Key Points
- Information Gain Deficit: Generative engines penalize redundant content that adds zero novel facts to the retrieval corpus, leading to immediate context window exclusion.
- Algorithmic Entropy: Low variance in sentence structure and predictable token sequences trigger sitewide quality suppression filters in modern AI search.
- Entity Graph Dilution: Hallucination drift and minor factual errors degrade your domain Trust Anchor score within Knowledge Graphs, causing irreversible ranking collapse.
Table of Contents
The AI Search Context
By mid-2026, 85 percent of purely generative content clusters published in 2025 experienced a traffic decay of over 70 percent within six months. This phenomenon is widely recognized among enterprise SEOs as the Rank and Tank pattern. It represents a critical failure point in modern digital publishing and programmatic SEO strategies.
The Rank and Tank pattern occurs when massive clusters of AI-generated content achieve a temporary surge in search visibility. This initial spike is driven entirely by optimized keyword density and superficial semantic relevance. However, it is inevitably followed by a precipitous drop in rankings across all major search interfaces.
Modern generative engines utilize advanced Retrieval-Augmented Generation to process complex user queries. These engines eventually identify unedited, scaled AI content as redundant to their existing training data. Websites relying heavily on programmatic LLM output rapidly face severe Search Silencing.
In this silenced state, your content remains indexed but is systematically excluded from AI Overviews and SearchGPT citations. The cost of cleaning a tanked domain often exceeds the cost of a fresh domain build. Long-term sustainability requires a strategic pivot away from unrefined AI generation toward high-fidelity data injection.
Core Architecture & Pillars
Core Architecture & Pillars
Information Gain Deficit (RAG Value)
Generative engines use a ‘Delta-Analysis’ to determine if a document adds new information to the retrieval corpus. Scaled AI often rehashes existing training data, resulting in a zero or negative Information Gain score. When the retrieval agent finds more authoritative sources for the same facts, the redundant AI content is discarded from the context window.
Algorithmic Entropy and Perplexity Scoring
Search algorithms in 2026 utilize ‘Predictive Perplexity’ to identify synthetic patterns. Scaled AI tends to follow high-probability token sequences, making it highly predictable. Engines like Google now use ‘Burstiness’—the variance in sentence structure—as a proxy for human expertise. Content with low variance is flagged as low-effort synthetic material.
Entity Graph Dilution
AI search relies on ‘Knowledge Graphs’ to verify facts. Scaled AI often introduces ‘hallucination drift’—small factual inaccuracies that compound at scale. When a domain publishes thousands of pages with minor entity-relationship errors, the domain’s ‘Trust Anchor’ score in the Knowledge Graph is downgraded, causing a ranking collapse.
Retrieved Context Volatility
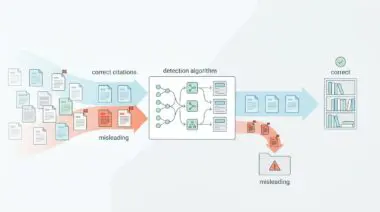
In RAG-driven search, a page’s value is determined by how often it is selected as a ‘Supporting Citation.’ Scaled AI content usually lacks ‘Deep Citations’ (specific, unique data points). Once the AI engine updates its index, it prioritizes sources that are cited by other authoritative LLMs, causing the un-cited AI content to ‘tank’ during the next index refresh.
The foundation of Generative Engine Optimization requires a deep understanding of how LLMs evaluate semantic novelty. Search algorithms have moved beyond basic keyword matching to advanced Information Gain scoring models. Content that offers no new facts or unique perspectives is aggressively deprioritized in the retrieval phase.
In Q1 2026, SearchGPT introduced the Source Authority Score to combat the flood of synthetic content. This metric explicitly penalizes sites where more than 40 percent of the content shares a cosine similarity score greater than 0.95 with existing training corpora. Such high similarity triggers immediate algorithmic suppression across the entire domain.
When your domain hits this similarity threshold, the retrieval agent assumes your content provides a zero or negative Information Gain score. Your pages are subsequently discarded from the context window during query resolution. This is the exact mechanical trigger that initiates the tanking phase of the pattern.
Furthermore, algorithmic entropy plays a massive role in long-term query survival. Search engines utilize predictive perplexity to identify synthetic patterns across your directory structures. Content with low variance is flagged as low-effort synthetic material and permanently removed from AI Overviews.
Entity graph dilution further accelerates this decay. Scaled AI often introduces hallucination drift, where small factual inaccuracies compound at scale. When a domain publishes thousands of pages with minor entity-relationship errors, its Trust Anchor score in the Knowledge Graph is severely downgraded.
The Execution Roadmap
Implementation Roadmap
Information Gain Audit & Vector Pruning
Analyze the site’s content using a vector similarity tool (like Pinecone or Weaviate). Identify clusters where cosine similarity exceeds 0.92 across multiple pages. Consolidate these pages into a single ‘Power Page’ that includes proprietary data or unique expert commentary to increase the Information Gain score.
Injecting Proprietary ‘Small Data’ Signals
Supplement AI-generated text with non-public data: internal case studies, customer surveys, or specific local insights. Update the content to include ‘Experience-Based Phrases’ (e.g., ‘In our testing…’) and ensure these are wrapped in ‘Evidence’ schema markup to signal human oversight to the crawler.
Implementing ‘Human-in-the-Loop’ (HITL) Validation Schema
Modify the site’s JSON-LD to include the ‘reviewedBy’ and ‘author’ properties pointing to verifiable human experts with LinkedIn or ORCID profiles. This helps the AI engine attribute the content to a trusted entity rather than an anonymous LLM script.
Semantic Refresh and Citation Building
Use a 2026-grade SEO tool like BrightEdge or MarketMuse to identify ‘Content Gaps’ within existing AI articles. Manually rewrite the first 200 words and all headers to break synthetic token patterns. Actively pursue high-authority citations to these refreshed pages to reset their ‘Citation Velocity’ in the RAG index.
Executing a recovery from the Rank and Tank pattern requires a systematic overhaul of your content architecture. The first step involves rigorous vector pruning to eliminate semantic bloat from your database. You must analyze your site using vector similarity tools like Pinecone or Weaviate to identify highly redundant clusters.
Once identified, these bloated clusters should be consolidated into comprehensive, highly authoritative power pages. Injecting proprietary small data signals into these pages is crucial for survival in generative engines. Internal case studies, unique survey data, and non-public metrics force the LLM to recognize your page as a primary source.
Data from a recent BrightEdge Research report confirms that manual intervention in the first 200 words breaks synthetic token patterns effectively. This semantic refresh resets your citation velocity within the RAG index. High-authority citations must then be built directly to these updated pages to validate their new standing.
Implementing Human-in-the-Loop validation is the final strategic layer of the roadmap. You must modify your site architecture to attribute content to verifiable human experts. This prevents the AI engine from classifying your entire domain as an anonymous, unverified LLM script.
Technical Implementation
To solidify your Human-in-the-Loop validation, you must deploy advanced schema markup across your entire domain. This JSON-LD implementation signals direct human oversight to the crawler. It attributes the content to a trusted entity within the Knowledge Graph, bypassing synthetic filters.
Ensure that the author and reviewer properties point to verifiable digital profiles. Links to LinkedIn or ORCID profiles provide the necessary trust anchors for the generative engine. Below is the required schema architecture for strict compliance.
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Advanced GEO Strategies for 2026",
"author": {
"@type": "Person",
"name": "Jane Doe",
"url": "https://www.linkedin.com/in/janedoe-geo-expert/"
},
"reviewedBy": {
"@type": "Person",
"name": "Dr. Alan Smith",
"jobTitle": "Senior AI Architect"
},
"significantLink": "https://www.iso.org/standards/ai-transparency",
"interactivityType": "active",
"commentCount": 45,
"mainEntityOfPage": {
"@type": "WebPage",
"lastReviewed": "2026-05-25T10:00:00Z"
}
}Deploy this exact payload in the head section of your consolidated power pages. The inclusion of the lastReviewed property is particularly critical for RAG optimization. It proves to the retrieval layer that the content is actively maintained and fact-checked by human experts.
Furthermore, the significantLink property should point to authoritative external standards or data sets. This contextualizes your document within a broader, verified semantic web. It reduces the likelihood of hallucination drift by grounding your page in established facts.
Validation & Future-Proofing
Validation & Monitoring
- Monitor the ‘Citation Rate’ in SearchGPT and Google AI Overviews to ensure content is being used as a source in generative results.
- Use tools like ‘Copyleaks 2026’ to verify that human-edited segments remain below ‘High Probability Synthetic’ detection thresholds.
- Track ‘Semantic Stability’ metrics; if a page fluctuates by 10+ positions weekly, it is failing the RAG retrieval layer value test.
Continuous validation is essential to prevent secondary ranking collapses in an evolving AI landscape. You must actively monitor your citation rate in SearchGPT and Google AI Overviews. This metric determines if your content is actually being utilized as a foundational source in generative results.
Semantic stability serves as your early warning system for algorithmic suppression. If a page fluctuates by more than ten positions weekly, it indicates a failure in the RAG retrieval layer test. The engine is testing your content but finding insufficient value to maintain its position in the context window.
Utilize advanced detection tools to verify your human-edited segments. Ensure they remain well below the high probability synthetic detection thresholds. This ongoing maintenance is non-negotiable for securing long-term traffic in the modern search landscape.
Navigating the intersection of traditional SEO and Generative Engine Optimization requires a precise architecture. To future-proof your enterprise stack for AI Overviews and LLM discovery, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is the Rank and Tank pattern in AI search?
The Rank and Tank pattern describes a phenomenon where massive clusters of AI-generated content achieve a temporary surge in visibility followed by a traffic decay of over 70 percent. This occurs because generative engines eventually identify the content as redundant or low-value compared to their core training data.
How does Information Gain affect RAG-driven search results?
Generative engines perform a ‘Delta-Analysis’ to determine if a document provides unique value to the retrieval corpus. If content merely rehashes existing data, it receives a zero or negative Information Gain score and is systematically excluded from the context window used to generate AI Overviews.
What is the Source Authority Score (SAS) introduced in 2026?
The SAS is a metric used by SearchGPT to penalize domains where more than 40 percent of the content shares a cosine similarity score of 0.95 or higher with existing training corpora. Reaching this threshold triggers algorithmic suppression, causing the domain to be ‘silenced’ across AI search interfaces.
How can I prevent my domain from being silenced by AI engines?
To avoid Search Silencing, publishers must pivot toward high-fidelity data injection. This involves supplementing AI text with proprietary ‘small data’ like case studies, ensuring high ‘Burstiness’ in sentence structure, and implementing Human-in-the-Loop validation using verifiable expert schema.
Why is Human-in-the-Loop (HITL) validation critical for GEO?
HITL validation uses advanced JSON-LD schema to attribute content to verifiable human experts via LinkedIn or ORCID profiles. This signals direct human oversight to search crawlers, preventing the domain from being classified as an anonymous LLM script and protecting its Trust Anchor score.
What role does Predictive Perplexity play in AI detection?
Modern search algorithms use Predictive Perplexity to identify the highly predictable token sequences common in synthetic content. Engines use ‘Burstiness’—the variance in sentence structure and length—as a proxy for human expertise; low variance content is flagged as low-effort and deprioritized.