Executive Summary
- Anomaly detection utilizes statistical modeling and machine learning to identify data points that deviate significantly from established baseline patterns.
- In autonomous workflows, it serves as a critical validation layer for API responses, preventing malformed JSON payloads from triggering cascading system failures.
- Implementation of robust detection algorithms ensures the integrity of programmatic SEO and AI content operations by monitoring for sudden shifts in data distribution.
What is Anomaly Detection?
Anomaly detection, also known as outlier detection, is the identification of rare items, events, or observations which raise suspicions by differing significantly from the majority of the data. Within the architecture of AI automations and data pipelines, this process involves the application of unsupervised, semi-supervised, or supervised machine learning models to monitor data streams in real-time. Common methodologies include Isolation Forests, Local Outlier Factor (LOF), and Z-score analysis, which are used to establish a mathematical baseline of “normal” behavior.
In the context of high-scale digital operations, anomaly detection acts as a diagnostic layer for time-series data, such as server response times, webhook frequency, and API payload sizes. By analyzing the distribution of data points, these systems can automatically flag deviations that suggest underlying technical debt, security breaches, or integration failures. This ensures that the data driving autonomous agents remains high-fidelity and reliable.
The Real-World Analogy
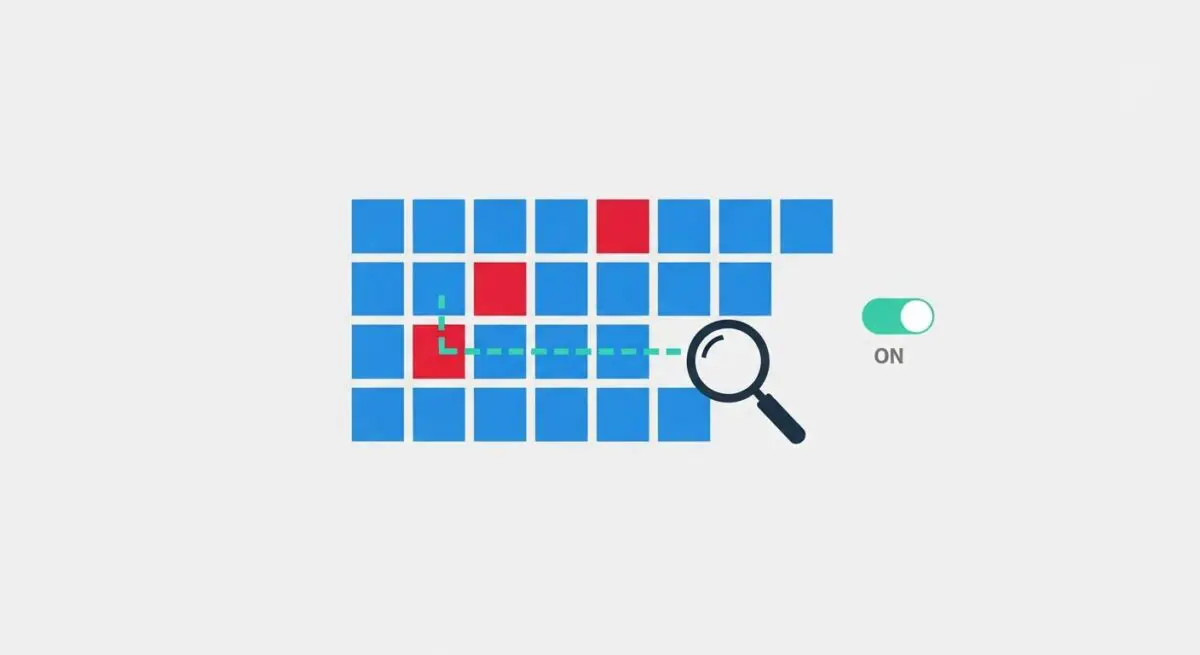
Imagine a high-security bank vault equipped with a sophisticated environmental monitoring system. On a typical day, the system records minor fluctuations in temperature and sound as staff enter and exit. However, if the sensors suddenly detect a 10-degree temperature spike and high-frequency vibrations at 3:00 AM, the system identifies this as an anomaly. It does not need to know exactly what a “drill” is; it only needs to recognize that the current data pattern is fundamentally inconsistent with the established baseline of a quiet, cool night. In automation, anomaly detection is that silent alarm that triggers before a minor data discrepancy becomes a total system collapse.
Why is Anomaly Detection Critical for Autonomous Workflows and AI Content Ops?
For organizations leveraging stateless automation and programmatic SEO, anomaly detection is the primary defense against “silent failures.” In a stateless architecture, each execution is independent; if an upstream API begins returning empty JSON objects or corrupted strings, the automation may continue to execute, wasting compute resources and potentially injecting low-quality or nonsensical content into a production environment. Anomaly detection identifies these malformed payloads at the edge, allowing the system to halt execution or trigger a retry logic before the error propagates.
Furthermore, in AI content operations, anomaly detection monitors the output of Large Language Models (LLMs). If a model’s output suddenly shifts in sentiment, token length, or factual density, the detection system flags the batch for human review. This is essential for maintaining brand integrity and search engine visibility, as it prevents the mass-publication of anomalous content that could trigger algorithmic penalties in Search Generative Experiences (SGE) or traditional search rankings.
Best Practices & Implementation
- Establish Dynamic Baselines: Avoid static thresholds. Use moving averages and seasonal decomposition to account for expected fluctuations in traffic or data volume, reducing false positives.
- Implement Multi-Layered Alerting: Integrate anomaly detection at both the infrastructure level (CPU/RAM usage) and the application level (API response schema validation).
- Utilize Unsupervised Learning: Deploy algorithms like Isolation Forests for high-dimensional data where the specific types of potential failures are not known in advance.
- Validate JSON Payloads at the Edge: Use schema validation tools in conjunction with anomaly detection to ensure that incoming data from webhooks matches expected data types and structures.
- Automate Remediation Protocols: Link anomaly detection triggers to automated circuit breakers that can pause workflows or switch to redundant data sources when an outlier is detected.
Common Mistakes to Avoid
A frequent error is the over-reliance on static thresholds, which fails to account for natural growth or cyclical patterns in data, leading to excessive “alert fatigue.” Another common mistake is ignoring the “cold start” problem, where a detection model is deployed without sufficient historical data to establish a valid baseline, resulting in inaccurate flagging of normal operations. Finally, many teams fail to integrate a feedback loop, where confirmed anomalies are used to retrain the model, improving its precision over time.
Conclusion
Anomaly detection is a foundational requirement for building resilient, self-healing AI automation systems. By proactively identifying data irregularities, engineers can ensure the stability of complex pipelines and the quality of AI-driven outputs.