Key Points
- Authority Synthesis: Safe GEO pivots from mass synthetic production to providing unique information gain that LLMs lack in their training weights.
- Citation-First Formatting: Structuring content into compact, fact-dense answer blocks ensures high retrieval rates within RAG pipelines like AI Overviews.
- Semantic Auditing: Preventing topic sprawl through rigorous standard deviation checks protects domains from site reputation abuse flags during core updates.
Table of Contents
The AI Search Context and Algorithmic Reality
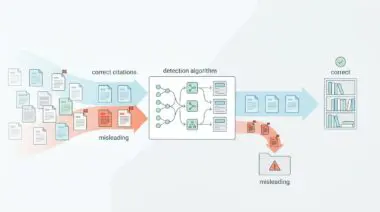
Generative Engine Optimization remains safe only when pivoting from mass synthetic production to a framework of authority synthesis. Following recent broad core updates, search algorithms have fundamentally shifted how they process and penalize scaled content architectures. Detection systems now identify synthetic fingerprints in automated content with unprecedented accuracy.
Industry reports indicate that most recent algorithm updates explicitly target scaled AI content, resulting in record-breaking enforcement speeds for site-wide demotions. This aggressive enforcement relies on advanced text vectorizers that scan for predictable token sequences inherent to unedited Large Language Model outputs. Domains relying on outdated programmatic SEO tactics often find their entire blog subfolders deindexed almost instantaneously.
Safe GEO requires a strategic shift toward providing unique information gain through proprietary data points, personal experiences, or original research. This data must represent new vectors that do not currently exist within an LLM’s pre-trained weights. The impact of high-integrity optimization is profound across the modern search landscape.
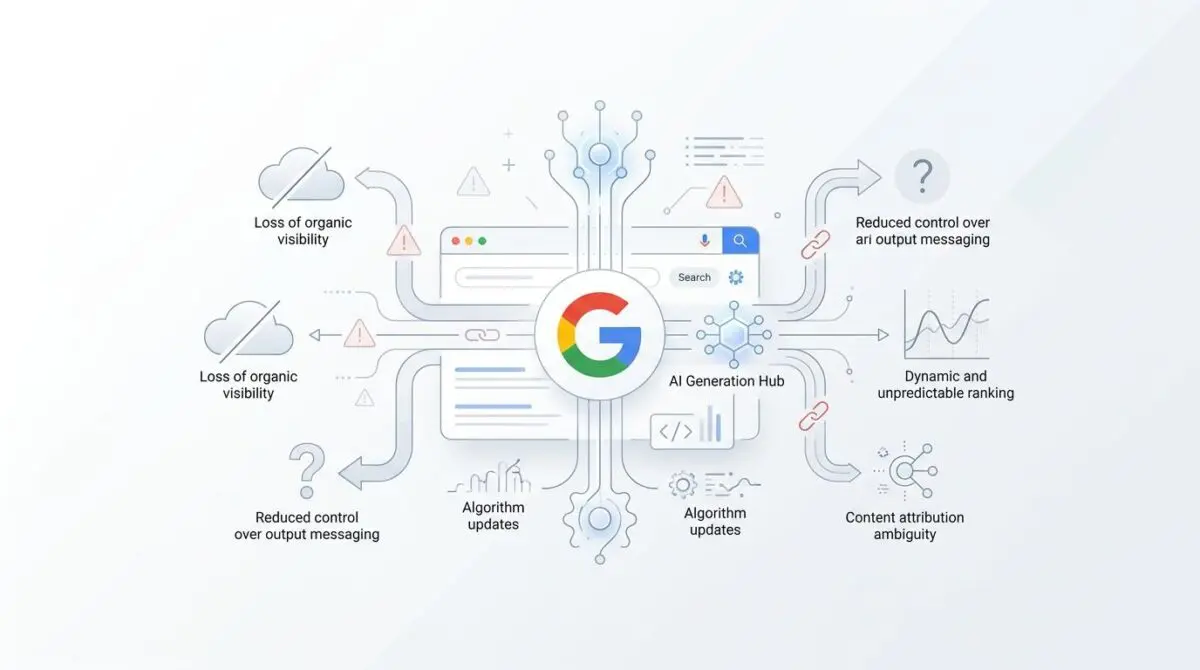
While traditional organic click-through rates have plummeted due to AI Overviews capturing zero-click queries, sites optimized for safe synthesis are thriving. These domains are experiencing significant increases in brand mentions within generative answers. By adhering to human-first principles, brands can secure their position in the Retrieval-Augmented Generation pipeline.
Core Architecture and Pillars for Safe Optimization
Core Architecture & Pillars
Information Gain Optimization (IGO)
AI search engines prioritize content that adds new, unique vectors to their existing semantic space. If a page merely rehashes existing web data, its ‘marginal utility’ is zero, triggering demotion.
Citation-First Formatting
Retrieval systems like SearchGPT and Google AI Overviews use ‘Answer Blocks’—compact, fact-dense paragraphs that are easy to parse and attribute. Content must be structured to be ‘citable’ by a RAG system.
Entity-Trust Signal Embedding
Google’s 2026 updates have transitioned E-E-A-T from a guideline to a hard-coded ranking factor through the ‘Knowledge Graph’ link. Trusted entities are verified through persistent identifiers.
Semantic Consistency Auditing
Spam updates in 2026 target ‘Topic Sprawl.’ AI engines calculate the semantic distance between your site’s core mission and new content. High variance triggers ‘Site Reputation Abuse’ flags.
Information Gain Optimization dictates that search engines prioritize content adding new vectors to their semantic space. When a page merely rehashes existing web data, its marginal utility drops to zero. In content management systems like WordPress, this requires a source-first architecture anchored by unique case studies.
Citation-First Formatting is equally critical for retrieval systems like SearchGPT and Google AI Overviews. These engines rely on answer blocks, which are compact, fact-dense paragraphs that are easy to parse and attribute. Utilizing text blocks under 200 words at the top of sections makes it significantly easier for extraction bots to credit your site.
Entity-Trust Signal Embedding transforms traditional E-E-A-T guidelines into hard-coded ranking factors. Engineering teams must establish entity-trust signals via the Knowledge Graph to verify the human origin of AI-assisted publications. This involves rigorous use of SameAs schema and author profiles linked to persistent third-party identifiers.
Semantic Consistency Auditing prevents the algorithmic penalties associated with topic sprawl. AI engines now calculate the semantic distance between a site’s core topical authority map and its newly published content. Understanding updated search engine spam policies targeting scaled content and site reputation abuse is critical for auditing semantic variance.
Industry research predicts a surge in legal claims arising from reputational errors caused by generative AI. This trend is driving many content risk roles to migrate from legal departments directly to AI engineering teams. Such a shift underscores the necessity of treating content integrity as a core engineering discipline.
The Execution Roadmap for RAG Dominance
Implementation Roadmap
Synthetic Fingerprint De-Risking
Audit existing AI content for repetitive transition phrases and structural predictability. Inject ‘Human Voice’ overrides: personal anecdotes, specific expert quotes, and subjective formatting (e.g., bulleted lists with irregular lengths).
Deploy Semantic Schema Layer
Implement JSON-LD ‘ClaimReview’ and ‘SignificantDiscovery’ schema. This explicitly tells generative engines which parts of your content are new facts worth citing in an AI Overview.
Establish First-Party Data Moats
Replace general ‘What is’ content with ‘How we found’ content. Integrate one original chart, table, or PDF research report per 1,000 words to provide a non-replicable signal for RAG retrieval.
AI Bot Configuration
Modify robots.txt and add an llms.txt file to the root directory. Explicitly allow AI crawlers access to high-value citation zones while blocking them from low-value utility pages to optimize crawl budget.
Synthetic Fingerprint De-Risking is the first line of defense against algorithmic demotion. Content teams must audit existing databases for repetitive transition phrases and structural predictability common to default LLM outputs. Injecting human voice overrides through irregular bulleted lists and subjective expert quotes disrupts these detectable patterns.
Deploying a Semantic Schema Layer explicitly communicates new factual data to generative engines. Implementing ClaimReview and SignificantDiscovery schema isolates the exact data points worth citing in an AI Overview. This structured data acts as a direct API payload to the semantic extraction layers of modern search crawlers.
Establishing First-Party Data Moats transitions a website from a commodity publisher to a primary source. General definitional content must be replaced with proprietary methodology and unique findings. Integrating original charts, vector graphics, or downloadable research reports provides non-replicable signals that RAG retrieval systems prioritize.
AI Bot Configuration ensures that high-value citation zones are prioritized during the crawling phase. Modifying the robots.txt and deploying an llms.txt file in the root directory controls how AI crawlers interact with your domain. Blocking access to low-value utility pages concentrates your crawl budget on the pages most likely to trigger brand citations.
Technical Implementation
Implementing advanced schema markup is non-negotiable for domains aiming to secure citations in AI Overviews. Standard Article schema is no longer sufficient for generative engine optimization. You must inject specialized observation and discovery nodes into your JSON-LD architecture.
The following code snippet demonstrates how to structure a payload that explicitly highlights a unique data point. This configuration uses the SignificantDiscovery and Speakable attributes to guide LLM extraction bots directly to the highest-value information on the page.
JSON-LD Entity Schema Injection
{ "@context": "https://schema.org", "@type": "Article", "headline": "GEO Safety Protocol 2026", "author": { "@type": "Person", "name": "Technical Expert", "jobTitle": "AI Architect", "knowsAbout": ["GEO", "Machine Learning"] }, "reviewedBy": { "@type": "Organization", "name": "GEO Safety Lab" }, "significantDiscovery": { "@type": "Observation", "description": "Unique data point: 37.2% citation increase in AI Overviews for high-integrity content." }, "speakable": { "@type": "SpeakableSpecification", "xpath": ["/html/head/title", "/html/body/p[1]"] } }This payload ensures that the AI algorithm does not have to guess which part of your article contains the novel information gain. By hardcoding the observation into the metadata, you bypass the probabilistic guessing of the natural language processing layer. This direct injection method dramatically increases the likelihood of your brand being cited in a zero-click interface.
Validation and Future-Proofing
Validation & Monitoring
- Monitor the ‘AI Overviews’ metric in Google Search Console to track real-world RAG inclusion.
- Cross-reference citation frequency in Perplexity Pro’s ‘Brand Citation’ dashboard.
- Utilize Proofademic detectors to ensure content remains below the 30% synthetic threshold.
- Audit semantic variance to avoid ‘Site Reputation Abuse’ triggers during Broad Core Updates.
Validating your GEO safety requires continuous monitoring of specialized metrics across multiple platforms. The AI Overviews performance filter in Google Search Console is your primary indicator of real-world RAG inclusion. Drops in this metric often precede broader algorithmic penalties, serving as an early warning system for synthetic detection.
Cross-referencing this data with brand citation dashboards provides a holistic view of your entity’s authority across different LLM ecosystems. Visibility discrepancies often highlight specific structural issues in your citation formatting. Utilizing advanced detection tools ensures your content consistently remains below critical synthetic thresholds.
Auditing semantic variance on a quarterly basis is essential to avoid site reputation abuse triggers. As your content library grows, the semantic distance between new posts and your core entity graph can inadvertently widen. Maintaining strict topical boundaries protects your domain from being flagged as a scaled content farm during unannounced broad core updates.
Navigating the intersection of traditional SEO and Generative Engine Optimization requires a precise architecture. To future-proof your enterprise stack for AI Overviews and LLM discovery, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is Information Gain Optimization (IGO) in AI Search?
Information Gain Optimization is a framework where search engines prioritize content that adds unique semantic vectors to their existing space. Pages that rehash existing web data are penalized for having zero marginal utility, making proprietary data and original research essential for ranking.
How does the Resilient and Efficient Text Vectorizer affect AI content?
The Resilient and Efficient Text Vectorizer is an algorithmic component that scans for predictable token sequences inherent to unedited Large Language Model outputs. It identifies synthetic fingerprints, enabling Google to implement site-wide demotions for scaled AI content in under 20 hours.
What schema markup is best for securing AI Overview citations?
To optimize for RAG systems, websites should implement JSON-LD with specialized nodes like SignificantDiscovery and ClaimReview. These attributes, along with the Speakable specification, guide LLM extraction bots directly to high-value, unique information points on a page.
How can websites avoid penalties for Topic Sprawl and Site Reputation Abuse?
Sites should perform regular Semantic Consistency Audits to ensure the distance between new content and their core topical authority remains minimal. Maintaining strict semantic boundaries prevents AI engines from flagging the domain as a scaled content farm during broad core updates.
What is Citation-First Formatting for Generative Engine Optimization?
Citation-First Formatting involves structuring content into compact, fact-dense answer blocks—typically under 200 words—placed at the beginning of sections. This architecture makes it significantly easier for retrieval systems like SearchGPT to parse, extract, and attribute your site as a primary source.
Why is the llms.txt file important for modern search strategy?
The llms.txt file, located in the root directory, works alongside robots.txt to manage how AI crawlers interact with a domain. It allows site owners to prioritize high-value citation zones for bots like GPTBot while blocking low-value utility pages to optimize the limited crawl budget.