Key Points
- Server-Side Allowlisting: Implementing NGINX dimension allowlists prevents arbitrary query parameters from exhausting origin server CPU via unbounded image generation.
- Header Injection: Injecting X-Robots-Tag noindex headers on dynamic media URLs preserves crawl budget by preventing search index bloat.
- Cache Key Normalization: Edge-side cache key normalization via Cloudflare ensures redundant parameter permutations are served from cache, mitigating origin hits.
Table of Contents
The Core Conflict: Infinite Image URL Crawl Traps
According to a 2025 technical SEO study by the HTTP Archive, ‘Crawl Bloat’ caused by dynamic media parameters accounts for a 34% waste in total crawl budget on enterprise-scale WordPress installations, often leading to a 12-day delay in the indexation of new content.
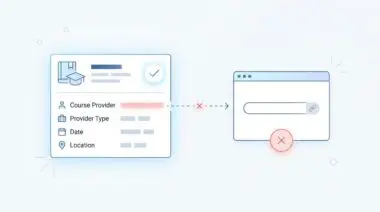
This catastrophic inefficiency is frequently driven by an Infinite Image URL Crawl Trap. This specific anomaly occurs when dynamic image resizing logic generates a unique, valid URL for every possible permutation of dimensions, filters, or quality settings provided via query parameters.
When Googlebot-Image encounters these infinite permutations, it does not inherently understand that they are duplicates of a single asset. Instead, it attempts to crawl every single variation it discovers. This leads to an exponential increase in server-side image processing requests.
The result is severe CPU and RAM exhaustion. The origin server attempts to generate and serve thousands of unique binary files in real-time. Image processing libraries like GD Library or ImageMagick are highly resource-intensive, and concurrent requests quickly consume all available worker processes.
In Google Search Console, this issue is highly visible. It manifests as a massive spike in ‘Image’ file types within the Crawl Stats report. This spike is usually accompanied by a sharp increase in total download time and average response time.
Server logs will simultaneously show thousands of 200 OK requests from the ‘Googlebot-Image’ user-agent. These requests will specifically target URLs with non-standard query parameters, such as image.jpg?w=451 or image.jpg?w=452.
In the era of Generative Engine Optimization (GEO), these crawl traps destroy your organic visibility. AI-driven search engines prioritize high-value asset discovery over redundant media files. When a crawler is bogged down by millions of image variants, it fails to discover new content or update existing page rankings.
Furthermore, the resulting high Time to First Byte (TTFB) during these crawl spikes severely degrades Core Web Vitals. This latency signals to search algorithms that the infrastructure is unstable. Unstable infrastructure is deemed unsuitable for premium ranking placement in modern search ecosystems.
Diagnostic Checkpoints for Server Exhaustion
Resolving this issue requires identifying the exact layer where the desynchronization occurs. The problem could stem from the origin server, the edge caching layer, or the application code itself.
Diagnostic Checkpoints
Unbounded Dynamic Resizing Parameters
Restrict image resizing parameters to an authorized allowlist only.
Search-Discovery of Non-Canonical Thumbnails
Prevent indexing of non-canonical image variations via robots headers.
Sitemap Pollution via Dynamic Hooks
Audit sitemap filters to exclude auto-generated dynamic image URLs.
Lack of Edge-Side Cache Key Normalization
Configure CDN to normalize query strings and prevent origin hits.
Dissecting the Root Causes
At the application layer, unbounded dynamic resizing parameters are the primary culprit. Server-side scripts, such as PHP-based TimThumb successors or custom dynamic resizers, often fail to validate parameters against a strict allowlist.
This architectural flaw allows any arbitrary integer value for width or height to trigger a completely new image generation process. In WordPress environments, themes using dynamic scaling functions in functions.php are common offenders. Plugins that use ‘on-the-fly’ regeneration without restricting the output to registered WordPress image sizes also create massive vulnerabilities.
Simultaneously, search engines discover these variations through ‘src-set’ attributes or JavaScript-rendered galleries that link to specific crops. Popular slider or gallery plugins, like Revolution Slider or Elementor widgets, often generate ‘pre-load’ links for every possible device breakpoint.
If these variations lack proper indexing directives, the crawler treats each as a unique, indexable asset. It is easy to waste crawl budget on auto-generated URL parameters if these pre-load links are not strictly controlled.
Sitemap pollution via dynamic hooks further exacerbates the problem. XML sitemap generators may inadvertently hook into the wp_get_attachment_image_src filter. This accidentally includes every generated thumbnail variation instead of just the original source file.
This bloats the sitemap with thousands of low-value URLs. A frequent example is a conflict between RankMath or Yoast SEO and image optimization plugins like ShortPixel or EWWW. The ‘WebP’ or ‘AVIF’ versions are served via unique query strings that get indexed.
Finally, a lack of edge-side cache key normalization ensures that every unique parameter hits the origin server. CDNs like Cloudflare or Akamai treat image.jpg?v=1 and image.jpg?v=2 as entirely different objects.
If the CDN isn’t configured to ignore or normalize these parameters, the origin server absorbs the full impact of the crawl spike. This is common on WordPress sites using a CDN but failing to enable ‘Query String Management’ or using Cloudflare Workers that bypass the origin incorrectly.
The Engineering Resolution Roadmap
Stopping the crawl trap requires a multi-layered approach. You must block the crawler, restrict the application, and normalize requests at the edge.
Engineering Resolution Roadmap
Implement Robots.txt Disallow for Parameters
Add ‘Disallow: /*?*w=’ and ‘Disallow: /*?*h=’ to the robots.txt file to immediately signal Googlebot-Image to stop crawling parameter-based variations.
Enforce Server-Side Dimension Allowlisting
Modify the image processing logic (PHP/NGINX) to only process requests where the ‘w’ and ‘h’ parameters match your site’s registered dimensions (e.g., 150, 300, 1024). Return a 403 Forbidden for all other requests.
Inject X-Robots-Tag Headers
Use a server-level configuration to detect if a query string is present in an image request and inject ‘X-Robots-Tag: noindex’ into the HTTP response header for those specific requests.
Normalize Query Strings at the Edge
In Cloudflare, create a Cache Rule to ‘Ignore Query String’ for image extensions or use a Page Rule to cache ‘Everything’ only for specific valid dimensions.
Technical Context of the Fix
The first immediate action is updating the robots.txt file to halt the bleeding. By adding Disallow: /*?*w= and Disallow: /*?*h= to the file, you immediately signal Googlebot-Image to stop crawling parameter-based variations.
However, robots.txt directives do not prevent indexing if the URLs are linked externally. They also do not protect against rogue bots that ignore the standard protocol. Therefore, server-level enforcement is mandatory.
To secure the application layer, you must enforce server-side dimension allowlisting. By modifying the image processing logic in PHP or NGINX, you can restrict processing to a predefined set of registered dimensions. Common valid dimensions might include 150, 300, or 1024 pixels.
Any request falling outside this strict allowlist must be rejected immediately. Returning a 403 Forbidden status prevents the server from wasting CPU cycles on unauthorized image generation.
For variations that are allowed to exist but should not be indexed, injecting X-Robots-Tag: noindex headers is crucial. A server-level configuration can detect query strings in image requests and append the header directly to the HTTP response.
This keeps the valid variations out of the search index without breaking front-end functionality. It ensures that only the canonical image URL is considered for ranking.
Lastly, normalizing query strings at the edge prevents valid but redundant requests from overwhelming the origin. By configuring your CDN to ignore query strings for image extensions, you ensure that the edge serves a single cached version. In Cloudflare, creating a Cache Rule to ‘Ignore Query String’ for image extensions is highly effective.
Executing the Resolution via NGINX
Implementing the server-side allowlist and header injection requires direct modification of your server configuration. The following NGINX block demonstrates how to intercept dynamic image requests, validate the parameters, and append the necessary indexing directives.
This configuration ensures that only specific widths and heights are processed. It immediately rejects arbitrary values with a 403 error, protecting your CPU from exhaustion.
location ~* \.(jpg|jpeg|png|gif|webp)$ {
if ($arg_w !~ "^(|150|300|600|1024|1200)$") {
return 403;
}
if ($arg_h !~ "^(|150|300|600|1024|1200)$") {
return 403;
}
add_header X-Robots-Tag "noindex, nofollow";
try_files $uri =404;
}By utilizing regular expressions against the $arg_w and $arg_h variables, NGINX evaluates the query string before the request reaches PHP. The add_header directive ensures that even authorized dimensions are tagged with noindex, nofollow.
Validation Protocol and Edge Cases
Deploying server-level restrictions requires immediate validation. You must ensure legitimate traffic is not inadvertently blocked while confirming the crawler is restricted.
Validation Protocol
- Execute ‘curl -I’ on a random dimension URL to verify 403 Forbidden status or ‘noindex’ headers.
- Use Google Search Console ‘Live Test’ on specific parameter URLs to confirm they are ‘Blocked by robots.txt’.
- Tail NGINX access logs with grep to ensure Googlebot-Image requests are rejected or served via cache.
Handling CDN Conflicts
When you need to troubleshoot crawling errors caused by server capacity limits, validating your server response headers is the first critical step. You can immediately verify the fix by running curl -I in the terminal on a restricted dimension URL.
This command should return a 403 Forbidden status. Alternatively, if testing an allowed dimension, it should return a 200 OK but contain the noindex header. Using the Google Search Console ‘Live Test’ on a known parameter URL will ensure it shows as ‘Blocked by robots.txt’.
Finally, check the NGINX access logs. Running tail -f /var/log/nginx/access.log | grep Googlebot-Image ensures requests are being rejected or served from cache. However, edge cases can complicate this validation process.
A notable conflict arises when using Cloudflare Polish or Image Resizing with an authenticated origin setup. If the origin server is configured to block parameters, but the Cloudflare Edge Worker attempts to fetch those resized versions to cache them, the worker will receive a 403 error.
This results in broken images across the entire site. Resolving this specific edge case requires allowlisting the CDN’s IP range within your NGINX configuration. Alternatively, you can utilize a specific bypass header to ensure the Edge Worker can always access the origin, bypassing the parameter block.
Autonomous Monitoring and Prevention
Preventing future crawl traps requires proactive infrastructure management. Relying on manual log reviews is insufficient for enterprise-scale environments.
You must establish an automated log analysis pipeline using tools like GoAccess or the ELK Stack. Configure these systems to trigger alerts whenever a single user-agent requests more than 500 unique image parameters per hour. This threshold indicates abnormal crawling behavior.
Transitioning to a modern Image CDN, such as Cloudflare Images or Imgix, is highly recommended. These platforms handle all resizing at the edge and prevent origin-hit exhaustion through the use of cryptographically signed URLs.
By signing the URLs, you guarantee that only permutations generated by your application are processed. Any arbitrary parameter manipulation by a bot or malicious actor will result in an invalid signature, blocking the request at the edge.
Implementing advanced automation, such as Make.com pipelines integrated with custom API alerts, is the ultimate way to monitor entity integrity. Andres SEO Expert utilizes these exact methodologies to ensure enterprise server architectures remain resilient against unpredictable crawler behavior.
Conclusion
Resolving an Infinite Image URL Crawl Trap is a critical infrastructure repair. By enforcing strict parameter allowlists, normalizing edge cache keys, and deploying precise indexing directives, you can reclaim your crawl budget and stabilize your server.
Navigating the intersection of technical SEO, server architecture, and generative search requires a precise roadmap. If you need to future-proof your enterprise stack, resolve deep-level crawl anomalies, or implement AI-driven SEO automation, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is an infinite image URL crawl trap?
An infinite image URL crawl trap occurs when dynamic resizing logic generates a unique and valid URL for every possible permutation of image dimensions or filters. Search engine crawlers attempt to index every variation, leading to exponential server requests and wasted crawl budget.
How do image crawl traps impact SEO and Generative Engine Optimization (GEO)?
These traps destroy organic visibility by bogging down crawlers with redundant media files, preventing the discovery of high-value content. Furthermore, the resulting server strain increases Time to First Byte (TTFB), which negatively impacts Core Web Vitals and signals architectural instability to AI-driven search engines.
How can I identify a crawl trap using Google Search Console?
In Google Search Console, navigate to the Crawl Stats report. A crawl trap manifests as a massive spike in ‘Image’ file types, often accompanied by a sharp increase in average response time and total download time. Server logs will confirm this with thousands of 200 OK requests for URLs with non-standard query parameters.
What is the best way to block crawlers from indexing image variations?
The most effective strategy is a multi-layered approach: use robots.txt directives (e.g., Disallow: /*?*w=) to signal crawlers to stop, and implement server-level X-Robots-Tag: noindex headers for any request containing image query parameters to prevent indexing of non-canonical assets.
How does server-side dimension allowlisting prevent CPU exhaustion?
By modifying server logic (such as NGINX or PHP) to only process image requests that match a strict list of registered dimensions, you can immediately reject unauthorized requests with a 403 Forbidden status. This prevents the server from wasting CPU cycles on real-time binary generation for arbitrary parameters.
Should I use a CDN to mitigate image crawl traps?
Yes, modern CDNs can mitigate traps through edge-side cache key normalization. By configuring the CDN to ‘Ignore Query String’ for image extensions, the edge serves a single cached version to all crawlers, preventing redundant requests from hitting and overwhelming the origin server.