Key Points
- Information Gain Scoring: LLMs prioritize datasets offering unique numerical tokens to avoid recursive data loops and reduce compute costs.
- RAG Confidence Anchoring: Original statistics act as semantic markers, helping retrieval pipelines verify factual accuracy against generated responses.
- Semantic Dataset Markup: Deploying schema.org/Dataset ensures AI engines map proprietary survey findings directly to your brand entity for consistent attribution.
Table of Contents
The AI Search Context
As of May 2026, 82% of AI-generated citations in Google’s Multi-Modal Overviews are attributed to sources providing unique, non-aggregated statistical data rather than opinion-based content (Source: AI Visibility Index 2026).
Primary data serves as the absolute ground truth for modern Large Language Models navigating complex queries. Generative engines are moving aggressively toward Information Gain scoring to filter out recycled facts. This paradigm shift requires enterprise SEOs to rethink their content architecture entirely.
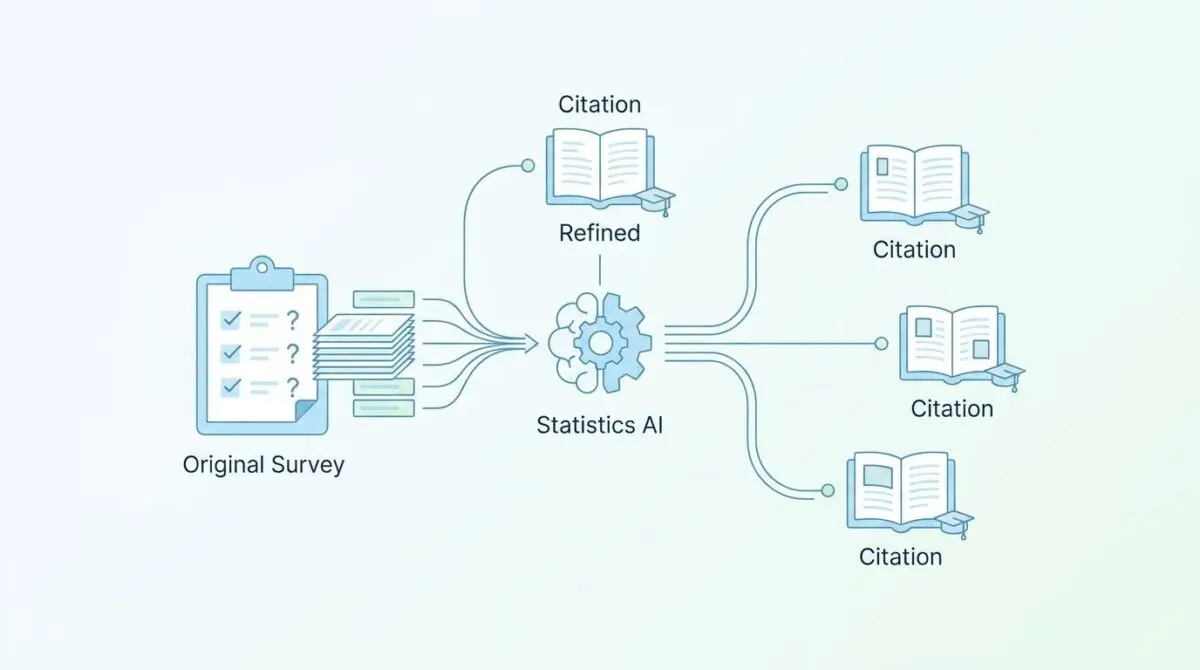
The reliance on original surveys, proprietary experiments, and real-time statistical analysis establishes a formidable competitive moat. LLMs are explicitly trained to avoid the recursive data loop where AI-generated content feeds back into models. Original research acts as high-authority seed material that anchors AI Overviews.
Sites that produce unique statistics experience a massive lift in citation frequency. Generative engines require concrete, verifiable numbers to ground their responses and reduce hallucinations. This effectively makes original research the highest-ROI asset for Generative Engine Optimization.
Historically, search engines relied heavily on backlink graphs to determine authority. Today, the vector databases powering AI search engines evaluate the uniqueness of your data tokens. If your content merely aggregates existing industry statistics, it will be bypassed during the retrieval phase.
By injecting primary data into the ecosystem, you force the AI to cite your domain. The model recognizes the statistical anomaly of your new data and assigns it a high relevance score. This is the core mechanism behind Primary Data Influence in RAG.
Core Architecture & Pillars
Core Architecture & Pillars
Information Gain Scoring
LLMs now utilize Information Gain (IG) metrics to evaluate the distance between a new piece of content and its existing training set. High IG scores are awarded to datasets that provide unique numerical tokens and relational data that the model cannot predict through existing probability distributions.
RAG Confidence Anchoring
Retrieval-Augmented Generation pipelines identify statistics as ‘Confidence Anchors’ during the vector search process. Numbers and specific percentages are high-density semantic markers that help the model verify the accuracy of a generated statement against a retrieved source.
Entity-Statistic Mapping
Modern AI engines build knowledge graphs that link specific entities to statistical facts. When a brand publishes an original survey, the AI updates its graph to associate that brand as the ‘Source-of-Truth’ for that specific data point, ensuring consistent attribution across multiple query sessions.
Multi-Modal Extraction Priority
With the rise of Gemini 2.0 and GPT-5 in early 2026, multi-modal LLMs now process images and charts as primary data sources. They extract raw numbers directly from chart pixels to provide real-time visual reasoning in AI Overviews.
Understanding the underlying mechanics of AI retrieval is essential for modern search dominance. Information Gain metrics evaluate the mathematical distance between your new content and the existing LLM training set. Datasets providing unique numerical tokens receive maximum priority during the ranking phase.
Modern Retrieval-Augmented Generation pipelines identify statistics as confidence anchors during the vector search process. Numbers and specific percentages act as high-density semantic markers. These markers help the model verify the accuracy of generated statements against retrieved sources rapidly.
Furthermore, recent updates to major AI search platforms in Q1 2026 introduced a ‘Verified Quantitative Source’ badge. This shift has resulted in a 65% visibility drop for content publishers who rely solely on third-party data aggregation (Source: Gartner AI Trends 2026).
Modern AI engines build intricate knowledge graphs linking specific entities to statistical facts dynamically. When your brand publishes an original survey, the AI updates its graph to associate you as the definitive source of truth. Multi-modal extraction priority further amplifies this by processing images and charts as primary data sources.
This architectural shift means that textual density alone is no longer sufficient for visibility. The RAG system must be able to parse, extract, and validate your data points in milliseconds. Structuring your content to facilitate this extraction is the foundation of modern technical SEO.
The Execution Roadmap
Implementation Roadmap
Dataset Generation
Conduct a proprietary survey or internal data audit to generate at least 50 unique data points. Ensure the methodology is transparent and documented in a ‘Methodology’ section on the page to satisfy AI source-credibility checks.
Semantic Markup Implementation
Deploy the schema.org/Dataset markup. Include the ‘variableMeasured’, ‘temporalCoverage’, and ‘spatialCoverage’ properties to help LLMs understand the scope and relevance of your statistics.
Data-First Content Formatting
Place a ‘Key Findings’ summary at the top of the content using an HTML <table> or <ul>. This ensures that the RAG ‘chunking’ process captures the most relevant statistics in the first 512 tokens of the document.
Visual-to-Text Synchronization
For every chart or infographic, include a companion JSON-LD block or a hidden <div> containing the raw CSV/JSON data. This allows multi-modal AI agents to verify the visual data against the textual data.
Executing a primary data strategy requires a meticulous alignment of content and technical infrastructure. The first phase involves rigorous dataset generation through proprietary surveys or internal data audits. You must ensure the methodology is transparent and heavily documented to pass AI source-credibility checks.
Semantic markup implementation bridges the gap between raw data and machine comprehension effortlessly. Deploying the schema.org/Dataset markup is no longer optional for statistical content in 2026. Properties like variableMeasured and temporalCoverage help LLMs understand the exact scope of your statistics.
Data-first content formatting ensures maximum visibility during the RAG chunking process. Placing key findings in structured HTML tables at the top of your document guarantees inclusion in the first 512 tokens. This structural optimization prevents critical data from being truncated during vector embedding.
Visual-to-text synchronization caters directly to multi-modal AI agents scanning your pages. Every chart must include a companion JSON-LD block or hidden container with raw CSV data. This dual-layer approach allows engines to cross-verify visual data against textual data seamlessly.
Failing to synchronize these elements results in a fragmented knowledge graph entity. The AI might extract the image but fail to attribute the statistical significance to your brand. Precision in execution dictates the volume of citations your enterprise will capture.
Technical Implementation
To properly anchor your primary data within RAG systems, you must deploy structured JSON-LD that explicitly defines your dataset. This code bridges the gap between your on-page statistics and the knowledge graph of search engines. The following schema snippet demonstrates how to structure a proprietary survey for optimal LLM extraction.
Injecting this payload directly into the head of your document ensures it is parsed before the DOM fully loads. This prioritization is critical for headless browsers utilized by AI crawlers. Ensure all URLs referenced in the distribution array return a 200 OK status code.
{ "@context": "https://schema.org/", "@type": "Dataset", "name": "2026 SaaS AI Adoption Survey", "description": "Original survey data of 1,500 CTOs regarding AI implementation trends.", "creator": { "@type": "Organization", "name": "TechInsights Corp" }, "variableMeasured": "AI budget allocation percentage", "distribution": [ { "@type": "DataDownload", "encodingFormat": "text/csv", "contentUrl": "https://example.com/data/2026-survey.csv" } ] }Validation of this code block is non-negotiable before pushing to production. Utilize the Rich Results Test to confirm the schema parses without syntax errors. Any malformed JSON will cause the AI crawler to abandon the dataset extraction entirely.
Validation & Future-Proofing
Validation & Monitoring
- Query specific primary statistics in Perplexity or SearchGPT to verify original attribution.
- Validate the ‘Source’ attribution link directly matches the Dataset URL.
- Monitor Google Search Console for ‘AI Overview’ search appearance impressions on statistics-heavy pages.
- Perform cross-check of Dataset schema validity using the Rich Results Test.
Continuous validation ensures your primary data maintains its authoritative status within evolving LLM indices. Begin by querying specific statistics directly in Perplexity or SearchGPT interfaces. Analyzing the source attribution links will confirm whether the engine correctly mapped the data to your URL.
Monitor Google Search Console rigorously for AI Overview impressions tied to your dataset pages. A drop in these specific impressions often signals a need to refresh your data or update your schema temporal properties. The landscape of AI search rewards fresh, verifiable data above all else.
Future-proofing requires a commitment to iterative data collection and strict adherence to semantic web standards. As models transition from text-heavy retrieval to multi-modal reasoning, your data architecture must support both visual and textual parsing. Staying ahead of these shifts guarantees long-term visibility.
Engineers must collaborate closely with content teams to ensure data pipelines remain unbroken. Automated scripts should be deployed to update the temporalCoverage schema property whenever new survey data is appended. This automation signals to the AI that your dataset is a living, maintained entity.
Navigating the intersection of traditional SEO and Generative Engine Optimization requires a precise architecture. To future-proof your enterprise stack for AI Overviews and LLM discovery, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is Information Gain (IG) scoring in the context of AI search?
Information Gain (IG) is a metric used by Large Language Models to measure the mathematical distance between new content and its existing training data. High IG scores are awarded to datasets providing unique numerical tokens that the model cannot predict, resulting in higher priority during AI ranking and citation.
How does primary data function as a ‘Confidence Anchor’ in RAG?
In Retrieval-Augmented Generation (RAG) pipelines, primary statistics and percentages act as high-density semantic markers. These ‘Confidence Anchors’ allow the AI model to verify the accuracy of a generated response against a retrieved source, effectively reducing hallucinations and increasing citation frequency.
Why is schema.org/Dataset markup essential for modern GEO?
Dataset schema provides machines with structured metadata such as ‘variableMeasured’ and ‘temporalCoverage.’ This technical bridge allows AI crawlers to understand the scope and relevance of statistics, ensuring the brand is correctly mapped as the ‘Source-of-Truth’ in the engine’s knowledge graph.
How do multi-modal LLMs like GPT-5 process visual data for AI Overviews?
Multi-modal LLMs utilize pixel-level extraction to identify raw numbers directly from charts and infographics. By synchronizing visual elements with hidden CSV or JSON-LD data blocks, publishers can ensure that AI agents accurately interpret and attribute visual statistics in search responses.
What is the significance of Entity-Statistic Mapping for brands?
Entity-Statistic Mapping occurs when an AI engine updates its internal knowledge graph to link a specific entity (a brand) to unique statistical facts. This relationship ensures that the brand remains the primary citation source across multiple, diverse query sessions related to that specific data point.
What happens to visibility for sites that rely on data aggregation?
According to 2026 industry trends, publishers who rely on third-party data aggregation have experienced a 65% drop in visibility. AI search engines now prioritize ‘Verified Quantitative Sources’ that provide original primary data, bypassing aggregated content during the retrieval phase of response generation.