that treat their proprietary data as their ultimate competitive moat. By mastering the art of open-source fine-tuning, you transition your AI strategy from a recurring cost center into a compounding corporate asset.
Embracing Model Fragments and Live Weight Adaptation is no longer optional for market leaders. It is the baseline requirement for surviving the next wave of digital disruption. Your infrastructure must be as dynamic and specialized as the markets you serve.
Navigating the intersection of technology, capital, and market psychology requires a sharp strategy. To future-proof your business architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is API Token Inflation and how does it impact enterprise AI scaling?
API Token Inflation refers to the unsustainable cost trajectory associated with proprietary LLM APIs, which can reach $21 per million tokens. This creates a structural flaw for enterprises, forcing a shift toward open-source customization to reduce the total cost of ownership by up to 85%.
Why are organizations moving from proprietary models to open-source LLM customization?
Enterprises are migrating to open-source architectures to regain control of intellectual property, ensure data stays within air-gapped private clouds, and improve performance. General-purpose models often fail on 61% of enterprise tasks, a gap that fine-tuning open-source models effectively closes.
How does Deep Domain Distillation improve AI performance on specialized tasks?
Deep Domain Distillation leverages large teacher models to generate synthetic datasets that map to internal business logic. These datasets are used to fine-tune smaller Mixture-of-Experts models, physically altering their weights to understand proprietary codebases and industry jargon more deeply than generic APIs.
What is the significance of the shift toward Sovereign AI infrastructure?
Sovereign AI infrastructure enables organizations to run frontier-grade intelligence within their own firewalls. With hardware efficiency gains, models like Llama 4 Maverick can achieve parity with models like GPT-4o while running on a single GPU, collapsing the financial and technical barriers to private AI deployment.
How do Model Fragment architectures differ from monolithic LLM deployments?
Unlike monolithic models that create latency bottlenecks, Model Fragment architectures utilize thousands of task-specific LoRA adapters. These modular adapters are swapped in milliseconds to handle specific functions, such as legal compliance or codebase refactoring, offering superior speed and specialization.
What is Live Weight Adaptation in the context of enterprise AI strategy?
Live Weight Adaptation is an advanced stage of AI deployment where models continuously update their weights in real-time through online learning loops. Driven by direct user feedback, this process transforms the AI into a compounding corporate asset that evolves alongside the business.