Executive Summary
- Re-ranking is a secondary retrieval stage that uses computationally intensive models to refine the order of initial search results for maximum precision.
- In RAG (Retrieval-Augmented Generation) pipelines, re-ranking ensures the most relevant context is fed into the LLM, directly impacting source attribution.
- Effective GEO strategies must account for re-ranking algorithms to maintain visibility in the final generative output of AI search engines.
What is Re-Ranking?
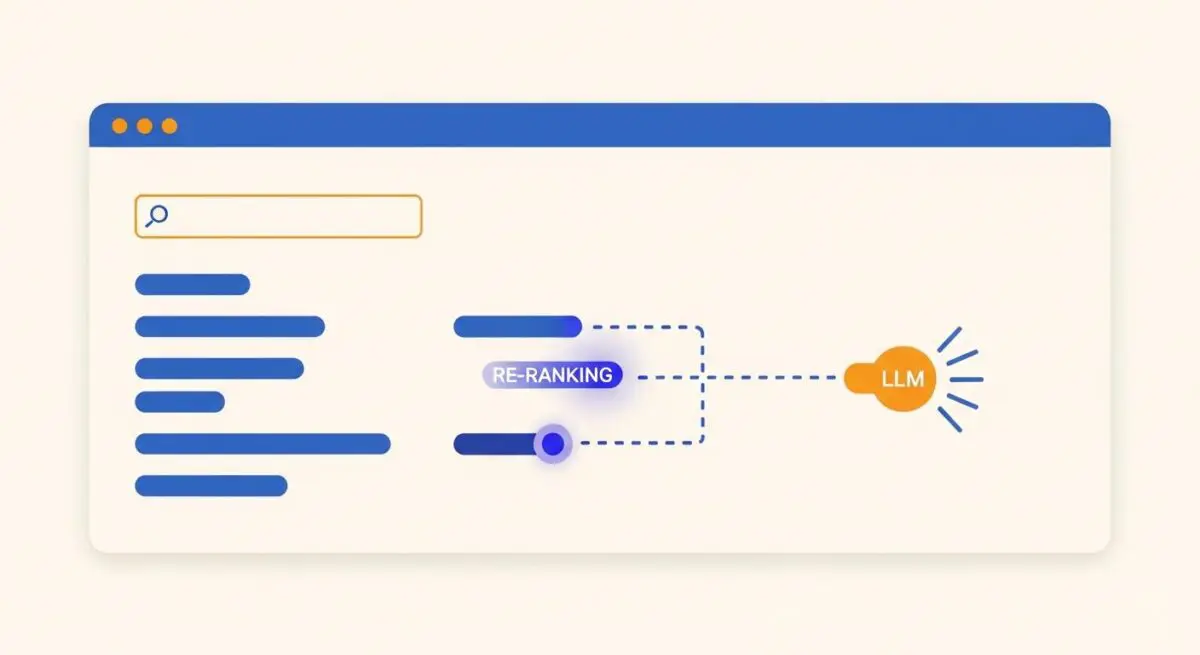
Re-ranking is a critical process in modern Information Retrieval (IR) and AI-driven search architectures, functioning as the second stage of a two-step retrieval pipeline. While the initial retrieval phase (often utilizing Bi-Encoders or BM25) quickly identifies a broad set of potentially relevant documents from a massive index, it often lacks the granular precision required for high-stakes generative responses. Re-ranking takes this subset—typically the top 50 to 100 results—and applies a more sophisticated, computationally expensive model to evaluate the specific relevance of each document against the user’s query.
Technically, re-rankers often employ Cross-Encoders, which process the query and the document simultaneously to capture deep semantic interactions. This allows the system to identify nuances, context, and intent that first-stage retrieval might miss. In the context of Generative Engine Optimization (GEO), re-ranking is the gatekeeper that determines which specific pieces of information are prioritized for the Large Language Model (LLM) to synthesize into a final answer.
The Real-World Analogy
Imagine you are at a massive, multi-story library looking for a specific solution to a complex legal problem. A library assistant (the retriever) quickly runs through the aisles and grabs 50 books that mention your keywords. However, the assistant hasn’t read the books; they just found the titles. You then hand those 50 books to a senior partner at a law firm (the re-ranker). The partner carefully reads the specific paragraphs in those 50 books and re-orders them, placing the 3 most authoritative and legally sound books at the very top of the stack. The partner ensures that the most relevant information is what you see first, even if the assistant’s initial search was broad.
Why is Re-Ranking Important for GEO and LLMs?
For GEO and LLM visibility, re-ranking is the stage where “authority” and “relevance” are strictly enforced. Most AI search engines, such as Perplexity or ChatGPT with Search, utilize Retrieval-Augmented Generation (RAG). Because LLMs have a finite context window and are prone to the “lost in the middle” effect—where they prioritize information at the beginning and end of a prompt—the order of retrieved documents is paramount. If your content is retrieved but ranked 20th, it may be excluded from the prompt sent to the LLM entirely.
Re-ranking directly influences source attribution. If a re-ranking model identifies your content as the most semantically aligned with the user’s intent, it will be placed in the primary position. This increases the probability of the LLM citing your brand as the definitive source, thereby driving traffic and establishing entity authority within the AI’s knowledge graph.
Best Practices & Implementation
- Enhance Semantic Density: Ensure that your content directly addresses specific user intents with high information density, making it easier for Cross-Encoders to score your text as highly relevant.
- Optimize for Entity Clarity: Use clear, unambiguous language and structured data (Schema.org) to define the relationships between entities, helping re-rankers understand the context of your information.
- Focus on Document Structure: Use descriptive headings and concise paragraphs. Re-rankers often evaluate chunks of text; well-structured content ensures that the most relevant “chunk” is easily identifiable.
- Maintain High Factual Accuracy: AI search engines often incorporate fact-checking or consensus-based re-ranking layers; ensuring your data aligns with established facts improves your re-ranking potential.
Common Mistakes to Avoid
A frequent error is over-optimizing for first-stage retrieval (keyword density) while neglecting the semantic depth required for the re-ranking stage. If content is “thin,” it may be retrieved but will be discarded during re-ranking. Another mistake is failing to provide clear answers to complex queries; if the re-ranker cannot find a direct semantic match for the user’s question within your text, your ranking will suffer regardless of your domain authority.
Conclusion
Re-ranking is the bridge between broad data retrieval and precise generative output. Mastering this stage is essential for any GEO strategy aiming to secure top-tier visibility and attribution in AI-driven search environments.