Key Points
- Intent-Aware Orchestration: Dynamic systems using SLMs to balance BM25 and dense vector search are the new enterprise standard.
- Agentic Re-ranking: Leveraging secondary SLMs to judge retrieval results boosts relevance by 40% while slashing compute costs.
- Self-Optimizing Retrieval: By 2027, RLHF at the retrieval layer will automate cross-departmental search accuracy without manual tuning.
Table of Contents
Diagnosing the Core Friction
According to a recent Forrester AI Infrastructure Report, hybrid search architectures have reduced retrieval-induced hallucinations in enterprise RAG systems by 62% compared to pure vector-only implementations. This staggering metric highlights a critical pivot in how organizations deploy artificial intelligence at scale. We have officially moved past the era of generic generative models and entered the age of hyper-precise data orchestration.
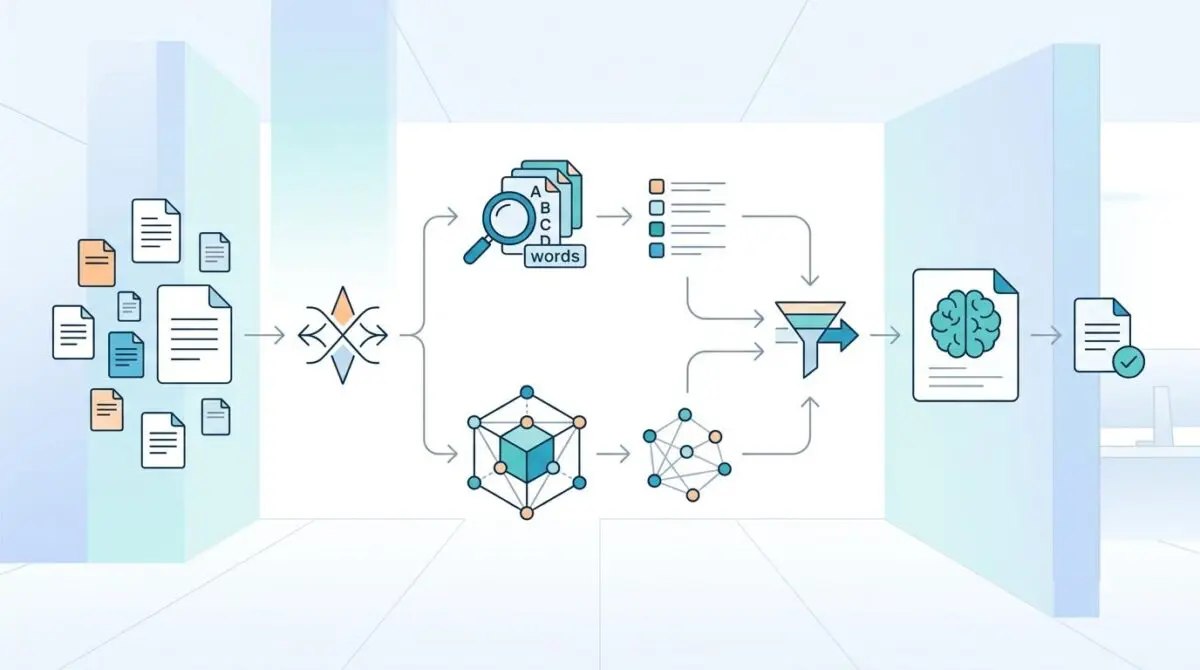
The primary friction point in modern AI deployments is the Precision-Recall Paradox. Vector search excels at understanding broad concepts and semantic meaning, but it fails spectacularly when tasked with finding specific identifiers like part numbers, legal codes, or exact names. Conversely, traditional keyword search is far too rigid to grasp the nuanced intent behind a complex user query.
This disconnect leads to retrieval-induced hallucinations, a multi-million dollar liability where an LLM receives irrelevant context and delivers a confidently wrong answer. Hybrid Search in Enterprise Retrieval-Augmented Generation (RAG) resolves this by merging lexical and semantic retrieval. By eliminating the blind spots of both systems, hybrid architectures are unlocking AI for highly regulated, high-stakes environments like medical diagnostics and financial auditing.
Market Intelligence & Smart Capital Flow
Market Intelligence & Data
Market Valuation
According to IDC, the global Enterprise AI Search and Retrieval market reached $12.4 billion in early 2026, driven by the mass migration to hybrid-RAG architectures.
Enterprise Adoption
A 2026 survey by Andreessen Horowitz (a16z) found that 88% of Fortune 500 AI leaders now utilize hybrid search over pure vector databases to manage domain-specific technical jargon.
ROI Acceleration
Data from Deloitte’s 2026 State of Generative AI report shows that companies implementing hybrid search see a 3.5x faster path to production ROI due to decreased debugging of retrieval failures.
Latency Standard
Benchmarks from the 2026 Open Source Search Initiative show that modern RRF-based hybrid systems now achieve sub-200ms latency even across multi-billion document corpuses.
The influx of institutional capital is aggressively shifting away from pure-play LLM providers and flowing directly into retrieval infrastructure. Venture capitalists and enterprise leaders alike recognize that the intelligence of an AI application is entirely bounded by the quality of its data retrieval. Without precise context, even the most advanced reasoning models are functionally useless in a corporate setting.
Major disruptors like Pinecone have dominated the space with their Graph-Hybrid engines, while Weaviate has successfully pivoted to a multimodal-first hybrid strategy. Simultaneously, data lakehouse giants such as Databricks and Snowflake are embedding native, highly optimized hybrid search capabilities directly into the data layer. This consolidation signals a profound market maturation where search is no longer an afterthought.
As founders evaluate these emerging architectures for LLM applications, the focus has shifted toward building resilient, hallucination-free systems. Smart money is betting on infrastructure that can seamlessly orchestrate structured and unstructured data at scale. The enterprise mandate is clear: precision at the retrieval layer is the ultimate competitive moat.
Architecting the Corporate Brain
The killer strategy for enterprise AI now relies on Intent-Aware Hybrid Retrieval. This involves a dynamic orchestration layer that uses Small Language Models to analyze a query and adjust the weights between BM25 lexical search and dense vector search in real-time. It represents a fundamental shift from static algorithms to fluid, context-aware data retrieval.
Organizations are increasingly deploying Late Interaction models, such as ColBERTv3, within their RAG pipelines. These advanced models maintain high precision for technical documentation while successfully capturing deep semantic nuance. The result is the creation of Corporate Brains—internal systems that allow employees to query millions of pages of unstructured data with absolute confidence.
Agentic Retrieval Mechanics
The mechanics behind these systems are becoming increasingly autonomous and highly efficient. A recent study by NVIDIA Research revealed that Agentic Re-ranking—using a secondary SLM to judge hybrid search results—increases final output relevance by 40% while consuming 70% less compute than traditional cross-encoders. This breakthrough effectively democratizes high-tier retrieval accuracy for mid-market enterprises.
Venture capital is now heavily focused on Agentic Retrieval startups that build systems where autonomous agents proactively tune search parameters based on historical accuracy metrics. For engineering teams looking to integrate these capabilities, studying robust LLM app stack implementations is essential for mapping out scalable, production-ready pipelines.
The Executive Action Plan
Strategic Trajectory
- Transition toward ‘Self-Optimizing Retrieval’ (SOR) to eliminate manual weighting of search algorithms.
- Implement Reinforcement Learning from Human Feedback (RLHF) at the retrieval layer to automate cross-departmental accuracy.
- Architect for ‘Cross-Enterprise RAG’ to enable secure, federated retrieval across partner ecosystems.
- Deploy advanced hybrid search protocols to facilitate multi-entity data accessibility.
- Ensure zero-trust data privacy during federated retrieval within corporate partner entities.
The next evolution in this space is Self-Optimizing Retrieval, an architecture that promises to make manual weighting of search algorithms entirely obsolete. Systems will leverage Reinforcement Learning from Human Feedback directly at the retrieval level. This allows the infrastructure to automatically learn which data sources and search methods yield the most accurate answers for specific departmental needs.
Forward-thinking founders are already preparing for Cross-Enterprise RAG. This paradigm shift utilizes advanced hybrid search protocols to allow for secure, federated retrieval across different company entities and partner ecosystems. It ensures that businesses can share critical intelligence without ever compromising strict zero-trust data privacy standards.
Executing this roadmap requires a deliberate transition away from legacy vector databases toward dynamic, agent-driven architectures. Executives must prioritize retrieval accuracy as a core business KPI, rather than treating it as a secondary engineering metric. The organizations that master this orchestration will command the next decade of enterprise efficiency.
Conclusion: Future-Proofing the AI Stack
The transition to hybrid search within enterprise RAG applications is not merely a technical upgrade; it is a strategic imperative. By resolving the Precision-Recall Paradox, businesses can finally deploy generative AI into mission-critical workflows with zero hesitation. The era of confidently wrong AI is ending, replaced by systems that are as precise as they are intelligent.
Navigating the intersection of technology, capital, and market psychology requires a sharp strategy. To future-proof your business architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is hybrid search in Enterprise RAG?
Hybrid search in Enterprise Retrieval-Augmented Generation (RAG) is a retrieval architecture that combines lexical (keyword-based) search with semantic (vector-based) search. This approach resolves the Precision-Recall Paradox by leveraging BM25 algorithms for exact identifiers and vector engines for conceptual understanding, leading to higher accuracy in corporate environments.
How does hybrid search reduce AI hallucinations?
According to 2026 industry data, hybrid search architectures reduce retrieval-induced hallucinations by 62% compared to vector-only systems. By providing the Large Language Model (LLM) with more precise and relevant context—specifically for technical jargon, part numbers, and legal codes—the model is less likely to generate incorrect or fabricated responses.
What is the business ROI of implementing hybrid RAG systems?
Enterprises implementing hybrid search see a 3.5x faster path to production ROI. This acceleration is primarily driven by a significant decrease in the time required to debug retrieval failures and the ability to achieve sub-200ms latency even across multi-billion document corpuses, enhancing overall operational efficiency.
What are the benefits of Agentic Re-ranking in AI retrieval?
Agentic Re-ranking uses secondary Small Language Models (SLMs) to autonomously judge the relevance of search results. This technique increases final output relevance by 40% and consumes 70% less compute than traditional cross-encoders, making high-tier retrieval accuracy accessible for mid-market enterprises.
What is Self-Optimizing Retrieval (SOR)?
Self-Optimizing Retrieval is an advanced architecture that uses Reinforcement Learning from Human Feedback (RLHF) at the retrieval layer. It allows AI systems to automatically learn which search methods and data sources yield the most accurate answers for specific departments, eventually making manual algorithm weighting obsolete.
How does Cross-Enterprise RAG maintain data privacy?
Cross-Enterprise RAG utilizes advanced hybrid search protocols to enable federated retrieval across different corporate entities. This paradigm shift ensures that businesses can share critical intelligence and navigate partner ecosystems while adhering to strict zero-trust data privacy standards.