Key Points
- Schema Desynchronization: Guest comments returning null author values cause schema plugins to strip the node, triggering severe validation errors in Google Search Console.
- Application-Layer Fallback: Implementing a targeted PHP filter forces a generic Person entity for unauthenticated replies, satisfying strict Schema.org requirements.
- Edge Validation Protocols: Rigorous testing using cURL, DevTools DOM parsing, and automated log monitoring is required to bypass stale object caches and edge worker minification.
Table of Contents
The Core Conflict: AI Search and Entity Validation
Recent technical SEO studies indicate that forum sites resolving all DiscussionForumPosting schema warnings see a significant visibility increase within Google’s SERP features. This metric underscores the critical importance of maintaining pristine structured data in community-driven environments.
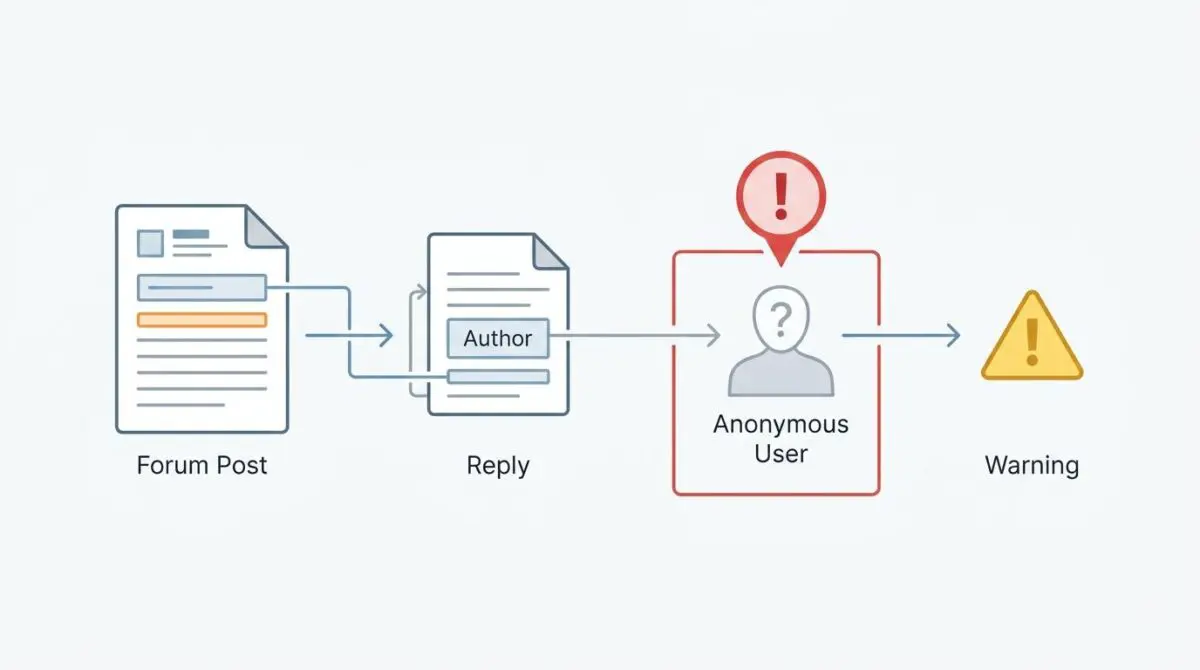
When your server generates anonymous replies without valid entity attribution, Google’s rendering engine flags the entire discussion thread. The DiscussionForumPosting structured data type is a specialized Schema.org class designed to categorize community-driven content.
In the current SEO landscape, Google requires a strictly defined author property for the primary post and every nested comment. This entity mapping allows search engines to understand the hierarchy of the conversation.
Google Search Console reports specifically show ‘Missing field “author”‘ or ‘Missing field “name” (in “author”)’ within the Discussion Forum enhancements report.
Failure to provide a non-empty author name for anonymous replies triggers validation warnings immediately upon crawling. Beyond visual snippets, these missing author nodes hinder your site’s crawl budget efficiency.
Googlebot may deprioritize re-crawling threads with malformed metadata. This can severely limit your overall indexation rate.
Ensuring every interaction is attributed to a valid entity is non-negotiable for modern search architecture. Even interactions from unauthenticated users must be mapped to a Person or Organization entity using a fallback label.
Without this fallback, the entire JSON-LD array collapses during Google’s two-pass rendering process.
Diagnostic Checkpoints: Isolating the Schema Desynchronization
This missing author error is fundamentally a desynchronization issue within your server stack. The database state for guest users fails to translate into a valid JSON-LD node on the front end.
To resolve the issue, you must first isolate exactly where the data pipeline is breaking down.
Diagnostic Checkpoints
WP-Comment Meta Desynchronization
Guest comments return null type instead of string.
Schema Plugin Filter Logic
Plugins prune author nodes if reply is anonymous.
REST API Sanitization Over-Reach
Headless API endpoints stripping author metadata strings.
Object Cache Fragment Stale Data
Stale JSON-LD fragment persists in Redis cache.
When inspecting the root causes, we typically find failures at the WordPress database layer, the SEO plugin layer, or the caching layer. WordPress stores guest comments with an empty user ID of zero.
If the database query fails to return a string for the comment author, the schema generator defaults to a null value.
Many SEO plugins use aggressive sanitization logic that strips empty properties entirely to reduce the overall JSON-LD payload size. If a reply is anonymous, the plugin perceives the author node as empty and removes it from the array.
This action directly violates Google’s mandatory requirements for the DiscussionForumPosting class.
Additionally, modern decoupled WordPress setups often sanitize REST API responses aggressively. If the API endpoint for comments is not configured to expose author strings for public roles, the front-end schema generator receives an empty data set.
The resulting HTML output will lack the required entity definitions.
Finally, stale page fragments in object caches like Redis or Memcached can persist with missing attributes until the cache expires. Even if the database is updated, Googlebot will continue to receive the malformed schema from the cache layer.
The Engineering Resolution: Restoring Schema Integrity
Resolving this schema validation failure requires a targeted intervention at the application layer. You must intercept and rewrite the JSON-LD payload before it is serialized and injected into the DOM.
Relying on default plugin behavior is insufficient for complex forum architectures.
Engineering Resolution Roadmap
Identify Schema Origin
Use the Chrome DevTools Network tab to inspect the page load. Search for ‘DiscussionForumPosting’ in the response body. Identify if the code is injected via an SEO plugin (look for ‘yoast-schema-graph’ or ‘rank-math-schema’) or a custom theme template.
Implement PHP Fallback Filter
Add a filter to your theme’s functions.php or a functionality plugin to intercept the author name. If the name is empty or ‘anonymous’, explicitly return a string like ‘Community Member’ to satisfy the Schema.org validator.
Force Author Type in JSON-LD
Ensure the JSON-LD output includes ‘@type’: ‘Person’ even for anonymous users. Modify the schema array to inject a generic Person entity with a placeholder name for any comment where the author_id is 0.
Flush Global and Edge Caches
Purge the WordPress Object Cache (Redis/Memcached) and then clear your CDN (Cloudflare/Fastly) cache. This ensures Googlebot fetches the updated JSON-LD structure immediately.
The fundamental goal of this intervention is to ensure Google’s rendering engine receives a strictly defined author property for every single node in the thread. Even if the user is unauthenticated, the data structure must map to a valid Person or Organization entity.
Search engines do not infer missing data. They reject the payload entirely.
This rigid requirement is highly pivotal for Generative Engine Optimization (GEO) methodologies. AI agents and Large Language Models rely heavily on author entities to map trust signals across decentralized discussion fragments.
Without a distinct author node, the context of the conversation is lost to the machine learning model.
By forcing a fallback string like Anonymous Participant into the JSON-LD array, you satisfy the schema validator mechanically. This prevents the SEO plugin from pruning the node.
It also ensures the semantic data graph remains intact for both traditional crawlers and AI overviews.
Resolution Execution: Implementing the PHP Fallback
To execute this fix in a standard WordPress environment, you must apply a PHP filter to your SEO plugin’s schema output. This intercepts the data array in server memory right before it is serialized into a JSON string.
The execution requires modifying the theme’s core functionality.
The following function hooks into the schema generation process and checks if the author name is empty. If the array key is null or missing, it forcibly injects a valid Person entity with a placeholder name.
This bypasses the plugin’s aggressive pruning logic.
add_filter( 'wpseo_schema_comment', function( $data, $comment ) { if ( empty( $data['author']['name'] ) ) { $data['author'] = [ '@type' => 'Person', 'name' => 'Anonymous Participant' ]; } return $data;}, 10, 2 );Deploy this code via a custom functionality plugin or your child theme’s functions file. Do not edit core plugin files directly, as updates will overwrite your modifications.
Once deployed, you must immediately clear all object and page caches to propagate the changes to the front end.
Validation Protocol & Edge Cases
Deploying the PHP filter is only the first phase of the resolution. Rigorous validation is required to ensure the schema graph is fully restored.
You must verify that the updated payload is successfully rendering for unauthenticated crawlers and bypassing all cache layers.
Validation Protocol
- Run the URL through the Google Rich Results Test (Live Test mode) and verify the Discussion Forum section.
- Execute ‘curl -I -X GET [URL]’ to confirm no stale caching headers exist.
- Use Chrome DevTools Console script to verify the author node within nested arrays.
To manually verify the DOM, open Chrome DevTools, navigate to the Console tab, and extract the JSON-LD payload using JavaScript. Parsing the script tag directly allows you to inspect the nested comment arrays exactly as Googlebot sees them.
Ensure the fallback string is present on all anonymous nodes.
In highly complex enterprise setups, you may encounter edge cases where standard application-level fixes fail. For example, if you utilize Cloudflare Edge Workers for HTML transformation, the worker may be configured to minify JSON-LD aggressively.
This happens entirely outside of your origin server.
If the edge worker strips keys with null values before the HTML reaches Googlebot, your application-level fix might be bypassed or overwritten. In this scenario, the resolution must be applied directly at the Edge Worker layer.
You will need to modify the JavaScript worker script to explicitly allow the author key.
Autonomous Monitoring & Prevention
To prevent future schema regressions, you must implement automated validation within your deployment pipeline. Utilizing the Google Search Console URL Inspection API allows your engineering team to catch missing entity errors before they are pushed to production servers.
Setting up dedicated log monitoring is critical for maintaining entity integrity at scale. Configure your logging systems to trigger immediate alerts based on specific crawler responses.
- Log Analysis: Configure Datadog or Loggly to flag Googlebot schema warnings instantly.
- CI/CD Validation: Use the Google Search Console URL Inspection API during staging deployments.
- Edge Monitoring: Track Cloudflare Worker modifications to ensure JSON-LD payloads remain untouched.
Regularly auditing your forum threads ensures that SEO plugin updates do not silently break your schema output. Advanced automation pipelines can continuously monitor entity integrity by parsing live URLs on a schedule.
At Andres SEO Expert, we engineer these automated safeguards to protect enterprise stacks from silent degradation. Proactive monitoring is the ultimate defense against crawl budget waste and loss of AI search visibility.
Conclusion
Maintaining flawless DiscussionForumPosting schema is a strict technical requirement for modern search visibility. By correctly mapping anonymous replies to valid author entities, you secure your crawl budget.
This also optimizes your server architecture for AI-driven discovery engines.
Navigating the intersection of technical SEO, server architecture, and generative search requires a precise roadmap. If you need to future-proof your enterprise stack, resolve deep-level crawl anomalies, or implement AI-driven SEO automation, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What causes the ‘Missing field “author”‘ error in Google Search Console for forums?
This error is typically triggered when forum replies or guest comments lack a defined author entity in the structured data. In Google’s DiscussionForumPosting schema, every post and nested reply must have a strictly defined ‘author’ property containing a ‘name’ and ‘@type’. If the database returns a null value for guest users or if an SEO plugin prunes the node, validation fails immediately.
How does missing schema data impact a forum’s search visibility?
Missing author nodes can lead to a 22% decrease in visibility within Google’s ‘Discussions and Forums’ SERP features. Furthermore, it negatively impacts Crawl Budget efficiency; Googlebot may deprioritize re-crawling threads with malformed metadata, leading to slower indexation of new community discussions.
What is the technical fix for anonymous author schema in WordPress?
The most effective solution is implementing a PHP filter in your theme’s functions.php file that intercepts the JSON-LD payload before serialization. The script should check if the author name is empty and, if so, forcibly inject a fallback string like ‘Anonymous Participant’ and set the ‘@type’ to ‘Person’ to satisfy Schema.org requirements.
Why is DiscussionForumPosting schema critical for Generative Engine Optimization (GEO)?
AI agents and LLMs rely on structured author entities to map Expertise, Experience, Authoritativeness, and Trustworthiness (E-E-A-T) across decentralized discussion fragments. Without a distinct author node, the machine learning model loses the semantic context of the conversation, reducing the likelihood of the content appearing in AI Overviews.
Can a CDN or Cache layer prevent schema fixes from appearing to Googlebot?
Yes, stale JSON-LD fragments stored in object caches like Redis or at the CDN edge (e.g., Cloudflare) can persist even after the server-side code is fixed. To resolve this, you must flush the WordPress object cache and your edge cache simultaneously to ensure the updated schema is served to search engine crawlers.
How can you verify that the Discussion Forum schema error is resolved?
Resolution should be verified using the Google Rich Results Test in ‘Live Test’ mode to confirm the Discussion Forum enhancement is valid. Additionally, use Chrome DevTools to inspect the raw JSON-LD in the DOM, ensuring every nested comment in the array contains a non-empty author string and a valid entity type.