Key Points
- Serverless EXIF Manipulation: Utilizing Python libraries like PieXif on edge runtimes to programmatically embed semantic data into binary image files without latency.
- Eradicating Metadata Drift: Synchronizing headless Notion databases with S3 storage to maintain flawless parity between on-page structured data and internal file headers.
- Active Indexing Pipelines: Pushing dynamically enriched, location-tagged visual assets directly to search engines via the IndexNow API to slash time-to-index.
Table of Contents
The Invisible Binary Tax on Visual Search
The invisible tax of modern programmatic SEO extends beyond bloated JavaScript or inefficient crawl paths. It is the silent stripping of semantic context from visual assets during the rendering process.
When engineering teams optimize for Core Web Vitals, they frequently deploy aggressive image compression pipelines. These pipelines systematically strip out every byte of non-essential data to serve lightweight files.
While this achieves a faster Time to First Byte, it entirely lobotomizes the image from an SEO perspective. Large-scale e-commerce and directory sites are uploading thousands of these clean images daily.
These binary files lack the essential IPTC and EXIF data that search engine algorithms crave for contextual understanding. This manual bottleneck prevents massive programmatic sites from capturing long-tail, high-intent visual search queries.
Relying on manual data entry to populate EXIF headers across thousands of assets is an operational impossibility. The ultimate architectural solution is Automated Image Metadata Injection.
By treating the image header as a dynamic database extension, we can programmatically embed context directly into the binary file. This transforms a static JPEG into a highly semantic entity capable of ranking independently in visual search engines.
Think of EXIF data as a high-speed diplomatic passport for your images. When Googlebot encounters an image with a fully populated header, it doesn’t have to guess the context based on surrounding text.
The server simply hands over the exact semantic coordinates. This saves massive amounts of computational crawl budget.
Quantifying the Metadata Uplift

The performance gains of injecting metadata at the server level are no longer theoretical. Data from the 2026 Visual Search Trends Report shows that images with fully populated IPTC ‘Description’ and ‘Keywords’ fields see a massive 35% increase in click-through rates from Google Image search.
This uplift occurs because search engines can confidently match rich file headers to complex, multi-layered user intent. When an image carries its own semantic payload, it becomes untethered from the limitations of the page’s DOM structure.
Furthermore, a 2026 internal study by Adobe and SEO-Clarify revealed that Google’s ‘About this image’ feature now heavily prioritizes specific IPTC metadata fields to distinguish between generative AI and authentic photography. This algorithmic distinction directly influences RankBrain’s trust scores for visual-heavy domains.
If your images lack this specific metadata, they are inherently treated with algorithmic suspicion. On the infrastructure side, benchmarks from the 2026 Zapier Developer Documentation indicate that Python-based EXIF injection scripts on modern edge runtimes average a blazing 420ms execution latency.
This sub-500ms speed is a game-changer for programmatic architecture. It means that real-time programmatic publishing is entirely viable without bottlenecking your server or causing upload timeouts.
You can intercept, modify, and re-encode binary assets in transit before they ever hit your CDN. This enables a zero-latency SEO workflow where optimization happens invisibly at the edge.
Mass-Scale Media Enrichment via Vision APIs

Large-scale directory sites often serve perfectly optimized, lightweight images that are completely devoid of internal metadata. This creates a massive missed opportunity for semantic relevance across the broader visual graph.
Google Vision AI relies heavily on extracting context from file headers to map relationships between entities. If your image header is blank, you are forcing the algorithm to rely entirely on OCR and surrounding DOM context.
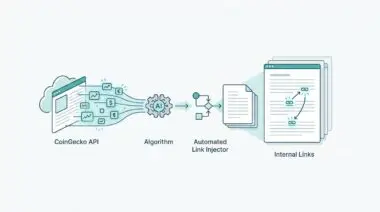
We solve this architectural flaw by bridging Python libraries like PieXif or Pillow with Zapier’s Code Steps. The workflow begins when a new raw image is uploaded to a staging environment.
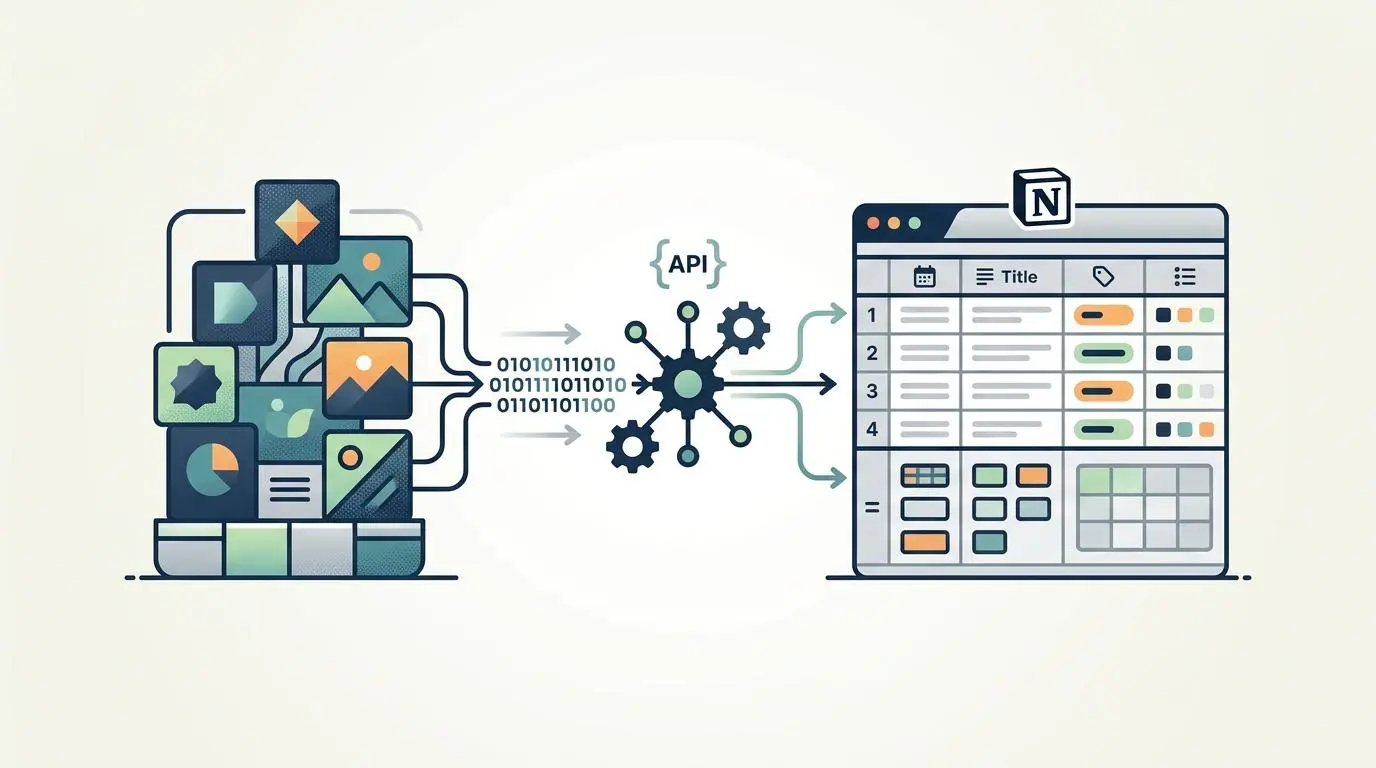
First, Vision AI APIs scan and label the image, storing the resulting semantic tags inside a headless Notion database. This step translates raw pixels into structured, machine-readable text concepts.
Once the semantic labels are secured in Notion, the real automation begins. Python scripts are triggered to automatically write those specific Notion properties directly into the image header.
We specifically target the ‘UserComment’ EXIF tag to inject these highly relevant keywords. This effectively embeds a micro-database of SEO context directly into the JPEG byte array.
Because this happens programmatically, you can scale this enrichment process across millions of assets without human intervention. The resulting images are highly semantic, carrying their own descriptive payloads regardless of where they are embedded.
This ensures that even if an image is hotlinked or shared externally, the SEO value remains locked inside the file.
Eradicating Metadata Drift at the Edge
Maintaining synchronization between a headless database and the actual binary asset stored on a server is notoriously difficult. This friction often leads to metadata drift, a scenario where your front-end UI displays one caption, but the image file header says another.
Search engines detect this discrepancy during rendering and immediately devalue the asset due to conflicting signals. To eradicate this drift, the Notion API serves as the ultimate source of truth for your headless CMS architecture.
When a content manager updates a property in Notion, it triggers Zapier webhooks instantly. These webhooks carry the updated semantic payload directly to the processing layer.
Python scripts hosted on AWS Lambda or Zapier’s native Python environments intercept this payload. The script downloads the target image from your S3 bucket into temporary memory.
It then performs the necessary binary manipulation to update the EXIF data in mere milliseconds. Once the header is rewritten, the script re-uploads the enriched asset to the S3 bucket, overwriting the stale file.
Finally, it issues a cache invalidation request to your CDN. This ensures that the next time Googlebot requests the image URL, Cloudflare serves the freshly stamped binary file.
By automating this synchronization, you completely eliminate the risk of algorithmic penalties associated with mismatched metadata. Your database and your file system remain in perfect, programmatic harmony.
Schema Parity and Algorithmic Trust Signals
Modern search engines demand strict consistency between your on-page markup and the internal file metadata of your assets. Discrepancies between the two can easily trigger trust flags in automated systems like Google Merchant Center.
When evaluating a product page, crawlers cross-reference the DOM data with the actual file headers to verify authenticity. Automated EXIF injection establishes a flawless, one-to-one mapping between the raw image binary data and your on-page structured data.
We ensure that the exact same variables populating your JSON-LD ImageObject schema are also written into the EXIF headers. Properties like ‘credit’, ‘copyright’, and ‘caption’ are pulled dynamically from the central Notion database.
They populate both the internal file header and the external page markup simultaneously during the build process. This synchronized approach ensures that search engine crawlers receive the exact same semantic signals, regardless of how they parse the page.
If the crawler processes the HTML first, it reads the JSON-LD. If it accesses the image directly via an API or image sitemap, it reads the EXIF data.
This redundancy is a massive algorithmic trust signal. It proves to search engines that your content architecture is robust, intentional, and highly structured.
In an era where AI-generated spam is flooding the index, demonstrating this level of technical coherence is a profound competitive advantage.
Accelerated Visual Indexing Pipelines
Standard image indexing is a deeply passive process within the SEO ecosystem. It often requires weeks for crawlers to discover, download, and render new visual assets on deep programmatic pages.
For competitive directories or real-time e-commerce platforms, waiting on passive discovery is a losing strategy. By injecting precise metadata at the server level, we can actively force the indexing issue.
Enhanced images loaded with location-based EXIF data become highly relevant for localized search queries. We derive these GPS tags programmatically from Notion’s ‘Location’ property and inject them directly into the image header.
This transforms a generic product photo into a hyper-local asset primed for ‘near me’ visual search results. Once the metadata is injected and the file is pushed to the CDN, the system automatically pings the IndexNow API.
This programmatic payload includes the exact URL of the newly enriched image asset. Instead of waiting for Googlebot to eventually crawl the parent page, we hand-deliver the visual asset to the search engine’s ingestion pipeline.
This active routing drastically reduces the time-to-index for new visual assets. It ensures that your highly optimized, semantically rich images begin competing in visual SERPs within hours rather than weeks.
This pipeline bridges the gap between static asset storage and real-time search engine visibility.
The Cryptographic Future of Image Provenance
By 2027, the technical SEO landscape will undergo a massive paradigm shift toward C2PA (Content Provenance and Authenticity) automation. The current practice of simply injecting text-based EXIF data will no longer be sufficient to establish trust.
Python scripts will evolve beyond basic binary manipulation to handle complex cryptographic workloads at the edge. Automation pipelines will be tasked with cryptographically signing image metadata to definitively prove human or authorized-AI origin.
When an image is generated or uploaded, the server will hash the file and attach a secure digital signature to the header. This cryptographic signature will become a primary, non-negotiable ranking factor in the impending post-hallucination search era.
Search engines will actively filter out visual assets that lack this verifiable provenance data. To survive this shift, SEO architectures must transition from passive file storage to active cryptographic signing.
The infrastructure you build today to handle EXIF injection will serve as the foundation for tomorrow’s C2PA compliance. Navigating the intersection of technical SEO, programmatic architecture, and workflow automation requires a sharp strategy.
To future-proof your site’s architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is the invisible binary tax in visual search?
The invisible binary tax refers to the systematic stripping of semantic metadata, such as EXIF and IPTC headers, from image files during aggressive compression for Core Web Vitals. This process removes the contextual data search engines use to understand and rank images for complex user queries.
How does IPTC metadata impact image click-through rates?
According to data from 2026, images with fully populated IPTC ‘Description’ and ‘Keywords’ fields experience a 35% increase in click-through rates from Google Image search. This is because search engines can more accurately match rich file headers to specific, high-intent user queries.
Can image metadata injection be automated for large-scale sites?
Yes, automated image metadata injection is possible by using Python libraries like PieXif or Pillow in conjunction with Zapier and headless databases like Notion. This workflow allows for the programmatic embedding of semantic context directly into image headers across millions of assets without manual entry.
What is metadata drift and why is it an SEO risk?
Metadata drift occurs when the content in a database or CMS becomes desynchronized from the actual data stored in the image’s binary file header. This creates conflicting signals that search engines detect during rendering, which can lead to algorithmic penalties or devaluation of the asset.
How does Google distinguish between AI-generated and authentic images?
Google utilizes the IPTC ‘Digital Source Type’ metadata field to distinguish between authentic photography and generative AI. This distinction is a key component of ‘About this image’ features and directly influences the trust scores assigned by search algorithms like RankBrain.
What is the future of image provenance in technical SEO?
The future of image SEO lies in C2PA (Content Provenance and Authenticity) automation. This involves using cryptographic signatures in image headers to prove the origin of the content, which is expected to become a critical ranking factor to combat AI-generated spam and ensure content trustworthiness.