Key Points
- Content Dilution: Googlebot drops paginated URLs from the index when detecting low-utility fragment bloat or absent semantic differentiation between archive nodes.
- Metadata Injection: Injecting dynamic, page-specific metadata via PHP filters resolves content dilution signals sent to the indexing engine.
- Header Validation: Auditing server response headers and standardizing self-referential canonicals prevents crawl-to-index desynchronization caused by rogue SEO plugins.
The Core Conflict: Indexing Deferral of Paginated Nodes
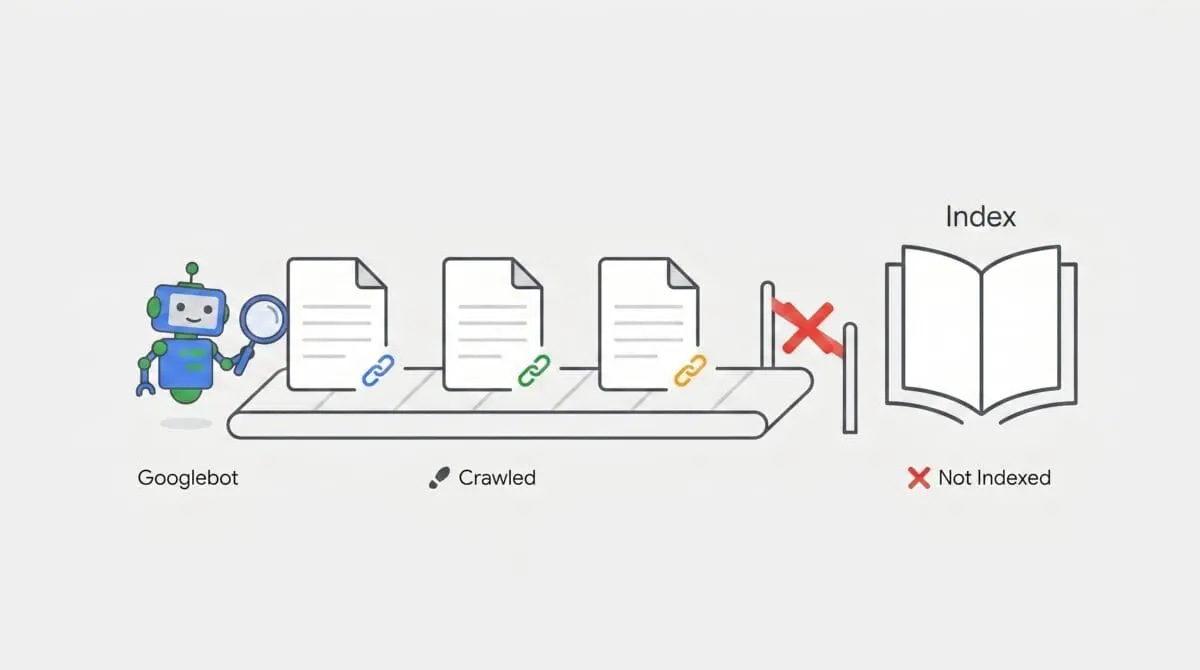
When analyzing server logs and Google Search Console data, encountering the Crawled – currently not indexed status on paginated URLs is a distinct indicator of a crawl-to-index pipeline desynchronization. This status dictates that Googlebot has successfully fetched the URL and the origin server returned a valid 200 OK HTTP status code. However, the indexing pipeline has purposefully deferred the inclusion of these URLs into the active Search index. The fetch was successful, but the semantic evaluation failed.
This anomaly typically manifests when Google algorithms determine that the fetched page does not currently provide sufficient additive value to the index. In modern search architecture, Crawl Budget is strictly prioritized for high-authority, high-utility nodes. When dealing with Generative Engine Optimization, paginated pages are frequently flagged as low-utility fragments. Because they often lack unique semantic entities required for Large Language Model training sets, the indexing engine applies a temporary or permanent exclusion to preserve computational resources.
The symptoms are highly specific. Within the Google Search Console Page Indexing report, paginated paths such as category/page/2/ will populate the Excluded list despite maintaining a healthy 200 status code. Concurrent server log analysis will reveal repeated hits from Googlebot Desktop or Googlebot Smartphone user-agents. These fetches complete successfully, yet they yield zero subsequent organic traffic and fail to appear in site operator queries. This confirms the server is delivering the payload, but the indexing algorithm is rejecting the payload payload upon evaluation.
Diagnostic Checkpoints
Diagnostic Checkpoints
Quality Threshold and Content Dilution
Low-value duplicates lack unique metadata and descriptions.
Internal Link Depth (Crawl Depth)
High click depth reduces distributed Link Equity.
Rendering Budget and Fragment Discovery
JS-content requires secondary rendering passes for discovery.
Understanding the root cause requires analyzing the intersection between the server layer, the edge caching layer, and the application layer. The indexing engine relies on distinct signals to validate the utility of a page. When these signals are absent or degraded, the page is discarded from the indexing queue.
Google employs a strict quality threshold for indexing. If paginated pages lack unique content, they are immediately categorized as low-value duplicates. In environments like WordPress, themes frequently output the category description exclusively on the primary archive page. Subsequent paginated nodes display nothing but a grid of posts or products. Without unique metadata, these pages trigger content dilution filters, causing the indexing engine to skip them entirely to prevent index bloat.
Internal link depth further exacerbates this issue. If paginated pages require a high click depth to reach, Googlebot will eventually crawl them, but the indexing system will deprioritize them. Nodes buried deep within the site architecture lack the necessary Link Equity or PageRank to warrant an index slot. Standard content management systems often utilize basic pagination links that fail to distribute enough internal authority, especially on enterprise sites containing thousands of taxonomy terms.
For applications relying heavily on JavaScript, the rendering budget introduces another point of failure. During the initial crawl, Googlebot fetches the raw HTML. If the paginated content grid is injected client-side via JavaScript, the initial HTML payload appears empty. The URL is placed in the Web Rendering Service queue. If this queue is backlogged, Google temporarily categorizes the empty shell as Crawled – currently not indexed until the secondary rendering pass can execute and discover the injected fragments. This is highly prevalent in Headless setups or implementations utilizing infinite scroll without proper History API routing.
The Engineering Resolution
Engineering Resolution Roadmap
Inject Unique SEO Metadata via Filter
Use a PHP filter in functions.php to append the page number to the Title and Meta Description of paginated archives. This differentiates the pages semantically for Google’s indexing algorithms.
Ensure Proper Header Response
Verify that no ‘X-Robots-Tag: noindex’ is being injected via the server configuration (NGINX/Apache) or SEO plugins. Use ‘curl -I’ to inspect the response headers for the paginated URLs specifically.
Optimize Internal Link Architecture
Implement a ‘breadcrumb’ schema and ensure paginated links are not ‘nofollow’. If using RankMath or Yoast, ensure the ‘Canonical’ tag points to the current paginated URL (self-referential) and NOT the first page of the series.
Resolving this anomaly requires a multi-layered approach to force semantic differentiation and ensure unrestricted crawl pathways. The primary objective is to alter the payload delivered to Googlebot so that the indexing algorithm recognizes the paginated node as a unique, valuable entity rather than a redundant fragment.
The first required modification is semantic differentiation. By injecting dynamic variables into the title tag and meta description of paginated URLs, you force the indexing engine to recognize them as distinct documents. Appending the specific page number to the metadata breaks the duplicate content footprint that triggers the quality threshold filter.
The second modification involves auditing the HTTP response headers. Rogue SEO plugins or misconfigured server blocks often silently inject restrictive directives. If an X-Robots-Tag is present in the header, it will override any on-page directives. Ensuring a clean 200 OK response with explicit index directives at the server level guarantees that the indexing pipeline receives the correct instructions.
The final modification addresses internal link architecture and canonicalization. Paginated URLs must utilize self-referential canonical tags. Pointing the canonical tag of page two back to page one consolidates the signals but instructs Google to drop page two from the index. Additionally, deploying strict breadcrumb schema on paginated nodes provides the crawler with clear hierarchical context, improving the distribution of internal authority.
The Code Implementations
Executing these resolutions requires direct modification of the application codebase and server configuration files. Below are the precise implementations required to resolve the indexing deferral.
Fixing via functions.php
This PHP snippet hooks into the WordPress SEO title generation process. It detects if the current query is a paginated archive and dynamically appends the page number to the title string, ensuring semantic uniqueness.
/* WordPress: Unique Titles for Pagination */
add_filter('wpseo_title', function($title) {
if (is_paged()) {
$title .= ' - Page ' . get_query_var('paged');
}
return $title;
});Fixing via NGINX Configuration
This NGINX location block targets any URL path containing pagination formatting. It explicitly injects an X-Robots-Tag into the HTTP response header, forcing crawler bots to index and follow the links on the page, overriding any conflicting application-level headers.
/* NGINX: Ensure no headers block indexing on pagination */
location ~* /page/[0-9]+ {
add_header X-Robots-Tag "index, follow";
}Fixing via Apache .htaccess
For environments running Apache, this directive utilizes the headers module to match paginated file paths. It sets the identical X-Robots-Tag directive to guarantee that the server response explicitly permits indexing.
/* Apache .htaccess: Force Indexing headers */
Header set X-Robots-Tag "index, follow"
Validation Protocol & Edge Cases
Validation Protocol
- Perform a GSC ‘Live Test’ on the affected URL; check if ‘Indexing allowed?’ says ‘Yes’.
- Run ‘curl -I’ in the terminal to verify the status is 200 and no ‘noindex’ headers exist.
- Use the Chrome DevTools Network tab to ensure no ‘X-Robots-Tag’ is hiding in the response headers.
- Use the ‘Rich Results Test’ to ensure the rendered HTML contains the unique content expected.
Validation must occur immediately following the deployment of server and application modifications. Bypassing validation risks prolonged index exclusion due to cached error states. Utilizing command-line tools ensures you are viewing the raw server response identical to what Googlebot receives, stripping away any browser-based rendering anomalies.
However, edge cases frequently complicate this resolution. A severe conflict can occur when utilizing Cloudflare Automatic Platform Optimization or Edge Cache HTML features. If the origin server previously experienced a transient error state and output a noindex header, the edge server may cache this restrictive directive. Consequently, the edge server will continue serving the stale noindex header to Googlebot for all paginated pages, even after the origin server configuration has been corrected. In these scenarios, a global cache purge at the edge layer is mandatory to allow the new, correct headers to propagate to the crawler.
Autonomous Monitoring & Prevention
Resolving the immediate indexing anomaly is only the first phase; preventing regression requires robust monitoring infrastructure. Enterprise environments cannot rely on manual Google Search Console audits. Implementing automated Log File Analysis using the ELK stack or tools like Screaming Frog Log File Analyser allows engineering teams to monitor the Crawl-to-Index ratio in real-time. By tracking exactly which user-agents are hitting paginated nodes and correlating that data with server response codes, you can identify crawl bloat before it impacts the indexing pipeline.
Furthermore, integrating secondary XML sitemaps specifically dedicated to paginated URLs explicitly signals their structural importance to the indexing engine. Advanced teams should utilize platforms like Make.com to build autonomous pipelines that trigger API alerts whenever a taxonomy node drops from the index. This proactive approach ensures entity integrity is maintained across the entire site architecture. Relying on continuous automated diagnostics is the definitive method for maintaining visibility in modern search ecosystems.
Conclusion
The Crawled – currently not indexed status on paginated URLs is a solvable engineering challenge. By systematically auditing server headers, injecting unique semantic metadata, and standardizing internal link architecture, you can force the indexing pipeline to recognize the utility of your archive nodes. Strict adherence to validation protocols ensures that edge caching layers do not obstruct your technical modifications.
Navigating the intersection of technical SEO, server architecture, and generative search requires a precise roadmap. If you need to future-proof your enterprise stack, resolve deep-level crawl anomalies, or implement AI-driven SEO automation, connect with Andres at Andres SEO Expert.