
Key Points
- Crawl Budget Preservation: Normalizing UTM parameters at the edge prevents Googlebot from wasting crawl cycles on duplicate query strings.
- Signal Consolidation: Enforcing strict self-referential canonicals ensures link equity from social shares and external campaigns is funneled to the clean URL.
- Generative Engine Optimization: Eliminating parameter bloat improves the Information Gain score of a domain, making it more efficient for LLM-based RAG indexing.
The Core Conflict
According to a technical SEO audit of 1 million domains conducted by Ahrefs, duplicate content without a user-selected canonical affects over 60% of websites. Unmanaged tracking parameters like UTMs are the primary contributor to index bloat and crawl budget inefficiency.
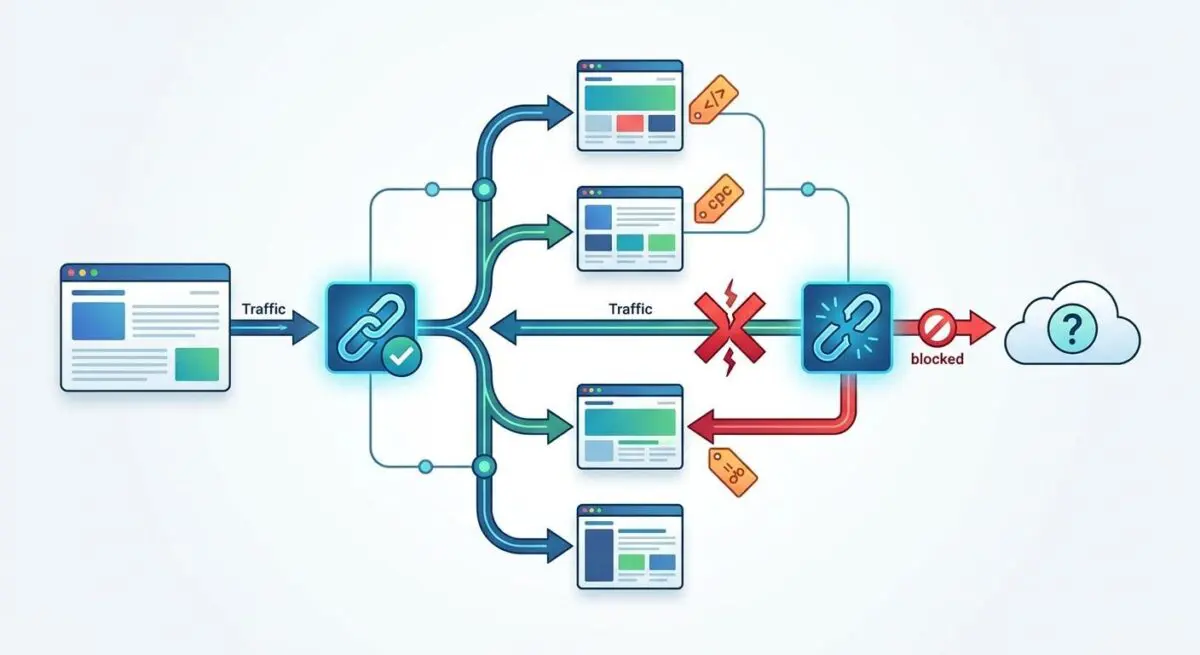
When you see the Alternate page with proper canonical tag status in Google Search Console, it means Googlebot has discovered a duplicate URL but correctly recognized the canonical version. For URLs with UTM parameters, this is technically an excluded status rather than a critical error. Google is successfully consolidating signals into the clean URL.
However, it still consumes significant server resources during the crawl phase. Raw server log files will show Googlebot requests for URLs with strings like ‘?utm_medium=’, returning a 200 OK status. From a Generative Engine Optimization perspective, excessive occurrences of this status suggest crawlers are wasting cycles on redundant parameter strings.
This redundancy dilutes the Information Gain score of a domain. If an LLM-based crawler identifies thousands of alternate pages, it may deprioritize your site for real-time RAG indexing. The noise-to-signal ratio of your URL structure becomes highly inefficient.
Diagnostic Checkpoints
This error is rarely a simple plugin misconfiguration. It is usually a desynchronization across your server, edge, and application layers.
Diagnostic Checkpoints
Internal UTM Parameter Leakage
Prevent internal links from spreading tracking parameters across site.
Edge Cache Variant Fragmentation
Normalize edge cache to serve single objects for UTMs.
Social Sharing & Third-Party Backlinks
Apply self-referencing canonicals for incoming social traffic landing pages.
Inconsistent Protocol or Trailing Slashes
Align canonical tags with server-level URL path formatting rules.
Internal UTM parameter leakage forces the crawler to process duplicate pages just to find the canonical tag. This commonly occurs when content teams copy-paste URLs from live campaigns directly into the CMS without stripping the tracking strings.
Edge cache variant fragmentation happens when CDNs like Cloudflare or Varnish cache content based on the full query string. The edge layer serves unique objects for every UTM variation, leading to increased crawler discovery of alternate URLs.
Social sharing and third-party backlinks automatically append tracking parameters. When Googlebot crawls these external links, it enters the site via the UTM-tagged URL, and without a robust canonical setup, the alternate page count spikes.
Inconsistent protocol or trailing slashes combined with UTMs create a distinct path in Googlebot’s eyes. This often creates canonical hop scenarios where a UTM URL redirects through multiple states before the canonical tag is parsed.
The Engineering Resolution
Resolving this index bloat requires a multi-layered approach to normalize URLs before Googlebot expends crawl budget.
Engineering Resolution Roadmap
Enforce Self-Referential Canonicals
Ensure your SEO plugin (RankMath, Yoast, or SEOPress) is configured to strip query parameters from the canonical URL. The <link rel=’canonical’> should always point to the base URL regardless of the UTM strings present in the browser address bar.
Normalize Query Strings at the Edge
Configure your CDN (e.g., Cloudflare) to ‘Ignore Query Strings’ for caching purposes specifically for UTM parameters. This ensures the origin only serves one version of the page, reducing server load during Googlebot’s discovery phase.
Configure GSC URL Parameter Tool
While the legacy tool is deprecated, ensure that any active ‘URL Parameters’ settings in GSC label ‘utm_source’, ‘utm_medium’, and ‘utm_campaign’ as ‘Representative URL’ (Does not affect page content) to signal to Google that these are tracking variants.
Audit Internal Linking via SQL
Run a database query on the wp_posts table to identify and remove any UTM parameters embedded in internal links. Use a search-and-replace tool like WP-CLI to bulk-strip these parameters to stop Googlebot from discovering them internally.
Enforcing self-referential canonicals ensures that the link element always points to the base URL. This must hold true regardless of the UTM strings present in the browser address bar.
Normalizing query strings at the edge is critical for reducing server load. By configuring your CDN to ignore query strings for caching, the origin only serves one version of the page.
Auditing internal links via SQL directly targets the source of internal crawl bloat. Running database queries to strip embedded UTM parameters stops Googlebot from discovering them natively.
The Code Implementations
Applying the correct server-level or application-level rules ensures that tracking parameters are handled efficiently.
Fixing via NGINX
This configuration strips UTM parameters at the server block level and forces a clean canonical HTTP header.
if ($args ~* "utm_") { set $strip_utm 1; }
add_header Link "<$scheme://$host$uri>; rel=\"canonical\"" always;Fixing via Apache
This rule intercepts requests containing UTM parameters and issues a 301 redirect to the clean URL, stripping the query string.
RewriteEngine On
RewriteCond %{QUERY_STRING} ^(.*)utm_ [NC]
RewriteRule ^(.*)$ /$1? [R=301,L]Fixing via WordPress functions.php
This PHP filter hooks into the SEO plugin’s canonical generation to forcefully strip any query parameters before the tag is output in the document head.
add_filter( 'wpseo_canonical', 'tech_seo_strip_utm_from_canonical' );
function tech_seo_strip_utm_from_canonical( $canonical ) {
return strtok($canonical, '?');
}Validation Protocol & Edge Cases
After deploying server or application-level fixes, you must validate the response exactly as Googlebot interprets it.
Validation Protocol
- Execute cURL with Googlebot User-Agent to verify clean canonical headers.
- Validate URL Inspection results match user-declared and Google-selected canonicals.
- Confirm static canonical persistence in DevTools Network tab via parameters.
Headless WordPress setups using a React frontend present a unique edge case. Here, the canonical tag is often managed via libraries like react-helmet.
If the frontend hydration fails or a tracking library modifies the DOM before Googlebot’s second-pass rendering, the canonical tag might dynamically update. It can accidentally capture the current window location, including UTMs.
This dynamic override causes a canonical mismatch and prevents signal consolidation. Always verify the raw HTML payload, not just the rendered DOM.
Autonomous Monitoring & Prevention
To prevent future parameter bloat, you must implement a strict policy against internal UTM linking. Rely on automated log analysis using the ELK stack or Screaming Frog Log File Analyser to monitor crawl frequency.
Setting up a Content Security Policy or using JavaScript to strip UTM parameters from the URL after the analytics script has fired is highly effective. This prevents users from sharing the parameter-heavy version.
At an enterprise scale, monitoring entity integrity requires advanced automation. Building custom Make.com pipelines to parse server logs and trigger API alerts is the ultimate way to maintain a pristine crawl space.
Andres SEO Expert utilizes these automated diagnostic frameworks to catch parameter leakage before it impacts your generative search visibility.
Conclusion
Unmanaged query parameters create massive inefficiencies in how search engines process your architecture. By strictly defining canonical rules and normalizing edge caching, you reclaim wasted crawl budget.
Navigating the intersection of technical SEO, server architecture, and generative search requires a precise roadmap. If you need to future-proof your enterprise stack, resolve deep-level crawl anomalies, or implement AI-driven SEO automation, connect with Andres at Andres SEO Expert.