Key Points
- The 80/20 Flip: LLMs are reversing the historical data bottleneck, enabling autonomous semantic reconciliation and entity resolution across enterprise silos.
- Agentic DataOps: Rigid regex is being replaced by AI agents that self-correct schema drifts and resolve inconsistencies in real-time.
- Self-Healing Fabrics: The future belongs to Zero-Knowledge Data Engineering, where Small Language Models (SLMs) clean data dynamically at the edge.
Table of Contents
The Core Friction: The 80/20 Data Bottleneck
According to Gartner, 40% of enterprise applications will embed task-specific AI agents for automated data remediation by the end of 2026, up from less than 5% in 2024. This massive statistical leap signals the arrival of Augmented Data Quality as a foundational enterprise necessity. We are witnessing the definitive end of the historical data bottleneck.
For over a decade, the brightest data scientists in the world were effectively reduced to digital janitors. They spent 80% of their expensive, highly specialized time manually extracting, transforming, and loading data. This exhausting reality created severe friction when deploying predictive models and advanced analytics.
The financial toll of this bottleneck was staggering for modern enterprises. Delayed time-to-market for AI initiatives and the sheer operational cost of manual data wrangling drained millions from IT budgets. Data teams were drowning in backlog, unable to focus on high-yield strategic initiatives.
Traditional data cleaning relied heavily on rigid regex and hardcoded rules. These deterministic pipelines were incredibly brittle, breaking the moment a new data format emerged or a schema drifted. Engineers were trapped in a perpetual cycle of patching broken pipelines instead of building strategic assets.
Today, Large Language Models have completely flipped this operational ratio. Augmented Data Quality replaces brittle scripts with autonomous AI agents capable of interpreting unstructured data with human-like context. This allows systems to automate semantic reconciliation and entity resolution across disparate, multi-cloud silos.
This transition from manual ETL to LLM-driven data synthesis is not merely an operational upgrade. It is a fundamental reimagining of how enterprises process, route, and trust their underlying information architecture. The era of human-in-the-loop data cleaning is rapidly drawing to a close.
Market Intelligence & Smart Capital
Market Intelligence & Data
AI Automation Market Cap
The global market for AI-driven automation is projected to reach this milestone by the end of 2026, driven by a 23.4% CAGR according to Grand View Research.
Operational Cost Reduction
Enterprises utilizing LLM-native data processing report an average reduction in operational overhead as cited by Boston Consulting Group (BCG).
Q1 2026 AI Funding
Venture capital investment into AI and automation startups reached this record high in only the first three months of 2026, per Crunchbase data.
Productivity Multiplier
A McKinsey study finds that over half of business leaders expect exponential productivity gains from successfully integrating agentic AI into their data workflows.
The financial metrics surrounding this technological shift paint a clear picture of where the smart money is moving. Venture capital activity has peaked, with Crunchbase reporting that 80% of all venture dollars in Q1 2026 were funneled into AI-native automation infrastructure. Investors are aggressively rewarding platforms that eliminate manual data friction.
This capital influx is driven by the realization that application-layer AI is useless without pristine data infrastructure. Smart money is betting on the plumbing, funding the very systems that make enterprise-grade generative AI possible. The market has recognized that automated data remediation is the ultimate bottleneck to scale.
We are seeing a massive shift from descriptive analytics to predictive, multi-agent workflows. Enterprises are no longer satisfied with static dashboards that report on historical data inconsistencies. They demand dynamic, self-correcting fabrics that repair data in real-time before it impacts downstream applications.
The Death of Manual ETL
Market dominance is currently held by incumbent leaders like Informatica and Qlik. These legacy giants have successfully pivoted their core offerings to fully agentic platforms to survive the disruption. Meanwhile, Oracle’s Autonomous Database now handles 90% of preprocessing without human intervention.
Traditional SQL-based transformations are simply too slow to keep pace with the velocity of modern unstructured data. Writing complex JOINs and CASE statements to clean messy text fields is an archaic practice in the age of generative models. The industry is demanding semantic understanding over syntactic manipulation.
However, the true disruptive innovation is emerging from agile, AI-native startups. Companies like Ada.im are capturing market share by automating SQL generation and data cleaning in under five minutes. These platforms prove that speed and semantic understanding can outmaneuver legacy data integration tools.
Interoperability is also driving massive valuations in the startup ecosystem. StackOne recently secured $20M to bridge unified APIs for agentic data access, highlighting the demand for seamless multi-cloud connectivity. Enterprises require frictionless data movement to feed their hungry AI models.
The ultimate goal of this capital deployment is massive operational efficiency. Business leaders are actively anticipating exponential productivity gains from successfully integrating agentic AI into their core data workflows. The strategy is clear: replace human effort with scalable, autonomous agents.
The Strategic Deep Dive: Agentic DataOps
Data from Gartner reveals a 1,445% explosion in multi-agent system inquiries between 2024 and 2025 as enterprises rapidly abandon manual ETL in favor of LLM-driven data synthesis. This staggering metric highlights a profound psychological shift within the modern C-suite. Executives no longer view dirty data as a simple IT chore, but as a critical strategic vulnerability.
This realization has birthed the era of Agentic DataOps. In this new paradigm, multi-agent systems collaborate autonomously to map, clean, and route data across the enterprise fabric. It represents a quantum leap from static processing to dynamic, context-aware data management.
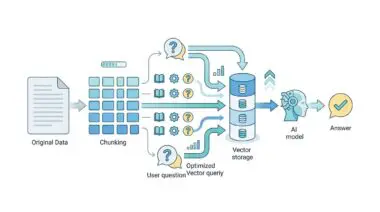
Modern data architectures are increasingly relying on vector databases to assist in this semantic mapping. By converting unstructured data into high-dimensional vectors, AI agents can instantly identify hidden relationships and anomalies. This allows for lightning-fast entity resolution without relying on exact string matches.
Semantic Data Engineering
The core engine powering Agentic DataOps is Semantic Data Engineering. This approach utilizes metadata-driven architectures to allow AI to understand the actual meaning behind data fields. Instead of relying on exact character matches, the system uses semantic proximity to resolve inconsistencies.
When a schema drifts or an API payload changes unexpectedly, traditional pipelines instantly fail. Semantic Data Engineering allows the LLM to analyze the new structure, infer the intended mapping, and self-correct the pipeline in real-time. This autonomous resilience prevents costly downstream outages.
As this semantic capability matures, software architecture itself is evolving. Gartner predicts 40% of enterprise applications will embed task-specific AI agents to handle these exact remediation tasks natively. Data will soon be cleaned at the point of creation, rather than in a centralized batch process.
Solving Confidently Wrong AI
The urgency behind adopting Semantic Data Engineering stems from the enterprise nightmare of AI hallucinations. When generative models are fed dirty, unstructured, or conflicting data, they do not simply fail gracefully. They produce confidently wrong outcomes that can severely damage business operations and brand trust.
The regulatory risks associated with these hallucinations are becoming a boardroom priority. If an AI agent hallucinates a financial projection or misinterprets private customer data due to poor preprocessing, the compliance fallout can be devastating. Augmented Data Quality mitigates this risk by ensuring mathematical and semantic precision.
Building an enterprise AI strategy on manual ETL is like constructing a skyscraper on a foundation of mud. Augmented Data Quality acts as the digital immune system for these advanced models. It rigorously filters out toxins, anomalies, and duplicates before they can infect the primary decision-making engine.
By solving this critical enterprise problem, companies can finally move from experimental pilots to production-ready systems. These mission-critical AI agents require zero-latency, high-integrity data streams to function safely. Agentic DataOps guarantees this continuous flow of pristine information.
The Executive Action Plan: Self-Healing Data Fabrics
Strategic Trajectory
- Implement a ‘Self-Healing Data Fabric’ to evolve beyond traditional static pipelines.
- Transition toward human-out-of-the-loop systems for end-to-end data processing.
- Deploy Small Language Models (SLMs) at the edge for pre-warehouse cleaning and validation.
- Pivot to ‘Zero-Knowledge Data Engineering’ to focus on high-level strategic outcomes.
- Establish autonomous ‘Data Contracts’ that allow AI to maintain data integrity independently.
The next logical evolution in enterprise architecture is the Self-Healing Data Fabric. Founders and chief technology officers must prepare for a future where data pipelines operate entirely without human oversight. This requires a fundamental shift in how organizations deploy and manage computational resources.
Deploying SLMs at the Edge
Forward-thinking organizations are already moving away from massive, centralized language models for routine data tasks. Instead, they are deploying highly specialized Small Language Models directly at the edge. These SLMs are trained specifically for data validation, entity extraction, and schema mapping.
By utilizing SLMs at the edge, data is cleaned and standardized before it ever hits the central warehouse. This localized processing dramatically reduces cloud compute costs and minimizes network latency. It also enhances security by sanitizing sensitive information at the source.
This shift has massive hardware implications for enterprise infrastructure. We are seeing a surge in Neural Processing Unit integration at the edge to support these localized SLMs. The hardware and software are evolving in tandem to support decentralized, autonomous data remediation.
This distributed approach to Augmented Data Quality ensures that the central data fabric remains pristine. It prevents the historical data swamp scenario where raw, unusable information is dumped into a data lake for future processing. Edge-based SLMs enforce strict quality controls at every entry point.
Zero-Knowledge Data Engineering
Ultimately, this technological trajectory leads the industry toward Zero-Knowledge Data Engineering. In this future paradigm, human engineers will completely stop managing the granular mechanics of data pipelines. The focus will shift entirely from operational maintenance to defining high-level strategic outcomes.
This transition requires a massive cultural shift within engineering teams. Data professionals must evolve from pipeline mechanics into AI orchestrators. They will no longer write code to move data; they will write logic to govern AI behavior.
Executives will establish autonomous Data Contracts that dictate the required quality, latency, and structure of business data. The multi-agent AI system will then take full responsibility for maintaining these contracts globally. If a data source violates the contract, the AI will autonomously quarantine, remediate, or reroute the flow.
Zero-Knowledge Data Engineering empowers organizations to scale their data infrastructure infinitely without scaling their engineering headcount. It removes the final friction point in enterprise data monetization. The AI handles the complexity, while the humans command the strategy.
Conclusion: The Autonomous Future
The automation of data cleaning via Augmented Data Quality is the ultimate catalyst for enterprise AI scaling. By eliminating the manual ETL bottleneck, companies can finally unlock the true predictive value of their unstructured data. The transition from rigid pipelines to self-healing fabrics is no longer an optional upgrade.
As LLMs and SLMs take over the granular tasks of semantic reconciliation, human talent is freed to focus on innovation. The organizations that embrace Agentic DataOps today will command the competitive landscape of tomorrow. They will operate with a level of speed and precision that legacy architectures simply cannot match.
The era of the digital janitor is over. The age of the autonomous data fabric has arrived. Enterprises must adapt their infrastructure now or risk being outpaced by AI-native competitors who trust their data implicitly.
Navigating the intersection of technology, capital, and market psychology requires a sharp strategy. To future-proof your business architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is Augmented Data Quality?
Augmented Data Quality is a modern approach to data management that utilizes AI agents and Large Language Models (LLMs) to automate semantic reconciliation, entity resolution, and data remediation, effectively replacing manual ETL processes.
How do AI agents solve the 80/20 data bottleneck?
AI agents eliminate the historical friction where data scientists spent 80% of their time on manual data cleaning. By automating data synthesis, these systems allow teams to focus on strategic initiatives rather than digital janitorial tasks.
What is Semantic Data Engineering?
Semantic Data Engineering uses metadata-driven architectures to help AI understand the meaning of data fields. This allows pipelines to self-correct in real-time when facing schema drift or unexpected API changes without breaking.
Why should enterprises use Small Language Models (SLMs) at the edge?
Deploying SLMs at the edge allows for data validation and cleaning at the point of creation. This decentralized approach reduces cloud compute costs, minimizes latency, and prevents raw, unusable data from entering the central warehouse.
How does Augmented Data Quality prevent AI hallucinations?
By acting as a digital immune system, Augmented Data Quality rigorously filters out anomalies and duplicates. This ensures that generative models are fed high-integrity data, significantly reducing the risk of producing confidently wrong outcomes.
What is Zero-Knowledge Data Engineering?
Zero-Knowledge Data Engineering is a paradigm shift where engineers stop managing granular pipeline mechanics and instead focus on defining high-level strategic logic and autonomous Data Contracts for AI orchestrators to follow.