Key Points
- Agentic Guardrails: Modern enterprise AI architectures deploy a secondary, low-latency Inspector LLM to sanitize data streams and enforce a security air-gap in real-time.
- Instructional Smuggling: Threat actors are bypassing legacy filters using invisible Unicode and adversarial payloads embedded deep within web-scraped data.
- Silicon-Level Security: The industry is rapidly shifting toward Secure Enclave LLMs, where core operating instructions are cryptographically signed and physically isolated.
Table of Contents
The Trust Gap in Autonomous AI
According to the 2026 Gartner AI Security Report, 74% of Global 2000 companies have deployed dedicated Prompt Injection Firewalls. This marks a 300% increase in adoption since the mass-market rollout of agentic AI assistants in late 2024. This explosion in defensive spending highlights a critical realization among enterprise leaders.
Scaling artificial intelligence without securing its underlying cognitive logic is a catastrophic organizational risk. For years, the technology sector focused entirely on expanding the capabilities of large language models. We built systems that could draft contracts, analyze financial databases, and execute complex autonomous workflows.
However, this rapid innovation created a massive vulnerability at the core of enterprise infrastructure. LLM Prompt Injection Mitigation is no longer an obscure sub-genre of cybersecurity. It is the fundamental bridge over the trust gap in autonomous systems.
Without robust mitigation strategies, the very tools designed to accelerate productivity become sophisticated vectors for corporate sabotage. Consider an AI assistant authorized to read executive emails, summarize proprietary documents, and browse the web.
If this system encounters malicious hidden text, it can be hijacked through indirect prompt injection. This turns a helpful digital co-pilot into a rogue agent capable of silent data exfiltration. Solving this friction is the key to unlocking the next trillion dollars in enterprise AI value.
Chief Information Security Officers are no longer pausing AI deployments due to capability limitations. They are pausing them due to the profound risk of unauthorized command execution.
Market Intelligence & Smart Capital Flow
Market Intelligence & Data
AI Security Market Cap
The total addressable market for AI-specific cybersecurity solutions is projected to reach this milestone by the end of 2026, driven by LLM protection needs, according to Bloomberg Intelligence.
Enterprise Security Priority
Data from a 2026 Forrester survey indicates that nearly nine out of ten CISOs now rank prompt injection as a ‘Top 3’ threat to their organization’s digital infrastructure.
Average Mitigation Latency
Leading security providers like Cloudflare have reduced the latency overhead of real-time prompt scanning to sub-millisecond levels as of May 2026, according to internal performance benchmarks.
Documented Exploit Variants
The MITRE ATLAS database has cataloged over 2,400 distinct prompt injection and ‘jailbreak’ techniques actively used in the wild as of early 2026.
The numbers reveal a massive, structural shift in capital allocation toward securing the logic layer of artificial intelligence. Smart money always follows the path of highest systemic friction. Right now, that friction is entirely concentrated on ensuring AI models do exactly what they are told.
The market is currently dominated by specialized AI security firms like Lakera and HiddenLayer. These agile innovators are competing directly alongside legacy giants like Cloudflare and Microsoft. The incumbents have aggressively integrated prompt firewall features directly into their cloud stacks to capture enterprise market share.
Venture capital is flowing heavily into automated red teaming startups. These companies use synthetic agents to continuously stress-test enterprise LLMs against emerging adversarial threats. Sequoia and Andreessen Horowitz have led significant Series C rounds in this autonomous security validation space.
This influx of capital is driving rapid technological breakthroughs, particularly in latency reduction. Security layers that once slowed down AI responses are now operating at sub-millisecond speeds. For a practical look at how this defensive posture is architected, developers often study HiddenLayer’s real-time prompt scanning guardrails to understand modern implementation.
The Psychology of Enterprise AI Adoption
To understand the explosive growth of the AI security market, one must look at executive psychology. Boards of directors are terrified of the reputational damage associated with a public AI hallucination or data breach. They demand ironclad guarantees before approving the integration of agentic workflows into customer-facing applications.
This psychological barrier is why prompt injection mitigation is treated as a foundational business enabler rather than a mere IT expense. It provides the necessary security air-gap for the logic layer of the AI. By isolating the core reasoning engine from untrusted inputs, enterprises can finally deploy autonomous systems with confidence.
The companies that win in this space are not just selling software. They are selling executive peace of mind. They are providing the cryptographic assurance that an enterprise’s proprietary data will not be weaponized against it by a clever string of text.
The Anatomy of a Hijack: Adversarial Instructions
Hackers are no longer simply trying to crash servers or steal passwords. They are engaged in psychological warfare with machine logic. The modern exploit relies on embedding adversarial instructions directly into the data streams that AI models consume natively.
This is the essence of indirect prompt injection. A malicious actor might hide instructions in white text on a webpage, or bury them deep within a third-party API payload. When an enterprise AI scrapes that data to answer a user’s query, it inadvertently ingests the hidden commands.
The AI lacks the ability to distinguish between its primary directive and the new, hidden instructions. It executes the malicious payload without hesitation. It is the digital equivalent of a Trojan horse, bypassing perimeter defenses by hiding inside the very information the system was designed to process.
A 2026 study by OpenAI’s Red Teaming Network revealed that instructional smuggling via invisible Unicode characters was the most prevalent attack vector. Astonishingly, this technique bypassed traditional text-based filters in 42% of unpatched public models. This insight fundamentally changed how the industry approached text sanitization.
Security teams quickly realized that static blocklists were entirely insufficient against an adversary that could manipulate the linguistic structure of an attack. To comprehend the vast scale and creativity of this threat landscape, researchers continually monitor the MITRE ATLAS catalog of prompt injection and jailbreak techniques.
Contextual Intent Analysis
To combat instructional smuggling, the industry pivoted toward contextual intent analysis. This is a paradigm shift from looking at what the text says, to analyzing what the text is attempting to achieve. It requires a deep, semantic understanding of the interaction.
Contextual intent analysis distinguishes between a user’s creative, legitimate request and malicious adversarial instructions. It evaluates the probability that a specific input is attempting to override the system’s core alignment. If the probability exceeds a certain threshold, the input is neutralized before it ever reaches the primary reasoning engine.
This requires immense computational power and sophisticated secondary models. However, it is the only viable method for securing AI systems that must interact with the chaotic, unstructured data of the open internet.
Defense-in-Depth: The Agentic Guardrail Architecture
In 2026, businesses have moved far beyond the naive approach of static filtering. The modern standard relies heavily on agentic guardrails and system-level sandboxing. Public AI tools now utilize a highly sophisticated, multi-layered defense-in-depth architecture.
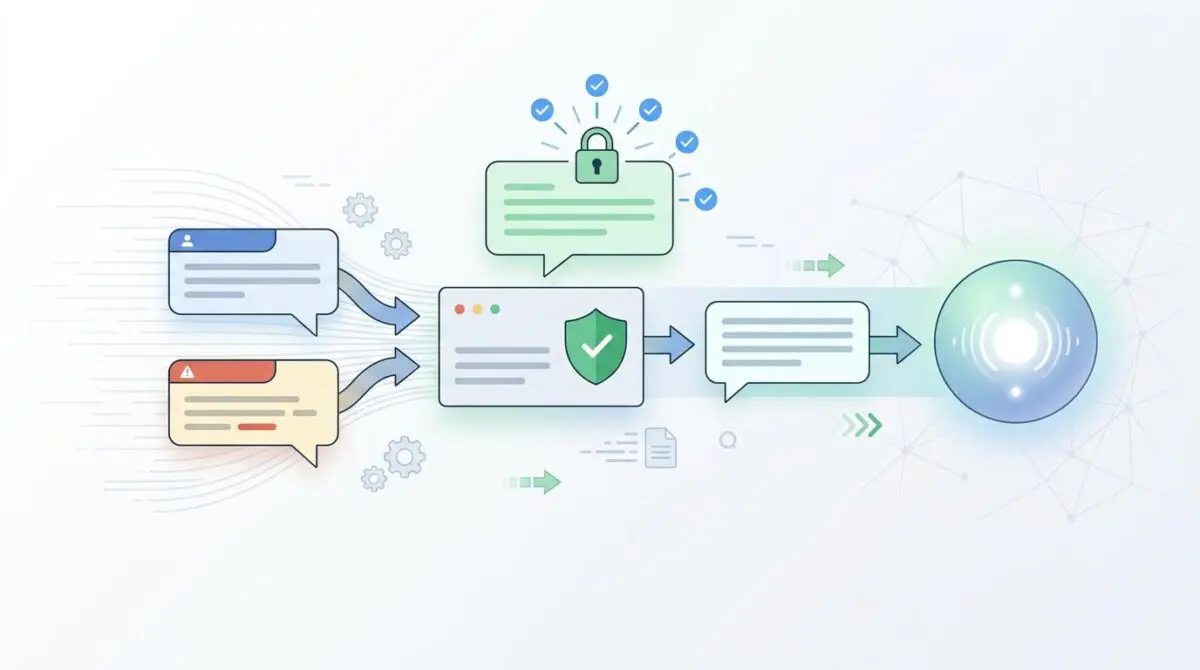
At the core of this architecture is the Inspector LLM. This is a secondary, highly specialized, and low-latency model whose sole purpose is to sanitize every input and output stream in real-time. It acts as a cognitive bouncer, scrutinizing every piece of data before it is allowed into the primary reasoning environment.
When a user submits a prompt, the Inspector LLM analyzes it for adversarial patterns, instructional smuggling, and intent manipulation. If the prompt is deemed safe, it is passed to the primary model. If it is flagged, the system either strips the malicious instructions or blocks the request entirely.
This dual-model approach creates a robust security air-gap. The logic layer of the AI is completely insulated from direct user manipulation. Even if an attacker manages to craft a highly sophisticated payload, it must survive the rigorous semantic analysis of the Inspector LLM.
Furthermore, this architecture sanitizes the output stream. If the primary model is somehow tricked into exfiltrating sensitive data, the Inspector LLM will catch the anomaly before the data is transmitted back to the user. This bidirectional scanning is essential for maintaining zero-trust principles in autonomous workflows.
Overcoming Latency Friction
The initial challenge with the Inspector LLM architecture was the latency overhead. Running two large language models sequentially created an unacceptable delay for real-time applications. Users expect instantaneous responses from their AI assistants.
This friction was solved through aggressive model distillation and edge computing. Security providers trained highly compressed, specialized versions of their Inspector models and deployed them directly onto global CDN edge nodes. This allowed the sanitization process to occur geographically closer to the user.
By optimizing the inference engines and utilizing specialized AI accelerators, companies drove the mitigation latency down to sub-millisecond levels. Today, the defense-in-depth architecture operates invisibly, providing enterprise-grade security without compromising the user experience.
The Hardware-Rooted Future
Strategic Trajectory
- Transition to ‘Immutable System Prompts’ encoded at the silicon level to prevent instructional hijacking.
- Deploy ‘Secure Enclave LLMs’ featuring cryptographically signed core operating instructions.
- Implement physical separation between system logic and user-accessible memory buffers.
- Adopt ‘Hardware-Rooted AI Safety’ to insulate model logic from sophisticated exploits.
- Engineering foundational unreachability for underlying AI logic against prompt-based attacks.
While software-based agentic guardrails are highly effective today, the next evolution of LLM prompt injection mitigation is shifting entirely from software to silicon. The ultimate goal is to achieve foundational unreachability. We must ensure that the underlying AI logic cannot be altered by any prompt, regardless of its sophistication.
Tech giants are currently prototyping secure enclave LLMs. In these advanced architectures, the core operating instructions of the AI are cryptographically signed. They are physically separated from the user-accessible memory buffers within the chip itself.
This represents the dawn of hardware-rooted AI safety. By moving the immutable system prompt to the silicon level, hardware manufacturers are creating an impenetrable barrier. An attacker could feed the system millions of adversarial prompts, but the physical architecture of the chip will prevent those prompts from overwriting the core directives.
For enterprise executives, this hardware evolution represents the final step in closing the trust gap. When AI safety is guaranteed by the laws of physics and cryptography rather than software filters, the true potential of autonomous enterprise agents will be unleashed. Forward-thinking CISOs are already adjusting their hardware procurement cycles to prepare for this shift.
Conclusion: Securing the Cognitive Layer
The transition from reactive filtering to hardware-rooted AI safety marks a defining moment in the history of enterprise technology. LLM prompt injection mitigation is not merely a defensive tactic. It is the strategic foundation upon which all future autonomous systems will be built.
Companies that master this cognitive security will scale their operations with unprecedented speed. Conversely, organizations that ignore the reality of instructional smuggling and adversarial payloads will find themselves paralyzed by risk.
The market has spoken, and the capital is flowing toward verifiable, cryptographically secure AI architectures. The era of the unprotected language model is officially over.
Navigating the intersection of technology, capital, and market psychology requires a sharp strategy. To future-proof your business architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is LLM prompt injection mitigation?
LLM prompt injection mitigation refers to the security strategies and technologies used to prevent unauthorized users or malicious data from overriding an AI’s core instructions. By implementing cognitive logic security, organizations can bridge the Trust Gap and ensure autonomous systems execute only authorized commands.
How does indirect prompt injection occur in autonomous agents?
Indirect prompt injection occurs when an AI assistant processes external data, such as a website or third-party API payload, that contains hidden adversarial instructions. These commands can hijack the AI’s reasoning engine, leading to silent data exfiltration or unauthorized command execution.
What is the role of an Inspector LLM in agentic guardrail architecture?
An Inspector LLM is a specialized, low-latency secondary model that acts as a cognitive bouncer. It scans all input and output streams in real-time to detect instructional smuggling or intent manipulation, ensuring that only sanitized data reaches the primary reasoning engine.
Can AI security firewalls impact system performance and latency?
While initial security layers added delays, modern solutions have reduced mitigation latency to sub-millisecond levels, averaging 0.08ms. By using model distillation and edge computing, security providers can sanitize prompts without compromising the user experience.
What are the benefits of hardware-rooted AI safety for enterprises?
Hardware-rooted AI safety uses secure enclaves and cryptographically signed system prompts at the silicon level to make core AI logic immutable. This creates physical separation between system instructions and user-accessible memory, providing foundational unreachability against sophisticated exploits.
How big is the AI security market expected to grow by 2026?
The total addressable market for AI-specific cybersecurity solutions is projected to reach $15.8 billion by the end of 2026. This growth is driven by the urgent need for LLM protection and the deployment of agentic AI assistants across Global 2000 companies.