Key Points
- Asynchronous Offloading: Utilizing Action Scheduler prevents fatal PHP timeouts during the GPT-4o vision analysis of large WordPress media uploads.
- Cost-Efficient Scaling: Deploying Vision-Nano models enables the bulk backfilling of legacy media libraries, reducing API expenditures to fractions of a cent per asset.
- Semantic Grounding: AI-generated alt text acts as a foundational layer for RAG systems, necessitating strict prompt constraints to prevent knowledge base corruption.
Table of Contents
The Scale-to-Semantic Bottleneck
Start by exposing the invisible tax of manual SEO execution. Every time a content team uploads hundreds of product images to a WordPress media library, massive technical debt accrues in real-time.
This is known as the Scale-to-Semantic gap. High-velocity environments simply cannot manually generate WCAG 2.2-compliant and SEO-rich metadata for the sheer volume of assets pushed to the server.
The result is a sprawling graveyard of dark visual assets. These unoptimized images render perfectly on the frontend but remain entirely invisible to LLM-based search crawlers and screen readers alike.
Without semantic context, search engines cannot map the visual content to the surrounding text nodes in the DOM. This forces Googlebot’s Web Rendering Service to waste valuable crawl budget parsing empty attributes.
Ultimately, this degrades the page’s overall topical authority. To solve this critical rendering bottleneck, technical SEOs are turning to Vision-AI Image Metadata Orchestration.
This architectural shift completely automates the generation of descriptive alternative text using multimodal APIs. By triggering these AI models directly during the native WordPress upload sequence, developers guarantee immediate semantic enrichment.
Every single image is infused with rich semantic data before it ever hits the live database.
Quantifying the Visual Void
The scale of this missing metadata is staggering across the modern web. The WebAIM Million 2026 report highlights that over half of the top one million homepages still lack alternative text for images.
This represents a massive automation opportunity for technical SEOs looking to achieve immediate accessibility compliance and semantic depth. Manual tagging simply cannot close an operational gap of this magnitude.
Entire e-commerce catalogs are currently failing core accessibility audits because merchandising teams cannot keep pace with upload velocity. Fortunately, the underlying infrastructure to fix this has reached unprecedented speeds.
The LMSpeed Latency Leaderboard as of June 2026 records a median time-to-first-token of 0.73 seconds for the gpt-5.4 model family. This sub-second vision latency makes real-time image metadata generation highly feasible for live WordPress uploads.
We no longer have to worry about synchronous server timeouts dragging down the editorial workflow. To properly orchestrate these fast API responses within complex site architectures, developers are utilizing frameworks built on the Model Context Protocol (MCP).
This ensures the AI can process visual data with full awareness of the surrounding CMS environment. It effectively bridges the gap between raw speed and contextual accuracy.
Architectural Deep Dives

Solving the Scale-to-Semantic gap requires a multi-layered programmatic approach. Technical SEOs must move beyond basic API scripts and architect robust pipelines.
These pipelines must handle scale, context, and schema validation simultaneously. The following sections break down the core components of a modern Vision-AI orchestration pipeline.
Scaling Visual Analysis Endpoints
As of June 2026, the industry has transitioned away from legacy CLIP-based encoders. We now rely on multimodal endpoints like OpenAI’s gpt-5.4-mini and the Responses API to achieve sub-second visual analysis.
Modern workflows utilize the gpt-image-2 model for high-fidelity extraction of OCR data and visual context. This extracted data is then mapped directly into the WordPress post_excerpt and _wp_attachment_image_alt metadata fields.
This programmatic mapping ensures that infographics, charts, and product photos containing embedded text are fully readable by search engine parsers.
However, processing massive media libraries with over 100,000 assets presents significant architectural hurdles. Large-scale backfills frequently hit API rate limits and create severe cost-inefficiencies when relying solely on frontier models.
The key to scaling visual analysis is intelligent endpoint routing based on the asset’s lifecycle stage.
To bypass this friction, technical architects are pivoting to Vision-Nano models for bulk processing. This strategic downgrade mitigates the processing cost to roughly fractions of a cent per image.
It achieves this cost reduction while maintaining high semantic accuracy. By tiering the API calls, teams can optimize their operational budgets without sacrificing SEO value.
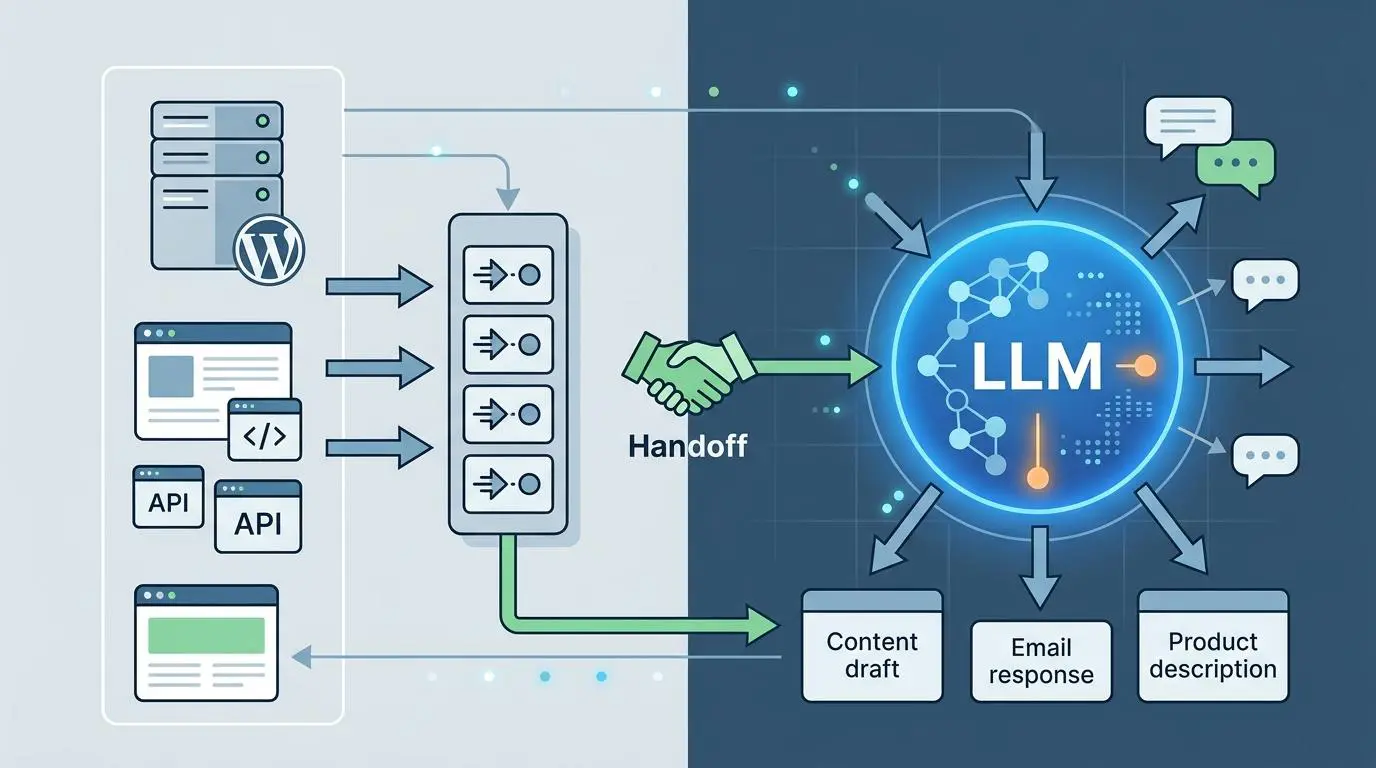
Decoupling the PHP-to-LLM Handoff

Advanced automation now fundamentally relies on deep integrations with the WordPress REST API. Agentic AI frameworks now use standard context protocols to detect active WordPress plugins and theme settings.
This allows the AI agent to literally see the image within its actual layout before writing the alt text. Frameworks tap into active theme CSS variables to ensure the generated text is stylistically consistent with the site’s brand voice.
This level of environmental awareness prevents the AI from generating generic, disconnected descriptions. However, the primary architectural bottleneck in this process occurs during the PHP-to-LLM handoff.
Native WordPress add_attachment hooks are notorious for timing out during large image processing sequences. When a user uploads a heavy image, forcing PHP to wait for an external LLM response often results in a fatal 504 Gateway Timeout.
To maintain server stability, engineers must implement asynchronous offloading. Pushing these API calls to WP-Cron or Action Scheduler ensures the upload process remains decoupled from the heavy LLM computation.
Injecting Visual Entities into Schema
Vision AI output is no longer confined to basic HTML attributes. It is now being programmatically mapped to complex ImageObject and VideoObject JSON-LD schema.
Developers use advanced models to extract highly specific visual entities from the media payload. This allows for the dynamic injection of significantLink and about properties into the structured data without any manual tagging.
For example, if the AI detects a specific brand logo in a lifestyle image, it can automatically link that entity to the corresponding brand entity in the site’s knowledge graph.
However, this automated schema generation carries a unique operational risk. Mismatches between the AI-generated alt text and the hardcoded Schema caption field can trigger severe semantic consistency flags.
These flags frequently surface in Google’s Search Console Merchant Listings reports, potentially suppressing product visibility. Strict validation layers must be placed between the API response and the final JSON-LD render.
Technical SEOs must ensure that the programmatic pipeline sanitizes the AI output. It must perfectly match the exact schema specifications required by search engines.
Grounding RAG with Semantic Alt Text
Generative Engine Optimization now treats alt text as a critical grounding mechanism for Retrieval-Augmented Generation. By injecting rich semantic descriptions into image metadata, these visual assets become inherently searchable.
This enables natural language vector-search interfaces within both site-internal search bots and Google’s AI Overviews. When a user asks a conversational search engine to retrieve images of a specific architectural style, the RAG system relies entirely on the underlying semantic alt text.
The danger here lies in LLM hallucinations. If the AI identifies a generic laptop as a specific MacBook Pro model, it corrupts the site’s entire RAG knowledge base.
These false visual entities lead to highly inaccurate answers in conversational search interfaces. Prompt engineering must strictly constrain the vision model to describe only visible, verifiable elements.
Developers must implement strict temperature controls and confidence thresholds in the API payload. This prevents the AI from hallucinating product specifications that do not exist in the pixel data.
The Intent-Aware Future of Metadata
By 2027, alt-text automation will shift entirely from static strings to intent-aware dynamic metadata. Descriptions will be served on-the-fly based on the exact context of the user’s search query.
A user searching for sustainable materials will receive alt text highlighting the recycled fabric of a garment. Meanwhile, a fashion trends search will yield text describing the silhouette.
This edge-based rendering will redefine how we approach media optimization. Instead of a single static description living in the database, edge workers will intercept the HTML response.
They will rewrite the visual metadata based on the referring query parameters. This ensures that the semantic context is always perfectly aligned with the user’s immediate search intent.
Navigating the intersection of technical SEO, programmatic architecture, and workflow automation requires a sharp strategy. To future-proof your site’s architecture and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is the Scale-to-Semantic Bottleneck in image SEO?
The Scale-to-Semantic Bottleneck refers to the technical gap where high-velocity teams cannot manually generate metadata for the volume of assets being uploaded. This results in dark visual assets that are invisible to LLM-based search crawlers, leading to wasted crawl budget and degraded topical authority.
How does Vision-AI automate WordPress alt-text generation?
Vision-AI automates the process by triggering multimodal APIs during the native WordPress upload sequence. These models analyze visual context and OCR data to programmatically populate metadata fields like post_excerpt and alt text before the asset is finalized in the database.
Why is asynchronous offloading necessary for AI image metadata?
Synchronous PHP calls to external LLMs during an upload can lead to 504 Gateway Timeouts. By using asynchronous offloading through tools like WP-Cron or Action Scheduler, developers decouple heavy AI computation from the upload process, maintaining server stability.
How does Vision-AI improve JSON-LD Schema for technical SEO?
Vision-AI extracts specific visual entities from media payloads to dynamically inject significantLink and about properties into ImageObject schema. This programmatic mapping ensures visual content is accurately represented in a site’s knowledge graph for search engine parsers.
What role does alt text play in Retrieval-Augmented Generation (RAG)?
Alt text serves as a grounding mechanism for RAG, enabling conversational search interfaces to retrieve images via natural language vector-search. Rich semantic descriptions prevent AI hallucinations by providing verifiable context for search engines to interpret pixel data.
What is the benefit of using Vision-Nano models for bulk image processing?
Vision-Nano models allow for cost-efficient bulk processing of massive media libraries. By tiering API calls and using smaller models for backfills, technical SEOs can maintain high semantic accuracy while reducing processing costs to fractions of a cent per image.