Key Points
- Semantic Architecture: Utilizing Semantic Structural Mapping (SSM) transforms unstructured text into explicit knowledge graphs for LLM ingestion.
- Fragment Indexing: Proper HTML5 landmarks define vector boundaries, ensuring generative engines isolate the primary content from peripheral noise.
- Intent Signaling: Declarative tags guide Retrieval-Augmented Generation (RAG) systems to understand contextual hierarchies and user actionability.
Table of Contents
The AI Search Context
According to a 2025 BrightEdge study, pages utilizing standard HTML5 semantic landmarks are 42% more likely to be selected as ‘Primary Context’ sources for Google AI Overviews compared to div-heavy layouts.
This dramatic shift underscores a fundamental evolution in how machines read the web. Semantic HTML now serves as the cognitive scaffolding for modern AI crawlers.
It transforms raw text into structured data hierarchies that Large Language Models can digest with high precision. In the era of Generative Engine Optimization, generic containers are a technical liability.
When a site relies on arbitrary tags, AI crawlers struggle to distinguish between the core argument and peripheral noise. This structural ambiguity leads to lower relevance scores in AI Overviews and SearchGPT responses.
By utilizing specific HTML5 landmarks, developers provide explicit signals to Retrieval-Augmented Generation systems. This practice, known as Semantic Structural Mapping (SSM), acts as a roadmap for vector embedding processes.
The impact of semantic HTML on AI visibility is profound, as it directly influences Fragment Indexing. This is a process where AI engines index specific sections of a page rather than the whole URL.
Without explicit structural boundaries, the engine cannot confidently attribute specific claims to the primary content body. Consequently, the content is often discarded during the retrieval phase of generative search.
Mastering SSM ensures that your content is parsed, vectorized, and retrieved with maximum fidelity by the next generation of search agents.
Core Architecture & Pillars
Core Architecture & Pillars
Entity Relationship Parsing
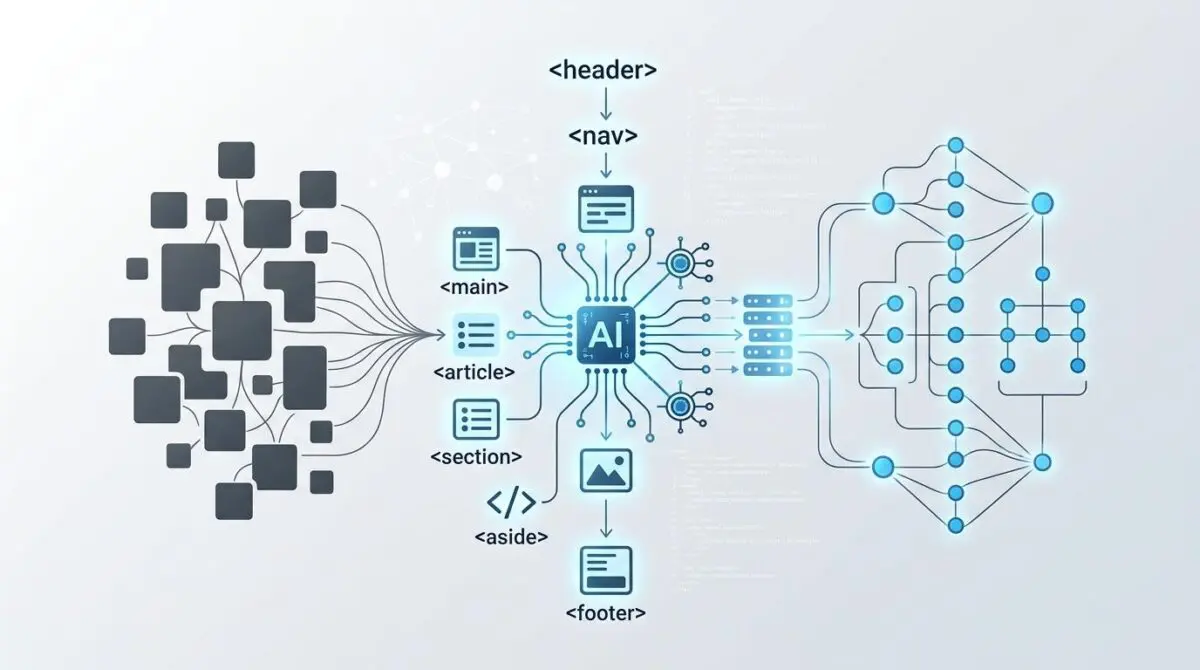
Generative engines use semantic tags to build a localized knowledge graph. Tags like <address> or <time> provide explicit data types that LLMs use to verify facts against their training data, reducing hallucination risks during citation.
Fragmented Vectorization Optimization
AI crawlers segment pages into chunks for vector database storage. Proper use of <section> and <h2-h6> elements defines the boundaries of these chunks, ensuring that related concepts are embedded as a single coherent vector.
Noise Reduction and Signal Boosting
Retrieval systems utilize a signal-to-noise ratio to determine content quality. Semantic elements like <aside> and <footer> are programmatically de-weighted during the ‘extraction phase’ of AI crawling, focusing the engine’s attention on <main>.
Declarative Intent through Landmarks
Landmark roles (e.g., <nav>, <search>) provide intent signals. When an AI agent performs an ‘action-based search,’ it looks for these semantic indicators to understand how a user would interact with the information presented.
Entity Relationship Parsing
Generative engines use semantic tags to build localized knowledge graphs. This process relies heavily on explicit data types to verify facts against underlying training data.
In legacy content management systems, critical information is often wrapped in generic containers. Transitioning to blocks that output specific landmarks allows AI agents to identify entities without relying on heuristic guesses.
This exact precision reduces hallucination risks during citation generation. It directly influences how platforms like Perplexity attribute claims to your specific URL.
By structuring data with semantic precision, you create a verifiable trail for LLMs. This enhances the overall trustworthiness of the document in the eyes of the AI crawler.
Fragmented Vectorization Optimization
AI crawlers segment pages into discrete chunks for vector database storage. The boundaries of these chunks are largely defined by semantic sectioning elements.
Proper use of heading elements ensures that related concepts are embedded as a single coherent vector. This is a critical component of Semantic Structural Mapping.
If you review OpenAI’s OAI-SearchBot crawler documentation, you will notice a strong preference for clear document outlines. Plugin-heavy sites often break this flow with injected scripts, forcing engines to truncate content mid-sentence.
When chunks are truncated prematurely, the semantic relationship between a heading and its subsequent paragraph is severed. This leads to fragmented embeddings that perform poorly in similarity searches.
Noise Reduction and Signal Boosting
Retrieval systems utilize a signal-to-noise ratio to determine content quality during the extraction phase. Semantic elements are programmatically evaluated to weight information density.
OpenAI’s SearchGPT technical briefing from March 2026 revealed that their crawler uses semantic tags like article and main to weight information density, effectively ignoring content wrapped in generic div containers when calculating knowledge graph relevance.
You can see similar trends in BrightEdge’s research on Google AI Overviews regarding content extraction. Wrapping sidebars in aside tags ensures that generative engines do not confuse related links with core educational content.
By isolating the primary signal, you prevent LLMs from diluting your core message with boilerplate text. This programmatic demotion of peripheral elements is essential for maximizing relevance scores.
Declarative Intent through Landmarks
Landmark roles provide explicit intent signals to action-based AI agents. These indicators help the engine understand how a human user would interact with the presented information.
Strategic implementation of navigation and figure tags allows AI engines to categorize queries more effectively. It creates a clear division between navigational pathways and informative substance.
When an AI agent performs an action-based search, it actively seeks these semantic indicators. Proper implementation ensures your site architecture aligns with the engine’s predictive models.
The Execution Roadmap
Implementation Roadmap
Semantic Audit and Wrapper Remediation
Analyze the site’s DOM tree using tools like Chrome DevTools or Screaming Frog. Identify areas where <div> or <span> are used for structural layout. Replace the primary content container with <main> and sub-topics with <section>.
Logical Heading Hierarchy Refinement
Ensure a strict linear heading path (H1 > H2 > H3). Eliminate ‘skipped’ levels (e.g., H2 to H4) which confuse AI fragment boundaries. Every H2 should ideally be the entry point for a new vector chunk.
Metadata-HTML Synchronization
Align semantic HTML tags with JSON-LD Schema. If using <article>, ensure the Schema.org Article ‘articleBody’ property maps exactly to the content within that tag to reinforce data authority.
Peripheral De-optimization
Modify the theme’s footer.php and sidebar.php to use <footer> and <aside> respectively. Apply the ‘aria-label’ attribute to these sections to provide further context to AI agents about their utility.
Semantic Audit and Wrapper Remediation
The first phase of Semantic Structural Mapping requires a comprehensive DOM tree analysis. Engineers must identify areas where generic spans or divs dictate structural layout.
Replacing the primary content container with a main tag establishes the core extraction zone for AI crawlers. Sub-topics should then be encapsulated within section tags to define thematic boundaries.
This remediation removes the guesswork for headless browsers rendering the DOM. It provides a mathematically clean tree structure for the parsing algorithms to traverse.
Logical Heading Hierarchy Refinement
Generative engines rely on a strict linear heading path to construct vector chunks. Eliminating skipped heading levels prevents AI fragment boundary confusion.
Every secondary heading should ideally serve as the entry point for a new vector chunk. This hierarchical discipline ensures that the context window remains focused on a singular topic.
When heading levels are skipped, the semantic parser assumes a missing contextual link. This can cause the entire section to be flagged as low-quality or structurally deficient during the embedding process.
Metadata-HTML Synchronization
Aligning semantic HTML tags with JSON-LD Schema reinforces data authority. This redundancy acts as a dual-verification system for AI extraction algorithms.
If you are utilizing an article tag, the Schema.org articleBody property must map exactly to the content within that boundary. Developers should consult the MDN Web Docs specification for the HTML article element to ensure compliance with W3C standards.
This synchronization creates a closed-loop validation system. The LLM can verify the structural boundaries against the explicit microdata declarations, boosting confidence scores.
Peripheral De-optimization
Peripheral elements must be explicitly de-optimized to protect the primary content signal. Modifying theme templates to use footer and aside tags achieves this programmatic demotion.
Applying aria-label attributes to these sections provides further context to AI agents. It explicitly labels utility zones, ensuring they are excluded from primary summarization tasks.
This proactive de-optimization is crucial for sites with high widget volumes. It prevents related posts or ad networks from bleeding into the primary vector embedding.
Technical Implementation
Executing Semantic Structural Mapping requires precise modifications to the DOM architecture. The goal is to create an unambiguous extraction target for LLMs.
Below is a standardized template demonstrating the optimal integration of semantic landmarks and microdata. Notice how the primary content is isolated from peripheral navigation and related resources.
<article itemscope itemtype='https://schema.org/TechArticle'>
<header>
<h1 itemprop='headline'>Optimizing Semantic HTML for AI</h1>
<p>Published on <time datetime='2026-05-25' itemprop='datePublished'>May 25, 2026</time></p>
</header>
<main itemprop='articleBody'>
<section>
<h2>The Role of Landmarks</h2>
<p>Semantic landmarks define the context for LLM extraction...</p>
</section>
</main>
<aside>
<h3>Related Resources</h3>
<ul><li>AI Indexing 101</li></ul>
</aside>
</article>This code structure ensures that the articleBody maps perfectly to the main semantic container. It leaves no ambiguity for the crawler regarding where the actual value of the page resides.
Validation & Future-Proofing
Validation & Monitoring
- Audit the Rendered HTML via GSC URL Inspection to ensure semantic tags persist post-JS execution.
- Verify vector chunk boundaries using Perplexity Pages to confirm ‘Main Content’ isolation.
- Cross-reference Schema.org ‘articleBody’ mapping against semantic <article> boundaries for data integrity.
- Confirm de-weighting of <aside> and <footer> by checking AI agent focus during summarization tests.
Monitoring the efficacy of Semantic Structural Mapping requires continuous validation against evolving AI crawlers. Traditional search console metrics are no longer sufficient for assessing vectorization success.
Engineers must utilize rendered HTML inspection tools to confirm that semantic tags persist after JavaScript execution. Client-side rendering frameworks often strip these critical landmarks if not configured correctly.
Testing URLs through consumer-facing AI interfaces provides direct feedback on chunk boundary isolation. If an engine summarizes sidebar content alongside the main article, the semantic boundaries are failing.
As Retrieval-Augmented Generation systems become more sophisticated, the penalty for structural ambiguity will increase. Maintaining a strict adherence to HTML5 semantics ensures your content remains highly accessible to machine readers.
Future updates to generative engines will likely rely even more heavily on implicit structural cues. Establishing a robust semantic foundation now prepares your platform for algorithmic shifts.
Navigating the intersection of traditional SEO and Generative Engine Optimization requires a precise architecture. To future-proof your enterprise stack for AI Overviews and LLM discovery, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
Why is semantic HTML important for Google AI Overviews?
According to a 2025 BrightEdge study, pages utilizing standard HTML5 semantic landmarks are 42% more likely to be selected as ‘Primary Context’ sources for Google AI Overviews. These tags provide a cognitive scaffolding that helps AI crawlers distinguish core arguments from peripheral noise, significantly improving visibility in search responses.
What is Semantic Structural Mapping (SSM)?
Semantic Structural Mapping (SSM) is the practice of using specific HTML5 landmarks to provide explicit signals to Retrieval-Augmented Generation (RAG) systems. It acts as a roadmap for the vector embedding process, ensuring that content is parsed, vectorized, and retrieved with maximum fidelity by AI search agents.
How do heading hierarchies affect AI vectorization and indexing?
AI crawlers segment pages into chunks for vector database storage. Proper use of <h1> through <h6> elements defines the boundaries of these chunks. Maintaining a strict linear hierarchy ensures that related concepts are embedded as a single coherent vector, preventing fragmented embeddings that perform poorly in similarity searches.
Can semantic HTML help reduce AI hallucinations?
Yes. By utilizing tags like <address> or <time>, developers provide explicit data types that LLMs use to verify facts against their training data. This process, known as Entity Relationship Parsing, creates a verifiable trail for AI crawlers, which reduces the risk of hallucinations during citation generation.
What is the benefit of using the <aside> tag for AI crawling?
Retrieval systems utilize a signal-to-noise ratio to determine content quality. Semantic elements like <aside> and <footer> are programmatically de-weighted during the extraction phase. This allows the AI engine to focus its attention on the primary content located within <main> or <article> tags, boosting the overall relevance score.
How should JSON-LD Schema be synchronized with semantic HTML?
To reinforce data authority, you should align Schema.org properties directly with semantic landmarks. For example, ensure the ‘articleBody’ property maps exactly to the content within the <article> tag. This synchronization creates a dual-verification system that increases the confidence scores of AI extraction algorithms.