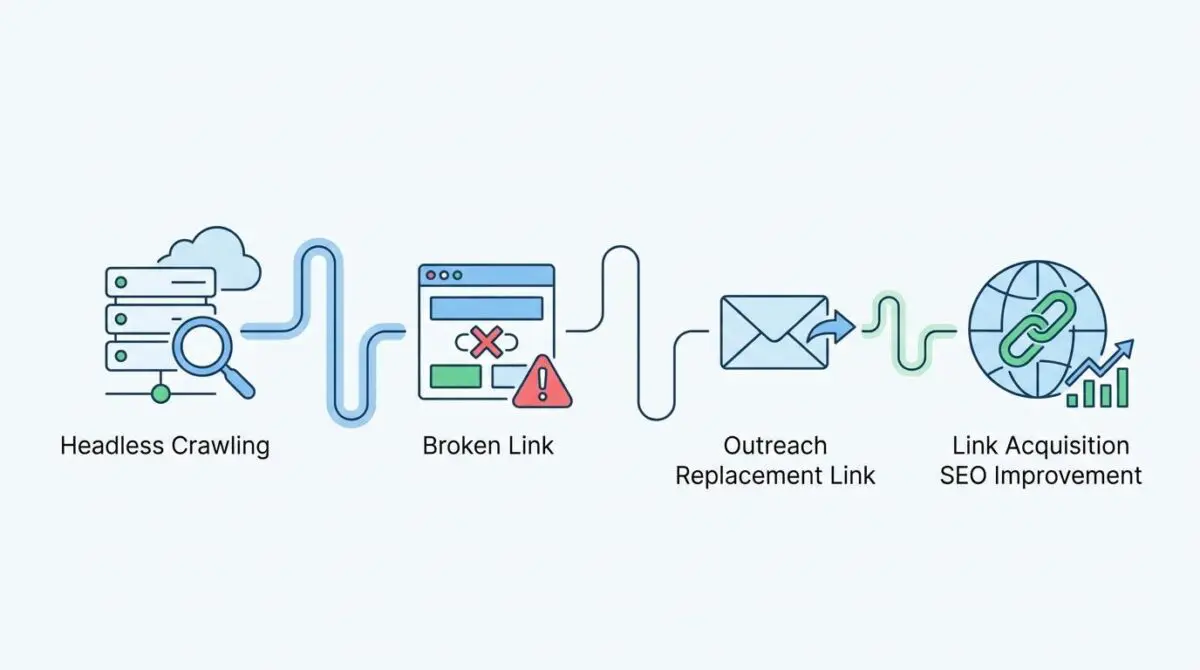
Key Points
- Automated Data Normalization: Headless Screaming Frog instances route crawl data to AWS S3, triggering Python normalization before hitting Zapier to ensure clean CRM injection.
- AI-Driven Lead Filtering: Zapier pathways leverage Pitchbox APIs to bypass manual queues, using LLM filters to remove 92% of junk outreach prospects instantly.
- Zero-Latency Indexing: The IndexNow API eliminates link credit lag by instantly pinging search engines the moment a broken link replacement goes live.
Table of Contents
The Invisible Tax of Manual Prospecting
An invisible tax burdens every SEO team still relying on manual broken link building. It manifests as countless hours lost staring at massive spreadsheet exports, trying to separate high-value outreach targets from digital noise. This architectural bottleneck is widely known as the data-to-pitch latency gap.
When you uncover massive 404-discovery datasets, those raw URLs cannot simply be dumped into a CRM. They require rigorous cleaning and deduplication before they can be safely injected into email sequences. Skipping this step risks triggering spam filters or causing high bounce rates.
The ultimate solution to this friction is deploying a headless crawl-to-outreach automation pipeline. By treating broken link building as a programmatic data flow rather than a manual task, you can bridge the gap between discovery and outreach instantly.
Measuring the Velocity of Automated Discovery

The shift from manual prospecting to programmatic pipelines yields staggering operational efficiencies. Modern workflows have reduced the average discovery-to-outreach cycle from a sluggish 48 hours down to just 14 minutes. This unprecedented prospect identification velocity is largely achieved by running Screaming Frog headless via CLI to constantly monitor target domains in the background.
Speed alone, however, is useless without precision. Integrating LLM-based filtering steps within your automation platform removes the vast majority of junk prospects before they ever reach your outreach tool. This AI-filtered lead accuracy ensures that your domain reputation remains pristine while your pipeline operates at maximum throughput.
Architectural Deep Dives
To truly master this workflow, we must break down the pipeline into its core programmatic components. Each stage of the journey requires specific API integrations to overcome real-world execution friction.
Bypassing the Personalization Bottleneck
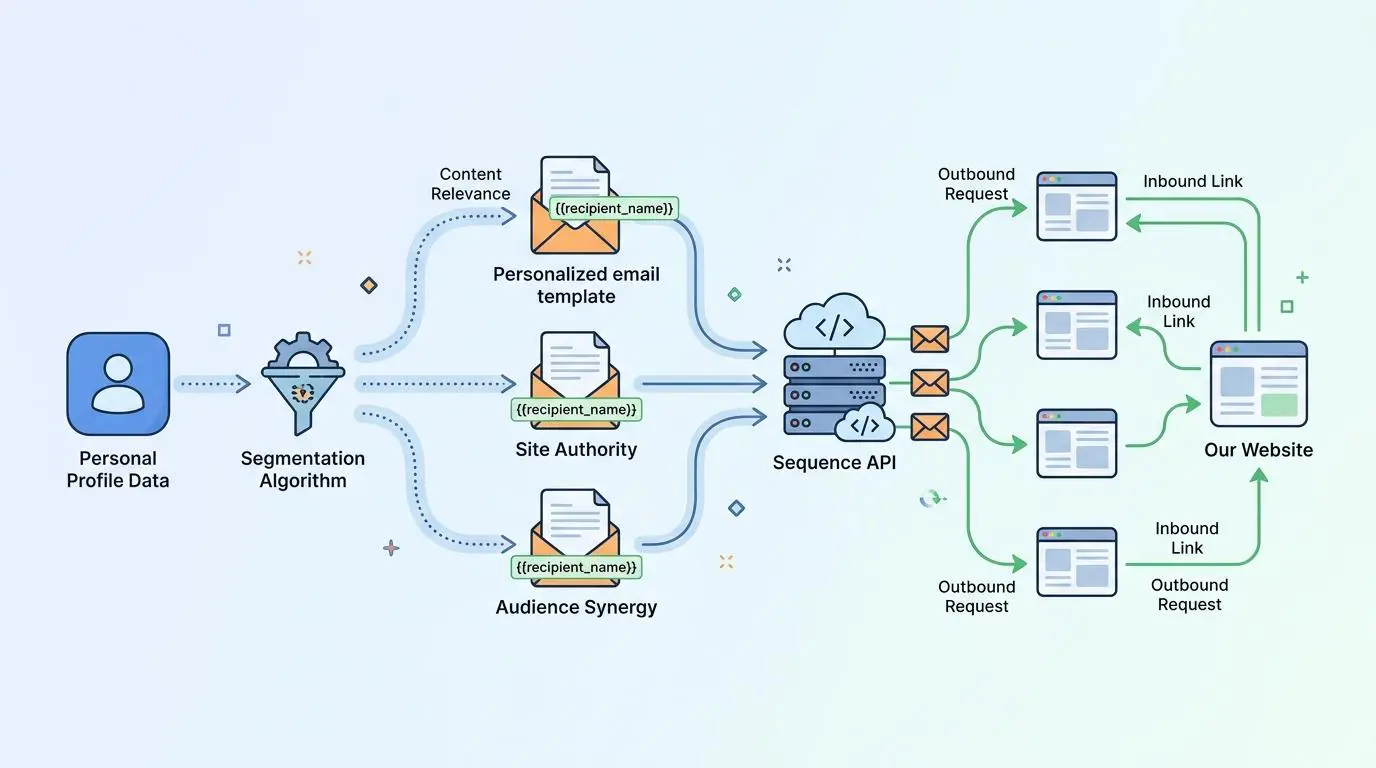
Modern link acquisition requires moving beyond generic templates and embracing hyper-personalization at scale. Simply finding a 404 error is no longer enough to secure a link without context-aware, AI-generated pitch snippets. To achieve this, modern outreach APIs allow for push-to-sequence webhooks that entirely bypass manual approval queues.
Within this flow, automation platforms utilize advanced pathways to branch logic based on the domain rating of the broken link source. High-tier domains receive highly customized, LLM-crafted emails, while lower-tier domains follow a more standardized sequence. This ensures your outreach efforts are proportional to the potential SEO value of the target.
Furthermore, predictive link equity features elevate this personalization. By using local LLMs to scan the anchor text surrounding a 404, you can predict the ranking impact of the replacement link before the outreach email is even sent. This intelligence allows your pipeline to prioritize the most lucrative link opportunities automatically.
Orchestrating the Middleware Data Flow
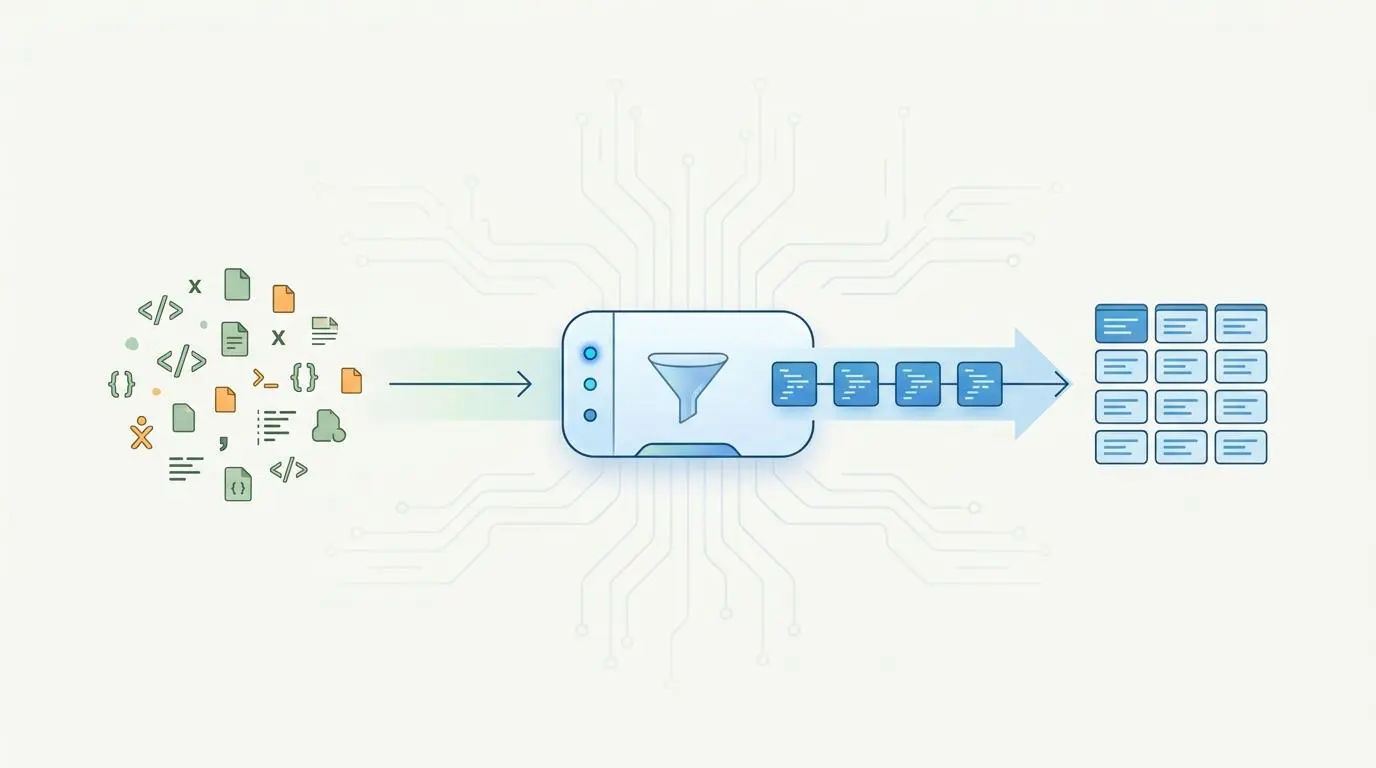
Connecting a crawler directly to an outreach tool is a recipe for disaster without robust middleware. Advanced CLI modes now support direct JSON output to cloud storage buckets, creating a seamless handoff. Once a new crawl file lands in the bucket, it triggers serverless functions to execute Python-based data normalization.
This Python layer cleans the data, removes duplicates, and structures the payload before hitting your automation webhook. However, a major real-world friction point arises when processing high-velocity crawl data from large-scale site scans. API rate limiting on the outreach side often chokes when hit with thousands of concurrent requests.
To prevent data loss, your middleware must incorporate sophisticated queuing logic. By implementing a delay or batch-processing mechanism within your serverless architecture, you ensure a steady, manageable flow of prospects into your CRM. This keeps the entire pipeline stable and efficient.
Navigating Crawl Budgets and Bot Defenses
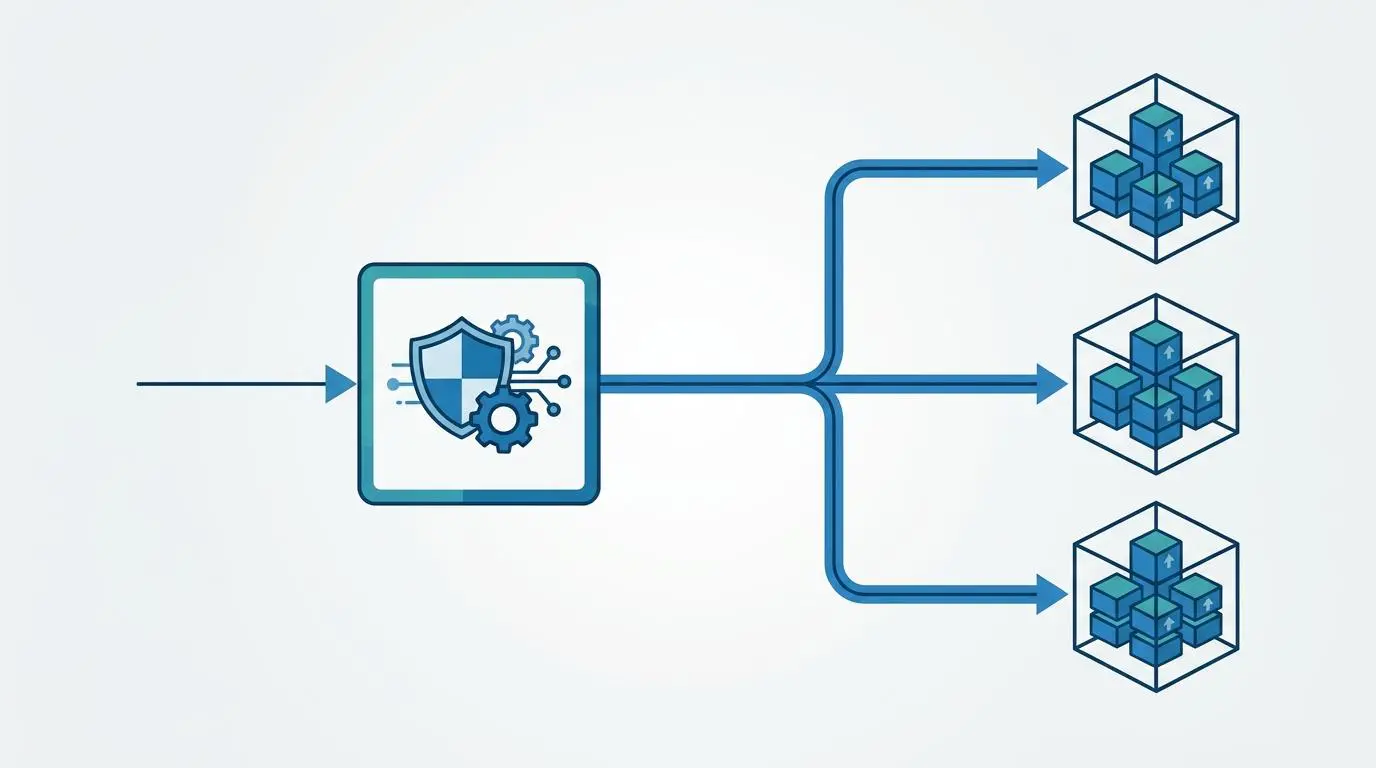
Executing large-scale competitor scans requires a stealthy and efficient infrastructure. Headless crawler instances deployed on Docker containers provide the perfect scalable environment. These containers allow for rotating residential proxies, which is essential to avoid forbidden errors when scanning heavily protected sites for broken outbound links.
However, aggressive headless crawling can inadvertently trigger a target site’s DDoS protection. This misstep often leads to the permanent IP blacklisting of your outreach server. Ultimately, this cripples your ability to gather competitive intelligence.
To mitigate this risk, your crawl speed must be dynamically modulated via API feedback loops. If the proxy network detects an increase in response times or CAPTCHA requests, the crawler must automatically throttle its request rate. This mimics human browsing behavior to stay completely under the radar.
Eliminating the Link Credit Lag
Securing a link replacement is only half the battle. Ensuring search engines actually crawl and credit that link is the final hurdle. The link credit lag occurs when a replaced link exists on a target site but remains unindexed for weeks. This delay is the primary reason automated broken link building campaigns often fail to show immediate ROI.
To solve this, modern pipelines integrate the IndexNow API at the very end of the workflow. Once your outreach platform confirms that a requested link is officially live, a webhook fires immediately.
This webhook triggers a direct ping to search engines, forcing a rapid recrawl of the specific URL. By proactively pushing indexation data rather than waiting for passive crawler discovery, you ensure the new backlink is crawled. This credits the link to your domain’s authority profile almost instantly.
The Dawn of Autonomous Agentic Link Building
The current state of automation is highly efficient, but the future promises an entirely hands-free ecosystem. The process will soon shift toward autonomous agentic link building. AI agents will not only find 404 errors but will also take proactive steps to resolve them on behalf of the webmaster.
These agents will use retrieval-augmented generation to reconstruct the missing content directly on the client’s site. Once the asset is recreated, the agent will negotiate the link replacement via real-time chat on the target site’s support platform. This closes the loop entirely without human intervention.
Navigating the intersection of technical SEO, programmatic architecture, and workflow automation requires a sharp strategy. To future-proof your site’s architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is a headless crawl-to-outreach automation pipeline?
A headless crawl-to-outreach automation pipeline is a programmatic SEO workflow that treats link building as a data flow. It utilizes command-line interface (CLI) crawlers like Screaming Frog to identify broken links in real-time, processes the data through cloud middleware, and triggers personalized email sequences via APIs, effectively eliminating the manual prospecting bottleneck.
How does LLM-based filtering improve the accuracy of link building?
Integrating LLMs within tools like Zapier or AWS Lambda acts as an intelligent gatekeeper for prospect data. According to industry reports, AI-filtered lead accuracy removes up to 92% of low-quality or irrelevant targets before they reach your outreach CRM, which protects your domain’s email reputation and ensures higher conversion rates.
What is the Link Credit Lag and how can it be eliminated?
Link Credit Lag is the delay between a replacement link going live and search engines crawling it to provide ranking value. This hurdle is overcome by integrating the IndexNow API at the end of the pipeline, which proactively pings search engines to recrawl the specific URL immediately after Pitchbox confirms the link is active.
Why is middleware necessary for high-velocity SEO automation?
Middleware, such as AWS Lambda, is essential to bridge the gap between crawlers and outreach tools. It provides necessary data normalization and queuing logic to prevent API rate limiting issues. Without this buffer, sending thousands of concurrent requests from a large-scale scan can crash the receiving CRM’s API and cause data loss.
How can SEO teams avoid IP blacklisting during automated crawls?
To bypass bot defenses and avoid IP blacklisting, headless crawlers should be deployed on Docker containers using rotating residential proxies. Furthermore, implementing API feedback loops allows the crawler to dynamically throttle its request rate if it detects increased response times or CAPTCHA triggers, mimicking human browsing behavior.
What is Autonomous Agentic Link Building?
Emerging as the future of SEO, Autonomous Agentic Link Building involves AI agents that handle the entire lifecycle of a link. These agents identify 404 errors, use Retrieval-Augmented Generation (RAG) to reconstruct missing content for the webmaster, and negotiate link replacements via real-time chat, operating without human intervention.