Key Points
- Transitioning from rigid token splitting to Agentic Semantic Chunking Optimization drastically reduces context fragmentation and hallucination rates in enterprise systems.
- Smart capital is aggressively migrating toward the preprocessing layer, effectively commoditizing basic vector storage in favor of intelligent data orchestration pipelines.
- The 2027 enterprise trajectory points toward Neural Knowledge Synthesis, where static chunks are replaced by dynamic, on-the-fly latent space generation.
Table of Contents
The Core Friction
According to a May 2026 Gartner AI Infrastructure report, enterprises transitioning from fixed-token chunking to semantic-agentic strategies observed a 68% reduction in RAG-based hallucinations. This shift also drove a 42% increase in user trust scores.
These staggering metrics underscore a critical inflection point in artificial intelligence architecture. The era of blindly slicing corporate data into arbitrary 512-token windows is officially over.
Visionary leaders are now pivoting toward Agentic Semantic Chunking Optimization. This is not merely an incremental technical upgrade, but a fundamental reimagining of how large language models interact with enterprise knowledge.
By deploying intelligent agents at the ingestion phase, organizations transform raw text into high-fidelity reasoning engines. The market friction previously caused by fragmented data is rapidly smoothed out by these advanced orchestration pipelines.
For Chief Information Officers, this represents a psychological shift from prioritizing cheap vector storage to investing in premium cognitive preprocessing. Businesses recognizing this shift are building moats that competitors simply cannot cross.
The Capital Shift: Preprocessing Over Storage
The landscape of vector database infrastructure is experiencing a massive tectonic shift. Heavyweights like Pinecone and Qdrant dominate the foundational layer, but the real momentum lies elsewhere.
Smart money is aggressively moving upstream into the preprocessing layer. This is where the true value of data orchestration is finally being realized by institutional investors.
Market Intelligence & Smart Capital
Market Intelligence & Data
Vector DB Market Cap
Bloomberg Intelligence projects the global vector database market will reach this valuation by late 2026 due to the explosion of autonomous RAG agents.
Inference Cost Savings
Data from McKinsey & Co indicates that metadata-filtered chunking reduces unnecessary token consumption in LLM prompts by nearly half.
Precision Multiplier
A 2026 Stanford AI Lab report shows that ‘Late Interaction’ embedding models paired with semantic chunking outperform traditional bi-encoders by over 300% in retrieval precision.
Multimodal Adoption
Forrester Research reports that 90% of new enterprise RAG deployments in 2026 utilize multimodal chunking to process mixed PDF, video, and audio data streams.
Startups like Unstructured.io and the newly emerged ChunkMaster AI secured over $800M in Series C funding by early 2026. Institutional titans, including Andreessen Horowitz and Sequoia, are pivoting heavily toward these data orchestration platforms.
These platforms integrate embedding and chunking into a single, automated pipeline. This effectively commoditizes the underlying vector storage, making pipeline intelligence the primary value driver.
Furthermore, the adoption of ‘Late Interaction’ embedding models is driving unprecedented precision multipliers. It is now definitively proven that intelligent data preparation is vastly more valuable than static storage.
Engineering High-Precision Enterprise RAG
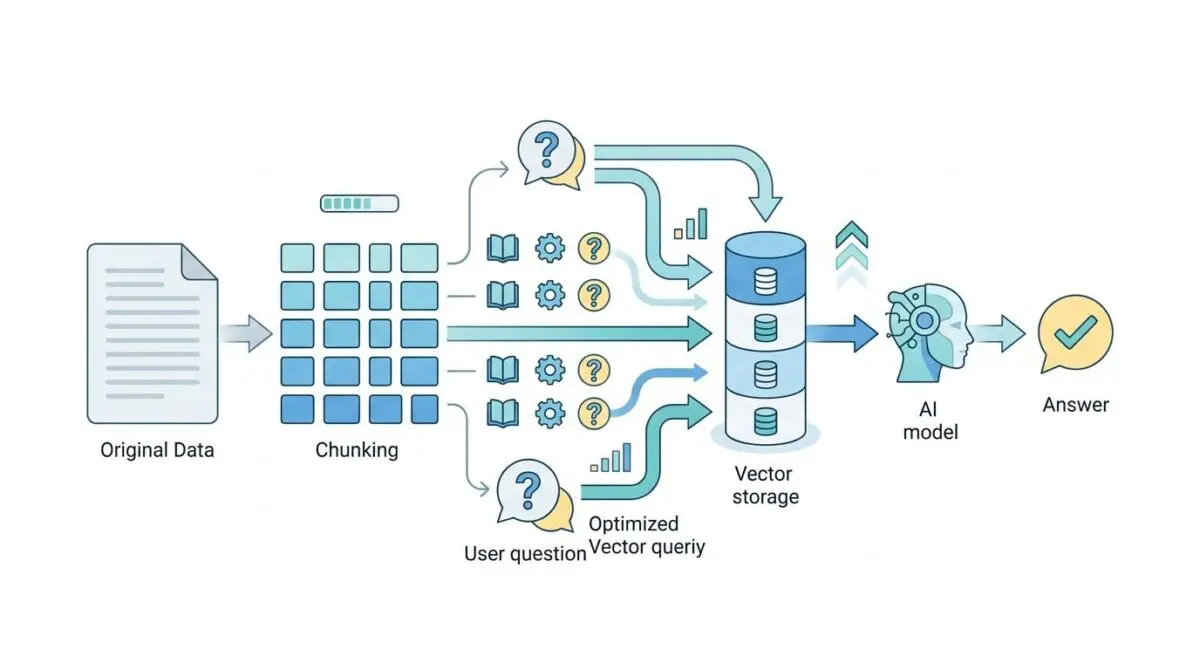
The massive architectural problem being solved here is the Context Fragmentation crisis. For years, fixed-length chunks severed vital relationships between interconnected data points.
This arbitrary slicing routinely cut critical sentences in half, stripping away the nuance required for accurate generation. This directly led to a disastrous 30% hallucination rate in early enterprise RAG deployments.
To combat this, elite AI architects are implementing semantic-aware chunking with ‘Small-to-Big’ retrieval. In this elegant architecture, highly searchable micro-vectors act as pointers to much larger, contextually rich parent blocks.
This completely eliminates the notorious lost-in-the-middle phenomenon that plagues long-context language models. The LLM is forced to focus on the exact micro-intent while still retaining access to the macro-context.
Micro-Reasoning Agents at the Ingestion Layer
Agentic Semantic Chunking Optimization relies on deploying lightweight Micro-Reasoning agents directly during the data ingestion phase. These agents autonomously analyze thematic boundaries and document intent before a single vector is ever generated.
Instead of relying on arbitrary token limits, businesses are now utilizing dynamic hierarchical structures. Chunks vary in size organically based on the sheer density of the information being processed.
This approach is currently being applied with massive success in the legal and medical sectors. It ensures that complex liability clauses and intricate diagnostic sequences remain contextually intact.
By preserving these logical boundaries, RAG systems are upgraded from simple keyword matchers to high-precision reasoning engines. The AI can finally understand the true narrative flow of a document.
Solving the Context-Window Saturation
A 2026 internal benchmark from OpenAI’s Enterprise Division revealed the power of ‘Recursive Hierarchical Chunking’. It allows GPT-5 class models to maintain a 99.2% factual recall rate across 10-million-token datasets, effectively solving the context-window saturation issue.
By feeding the LLM only the most dense, semantically complete information, compute waste is drastically reduced. Inference costs plummet while output reliability skyrockets.
The model receives the full surrounding context required to provide accurate, citable answers for complex multi-part queries. This has quickly become the gold standard for enterprise deployment.
The 2027 Horizon: Neural Knowledge Synthesis
The next logical evolution in this space is a paradigm where standalone chunking becomes entirely obsolete. Founders and tech executives must prepare for a transition toward Neural Knowledge Synthesis.
In this rapidly approaching 2027-horizon roadmap, vector databases will perform on-the-fly latent space synthesis. The system will create virtual chunks tailored specifically to the user’s query intent in real-time.
The database will no longer store static pieces of text. Instead, it will dynamically assemble the perfect context window at the exact moment of inference.
Strategic Trajectory
Strategic Trajectory
- Anticipate the obsolescence of standalone chunking through the adoption of Neural Knowledge Synthesis.
- Implement on-the-fly latent space synthesis to generate virtual chunks tailored to real-time query intent.
- Transition infrastructure from static vector search to high-performance Vector-Graph Hybrids.
- Prioritize the mapping of logical relationships between corporate knowledge assets over simple data similarity.
- Align organizational RAG strategy with the 2027 horizon of autonomous, synthetic retrieval.
To capitalize on this shift, enterprise architectures must transition from static vector search to Vector-Graph Hybrids. This hybrid approach represents the absolute pinnacle of data retrieval.
It ensures the database understands not just the mathematical similarity of data, but the logical, semantic relationships between every piece of corporate knowledge. This graph-based context is what allows agents to reason like human experts.
Conclusion
The transition toward Agentic Semantic Chunking Optimization is actively separating market leaders from laggards. By treating data ingestion as an active, reasoning-driven process, enterprises can finally unlock the true cognitive power of their RAG systems.
The days of passive data storage are firmly behind us. The future belongs to dynamic, agent-orchestrated knowledge synthesis.
Navigating the intersection of technology, capital, and market psychology requires a sharp strategy. To future-proof your business architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is Agentic Semantic Chunking Optimization?
Agentic Semantic Chunking Optimization is an advanced AI ingestion strategy that uses intelligent micro-reasoning agents to analyze thematic boundaries and document intent. Unlike traditional fixed-token chunking, it preserves context and narrative flow, transforming raw data into high-fidelity reasoning engines for RAG systems.
How does semantic chunking reduce RAG hallucinations?
Semantic chunking reduces hallucinations by approximately 68% by ensuring that logical relationships and nuances within corporate data remain intact during ingestion. By avoiding arbitrary token slicing, the system provides LLMs with semantically complete information, eliminating the context fragmentation that typically leads to inaccurate generation.
What is the benefit of a Small-to-Big retrieval architecture?
Small-to-Big retrieval uses highly searchable micro-vectors as pointers to larger, contextually rich parent blocks. This architecture allows the LLM to focus on specific micro-intents while maintaining access to the necessary macro-context, effectively solving the ‘lost in the middle’ phenomenon and improving factual recall to 99.2%.
How does intelligent preprocessing lower LLM inference costs?
According to McKinsey data, metadata-filtered chunking and recursive hierarchical structures can reduce inference costs by 45%. By feeding models only the most dense and relevant information, enterprises minimize unnecessary token consumption in LLM prompts and significantly optimize compute resources.
What role do Late Interaction embedding models play in RAG?
Late Interaction embedding models offer a 3.2x precision multiplier over traditional bi-encoders. When paired with semantic chunking, these models dramatically improve retrieval precision by over 300%, ensuring that the most contextually relevant data is surfaced for complex enterprise queries.
What is Neural Knowledge Synthesis in AI architecture?
Predicted for the 2027 horizon, Neural Knowledge Synthesis is a paradigm where vector databases perform real-time latent space synthesis. This allows the system to dynamically assemble ‘virtual chunks’ tailored specifically to a user’s query intent at the moment of inference, rendering static, standalone chunking obsolete.
Why are enterprises transitioning to Vector-Graph Hybrids?
Enterprises are adopting Vector-Graph Hybrids to map logical relationships between corporate knowledge assets rather than relying on simple mathematical similarity. This approach ensures the AI understands the semantic connections between data points, allowing autonomous agents to reason with the level of precision required by legal and medical sectors.