Key Points
- Dynamic Sitemap Resource Contention: Mitigate database locking and CPU saturation by transitioning from dynamic SQL generation to static XML delivery.
- PHP-FPM Optimization: Reconfigure worker pools from dynamic to static process management to eliminate spawning latency during aggressive Googlebot fetch spikes.
- Edge Caching Architecture: Deploy Cloudflare Workers or NGINX FastCGI caching to bypass the origin server, ensuring high-frequency crawler requests never hit backend resources.
Table of Contents
The Core Conflict: Hostload Exceeded and Crawl Demand
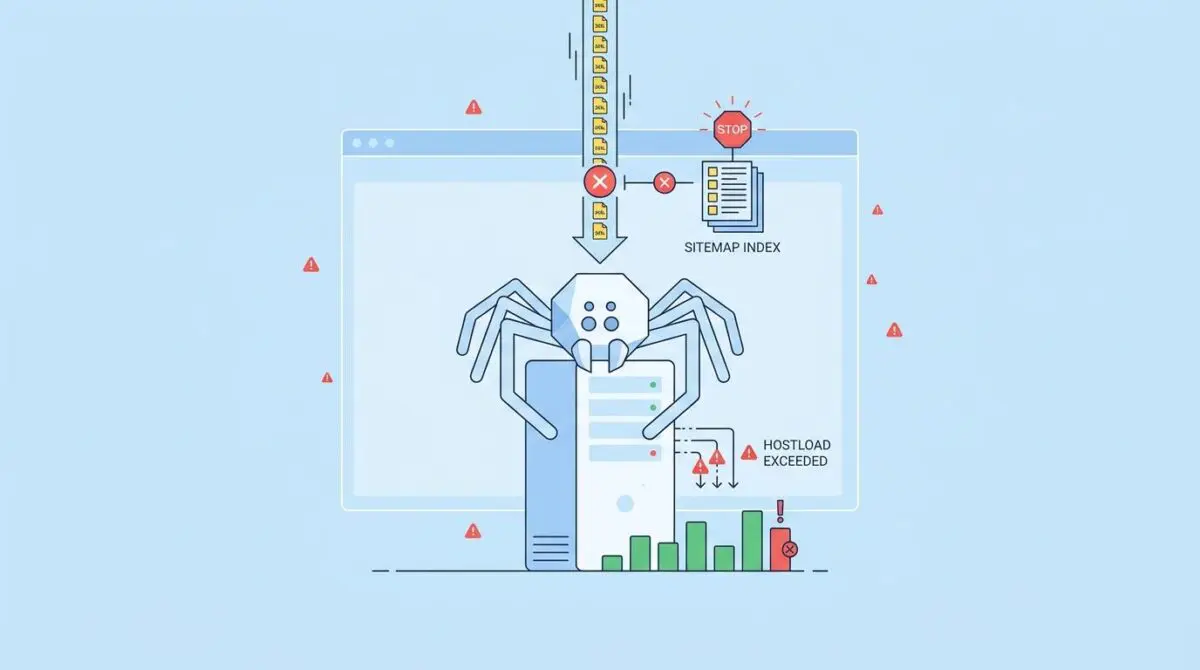
According to the HTTP Archive’s 2025 Web Almanac, websites utilizing dynamic sitemap generation without edge caching experience a 42% higher frequency of hostload-related crawl failures compared to those using static XML distribution. This statistic highlights a critical vulnerability in modern server architecture. When you encounter hostload exceeded errors preventing Googlebot from fetching the sitemap index file during scheduled crawls, your server is fundamentally failing to meet the required crawl demand.
In the modern SEO landscape, Gemini-driven Generative Engine Optimization requires frequent, deep crawling of structured data. A hostload exceeded error indicates Googlebot has reached the maximum limit of requests your server can handle without degrading performance.
This immediately halts the discovery of new URLs, effectively freezing your site’s presence in search results. Generative models rely heavily on the most recent content snapshots to formulate answers.
Technically, this calculation is based on server response time latency and error rates like 5xx or 429 status codes. Googlebot utilizes sophisticated algorithms to dynamically adjust its crawl rate based on the responsiveness of your host.
If the sitemap index is unreachable, the freshness score of the domain collapses entirely. This leads to a rapid decline in crawl budget, as Google’s scheduling algorithms deprioritize fragile hosts that demonstrate an inability to maintain stable connections under load.
When the hostload limit is breached, it is not merely a temporary hiccup. Google’s systems register this as a persistent infrastructure failure, extending the time between subsequent crawl attempts.
This delay can prove fatal for news publishers or e-commerce platforms that rely on rapid indexation of new inventory. Understanding the mechanics of crawl capacity is the first step in resolving these critical infrastructure bottlenecks.
Diagnostic Checkpoints: Identifying the Bottleneck
Diagnostic Checkpoints
Dynamic Sitemap Resource Contention
High-complexity SQL queries during concurrent Googlebot fetch spikes.
WAF and Rate Limiting Misconfiguration
Security firewalls blocking crawler IPs without proper whitelisting.
Synchronous WP-Cron Execution Overlap
Resource-heavy background tasks competing with real-time crawler requests.
Inadequate PHP-FPM Process Management
Insufficient PHP workers to handle simultaneous sitemap child requests.
When diagnosing a hostload exceeded event, you must understand that this error is typically a desynchronization in your technology stack. The symptoms are glaringly visible in Google Search Console. The crawl stats report will show a massive spike in hostload under the crawl status breakdown.
Simultaneously, the sitemap report will display a could not fetch status for the index file. Server logs will confirm this, showing an influx of Googlebot IP addresses receiving HTTP 429 or HTTP 503 status codes during the exact timestamp of the sitemap fetch attempt. These logs are your primary source of truth when debugging crawl capacity issues.
The root cause often lies in dynamic sitemap generation, where PHP and MySQL must compile thousands of URLs on the fly. When concurrent requests hit an unoptimized stack, they saturate the PHP-FPM pool and CPU. This triggers a thundering herd problem that forces the host to signal incapacity.
Database queries executing during these spikes often lack proper indexing for timestamp fields. This leads to full table scans in MySQL, locking the database and causing all subsequent PHP processes to hang indefinitely. As the queue fills up, the web server has no choice but to return 503 Service Unavailable errors to Googlebot.
Alternatively, aggressive web application firewall settings can misinterpret high-frequency Googlebot crawling as a Layer 7 DDoS attack. If the firewall triggers a rate-limit based on request frequency per IP without whitelisting the Googlebot IP ranges, legitimate requests are dropped. To effectively troubleshoot search engine crawling errors, you must isolate which layer of the stack is bottlenecking the request.
Another common culprit is synchronous WP-Cron execution overlap. The default WordPress cron system executes tasks during page loads, meaning a scheduled crawl hitting the sitemap index at the exact same time as a heavy backup task will exceed the server’s threshold. High-traffic sites that have not transitioned to a system-level cron job frequently experience this during scheduled maintenance windows.
Engineering Resolution Roadmap
Engineering Resolution Roadmap
Implement Static Sitemap Caching
Offload the generation process from the request cycle. Configure your SEO plugin to generate static XML files or use a server-side cache like NGINX FastCGI Cache to serve the sitemap index. Ensure the ‘X-Accel-Expires’ or ‘Cache-Control’ headers allow for at least 1 hour of caching.
Optimize PHP-FPM Pool Limits
Analyze your server’s RAM and adjust the php-fpm.conf file. Increase ‘pm.max_children’ based on the formula: (Total RAM – RAM for other processes) / average PHP process size. Switch from ‘pm dynamic’ to ‘pm static’ on dedicated instances to eliminate process spawning latency.
Offload Sitemaps to the Edge
Use Cloudflare Workers or similar Edge functions to serve the sitemap index directly from the CDN. This prevents Googlebot’s requests from ever hitting your origin server, effectively bypassing hostload limits for discovery files.
Configure System-Level Cron
Disable the default WP-Cron by adding ‘define(‘DISABLE_WP_CRON’, true);’ to wp-config.php. Create a Linux crontab entry to run ‘php /path/to/wp-cron.php’ every 5-15 minutes, ensuring maintenance tasks don’t compete with Googlebot for web server resources.
Resolving this crawl capacity error requires moving the computational heavy lifting away from the initial request cycle. You cannot rely on real-time database queries to serve discovery files to aggressive crawler bots. Dynamic generation is simply too resource-intensive for large-scale enterprise websites.
The most effective strategy is to implement static sitemap caching. By generating static XML files or utilizing a server-side cache like NGINX FastCGI Cache, you eliminate the database latency entirely. Ensuring your headers allow for at least one hour of caching will drastically reduce the server load during crawl spikes.
Furthermore, you must optimize your PHP-FPM pool limits to handle high concurrency. If your server runs out of available workers, the request queue will time out, resulting in immediate 5xx errors. Analyzing your server’s RAM and adjusting the max children directive ensures you have enough workers to handle the burst of requests that Googlebot makes when fetching an index and its child sitemaps.
Switching from dynamic process management to static process management on dedicated instances is also highly recommended. This eliminates process spawning latency, ensuring workers are always ready to handle incoming crawler requests. When process managers are set to dynamic, the server wastes CPU cycles spinning up new workers during a crawl spike.
Finally, transitioning to a system-level Linux cron job ensures background maintenance tasks never compete with Googlebot for critical web server resources. By executing cron tasks directly via the PHP command line interface, you bypass the web server entirely. This isolates heavy computational tasks from the HTTP request pool serving your sitemaps.
Resolution Execution: Server and Code Implementations
Fixing via NGINX and WordPress
To execute this fix in a WordPress environment, you must force your SEO plugin to cache the sitemap and configure your web server to serve that cache efficiently. If you use plugins like RankMath, you can enable sitemap caching via a simple filter hook. This offloads the generation process from the request cycle.
Additionally, configuring NGINX to bypass PHP entirely for XML files is the gold standard for performance. By adding specific cache-control headers and proxy cache validation, you can serve the sitemap directly from memory. This prevents Googlebot’s requests from ever hitting your origin server’s PHP workers.
When writing the NGINX configuration, disabling access logs for sitemap files can also marginally reduce disk I/O during massive crawl events. You must ensure the expires directive is set properly to instruct edge nodes to hold the file. It is also highly recommended to use CDNs to improve SEO on the edge, further reducing the burden on your origin server.
Cloudflare Workers or similar edge functions can serve the sitemap index directly from the CDN network. By intercepting the request at the edge, the origin server remains completely unaware of the crawl activity. This is the ultimate defense against hostload exceeded errors.
add_filter( 'rank_math/sitemap/enable_caching', '__return_true' );
// NGINX bypass example for sitemap caching
location ~* \.(xml|gz)$ {
access_log off;
log_not_found off;
expires 1h;
add_header Cache-Control "public, no-transform";
proxy_cache_valid 200 60m;
try_files $uri $uri/ /index.php?$args;
}Validation Protocol and Edge Cases
Validation Protocol
- Perform GSC Live Test on Sitemap Index to verify hostload warnings are cleared.
- Execute curl command to verify X-Cache HIT and response times below 200ms.
- Monitor GSC Crawl Stats report for 48 hours to confirm zero Hostload error rate.
After deploying the server configurations, immediate validation is critical to restore your crawl budget. Navigate to Google Search Console and utilize the Live Test feature on your Sitemap Index URL. It should return a clean status indicating the URL is available to Google with zero hostload warnings.
You must also verify the cache headers via the command line. Executing a cURL request should reveal a cache hit and a total response time under 200ms. Keep a close eye on the crawl stats report over the next 48 hours to confirm the error percentage has flatlined.
When using cURL, look specifically for the cache header returning a hit status. If it returns a miss or bypass, your NGINX configuration is not properly intercepting the request. This requires immediate debugging of your FastCGI cache keys and proxy pass parameters.
However, edge cases exist, particularly in headless WordPress architectures. If a frontend framework fetches the sitemap from a private backend API, the backend might hit a load limit while the frontend serves a cached index with broken internal links. This scenario makes debugging exceptionally difficult.
In these headless setups, Googlebot hits the hostload limit on the backend API rather than the public-facing sitemap URL. Resolving this requires cross-layer log correlation to identify the true bottleneck. You must ensure the backend API is properly cached and rate-limited independently of the frontend deployment.
Another edge case involves Varnish cache holding stale sitemaps that point to deleted child XML files. When Googlebot attempts to follow these stale links, it encounters a chain of 404 errors, which can artificially inflate your error rate and trigger a hostload warning. Implementing programmatic cache purging for Varnish is essential when sitemap structures change.
Autonomous Monitoring and Prevention
To prevent a recurrence of hostload exceeded errors, you must implement real-time log monitoring. Utilizing the ELK stack or Grafana Loki allows you to trigger alerts the moment HTTP 429 or HTTP 503 errors exceed a critical threshold. Proactive monitoring is the only way to catch crawl capacity issues before they impact indexation.
Relying solely on Google Search Console for error reporting is too slow for enterprise environments. The data is often delayed by several days, leaving your site vulnerable to prolonged crawl outages. Automated weekly audits using log file analyzers should be standard practice to identify capacity bottlenecks early.
By piping your NGINX access logs into a centralized dashboard, you can visualize Googlebot’s crawl behavior in real time. Setting up anomaly detection algorithms will notify your engineering team the moment crawl latency spikes above acceptable thresholds. This allows for immediate intervention before crawl budget is permanently damaged.
At Andres SEO Expert, we architect advanced automation pipelines that monitor entity integrity and server health autonomously. By integrating custom API alerts, we ensure that your server architecture remains resilient, scalable, and perfectly aligned with the demands of modern search engines.
Conclusion
Resolving hostload anomalies is not just about increasing server resources. It is about intelligent request routing, strict resource management, and eliminating unnecessary database queries during crawl spikes. By caching sitemaps at the edge and tuning your PHP workers, you secure your domain’s discoverability.
Navigating the intersection of technical SEO, server architecture, and generative search requires a precise roadmap. If you need to future-proof your enterprise stack, resolve deep-level crawl anomalies, or implement AI-driven SEO automation, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What does “Hostload Exceeded” mean in Google Search Console?
A hostload exceeded error indicates that Googlebot has reached the maximum limit of requests your server can handle without degrading performance. This happens when server response times increase or the server returns error codes like 429 or 503, causing Google to deprioritize your host to prevent a crash.
How does crawl capacity affect Generative Engine Optimization (GEO)?
Generative Engine Optimization (GEO) relies on frequent, deep crawling of the latest content. If hostload errors prevent sitemap discovery, your domain’s freshness score collapses, and AI models like Gemini are unable to access the most recent data to formulate search answers.
Why are dynamic sitemaps a primary cause of crawl failures?
Dynamic sitemaps require PHP and MySQL to compile thousands of URLs in real-time. During Googlebot crawl spikes, this can lead to high-complexity SQL queries that saturate the CPU and lock the database, resulting in a “thundering herd” problem that triggers 5xx status codes.
How can I calculate the optimal PHP-FPM pool limits for my server?
To prevent crawl errors, adjust the ‘pm.max_children’ directive in your php-fpm.conf using the formula: (Total RAM minus RAM for other system processes) divided by the average size of a PHP process. Switching to ‘pm static’ on dedicated instances can also eliminate process spawning latency.
Can a Web Application Firewall (WAF) trigger hostload warnings?
Yes, if a WAF is misconfigured to treat high-frequency Googlebot crawling as a Layer 7 DDoS attack. Without proper IP whitelisting, the firewall may rate-limit the crawler, causing 429 status codes that Google interprets as a breach of your server’s hostload capacity.
What is the benefit of serving sitemaps at the Edge?
Serving sitemaps through Edge functions like Cloudflare Workers offloads the discovery process from your origin server. By delivering XML files directly from the CDN network, you achieve sub-200ms response times and ensure Googlebot requests never compete for your server’s PHP and database resources.