Executive Summary
- RAG pipelines bridge the gap between static LLM training data and real-time, proprietary information through vector-based retrieval.
- The architecture minimizes hallucinations by grounding model outputs in verifiable external documents, enhancing factual reliability.
- Effective implementation requires optimized data chunking, high-dimensional embedding models, and sophisticated re-ranking layers.
What is RAG Pipeline?
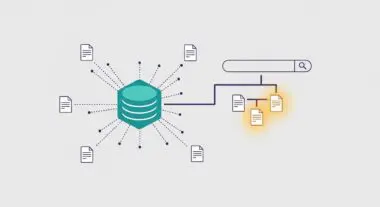
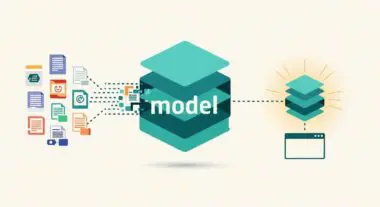
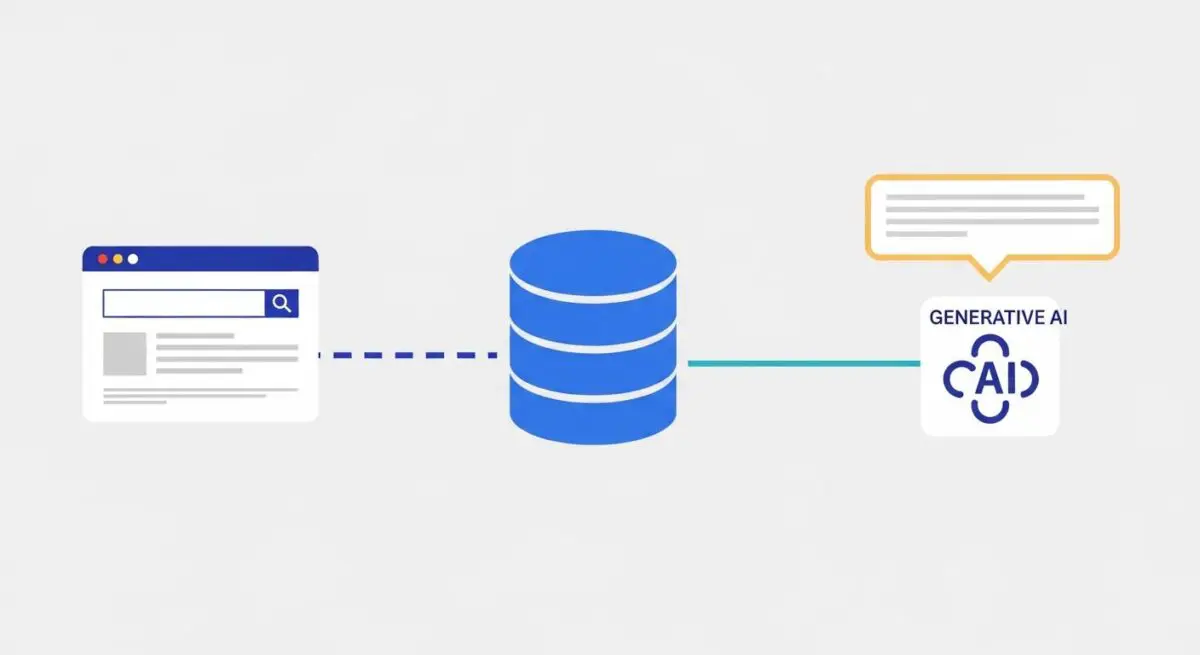
A Retrieval-Augmented Generation (RAG) pipeline is a sophisticated architectural framework designed to optimize the output of a Large Language Model (LLM) by referencing an authoritative, external knowledge base outside of its initial training data. In a standard LLM interaction, the model relies solely on its internal parametric memory. A RAG pipeline introduces a non-parametric memory component, typically a vector database, which allows the system to query specific documents or data points relevant to a user’s prompt before the generation phase begins.
The technical workflow of a RAG pipeline involves three distinct stages: retrieval, augmentation, and generation. During retrieval, the system converts the user query into a mathematical vector and searches a high-dimensional space for semantically similar data chunks. In the augmentation phase, this retrieved context is appended to the original prompt. Finally, the LLM generates a response based on both its pre-trained knowledge and the newly provided context, ensuring the output is grounded in specific, up-to-date information.
The Real-World Analogy
Imagine a highly intelligent legal researcher who has memorized thousands of laws but hasn’t read any new cases in the last two years. If you ask them about a law passed yesterday, they might guess or provide outdated information. A RAG pipeline is like giving that researcher a high-speed connection to a digital law library. Instead of answering from memory, the researcher first looks up the most recent statutes and court rulings, reads them, and then provides a comprehensive, cited answer. The researcher’s intelligence remains the same, but their access to verified, current facts makes their output significantly more reliable.
Why is RAG Pipeline Important for GEO and LLMs?
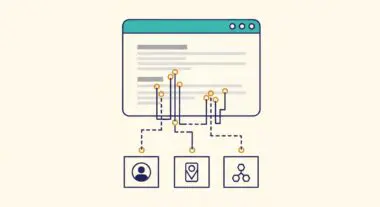
For Generative Engine Optimization (GEO), the RAG pipeline is the primary mechanism through which AI search engines like Perplexity, ChatGPT, and Google Gemini identify and cite external sources. Because these engines prioritize groundedness to avoid misinformation, content that is easily retrievable—meaning it is well-structured, semantically clear, and rich in entities—is more likely to be pulled into the augmentation phase. This directly impacts a brand’s visibility in AI-generated summaries and source attribution lists.
Furthermore, RAG pipelines allow for the integration of proprietary data without the need for expensive model fine-tuning. By maintaining a dynamic vector store, organizations can ensure that AI agents have access to the latest product specifications, technical documentation, or market insights. This architecture shifts the focus of SEO from keyword density to semantic relevance and document hierarchy, as the retrieval algorithms prioritize contextually dense chunks of information over traditional web pages.
Best Practices & Implementation
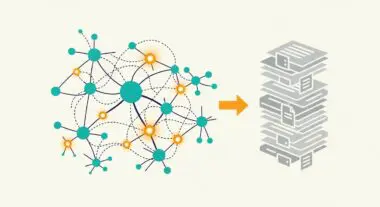
- Optimize Chunking Strategies: Break down content into semantically coherent segments that maintain context. Use overlapping windows to ensure that information at the boundaries of chunks is not lost during the embedding process.
- Implement Advanced Re-ranking: After the initial vector search, use a cross-encoder or a re-ranking model to evaluate the relevance of the top-k retrieved documents. This ensures only the most pertinent information is passed to the LLM.
- Metadata Enrichment: Annotate data chunks with rich metadata, including source URLs, timestamps, and entity tags. This assists the retrieval engine in filtering results and enables the LLM to provide precise citations.
- Continuous Embedding Alignment: Ensure that the embedding model used for the vector database is compatible with the query processing model to maintain high semantic precision across the high-dimensional space.
Common Mistakes to Avoid
One frequent error is utilizing a one-size-fits-all chunking approach, which often results in the LLM receiving fragmented or irrelevant context, leading to incoherent responses. Another critical mistake is neglecting the “lost in the middle” phenomenon, where LLMs struggle to process information located in the center of a long augmented prompt; prioritizing the most relevant data at the beginning or end of the context window is essential. Finally, many organizations fail to update their vector stores, causing the RAG pipeline to serve stale or deprecated information to the generative model.
Conclusion
The RAG pipeline is the foundational architecture for modern AI search, transforming LLMs from static knowledge engines into dynamic, factually grounded systems. Mastering its mechanics is essential for ensuring content authority and visibility within the evolving landscape of Generative Engine Optimization.