Executive Summary
- Architectural Convergence: The Data Lakehouse has emerged as the 2026 enterprise standard, unifying the high-performance structured querying of warehouses with the massive scalability of data lakes.
- Economic Efficiency: Transitioning to a unified lakehouse architecture typically reduces total operational costs by 40% to 60% by eliminating redundant data copies and decoupling compute from storage.
- AI Orchestration: Modern lakehouses now support Agentic Orchestration, allowing AI agents to interact directly with data layers via Open Table Formats like Apache Iceberg and Delta Lake 4.0.
The Evolution of Enterprise Data Architecture
In the current 2026 market landscape, the distinction between how a business stores data and how it extracts value from it has blurred. For decades, leadership teams were forced to choose between two rigid silos: the structured, high-performance environment of the Data Warehouse and the vast, unstructured repository of the Data Lake. This fragmentation created a strategic bottleneck, where data scientists and business analysts operated in separate worlds, leading to delayed insights and ballooning infrastructure costs.
The global shift toward a unified architecture is no longer a theoretical preference but a competitive necessity. With the global Data Lakehouse market reaching a valuation of $12.58B this year, the industry has signaled a definitive move toward consolidation. Organizations are moving away from the friction of moving data between disparate systems and are instead adopting platforms that offer the reliability of a warehouse with the flexibility of a lake. This transition is driven by the need for real-time AI orchestration and the increasing pressure to demonstrate significant ROI on data initiatives.
Defining the Three Pillars: Warehouse, Lake, and Lakehouse
To understand the strategic trajectory of modern business intelligence, one must first distinguish between the foundational architectures that have defined the last twenty years of computing. While the terminology often overlaps, the operational implications of each are distinct.
The Data Warehouse: The Structured Archive
A Data Warehouse is a centralized repository designed for the storage of structured data. It is optimized for SQL-based querying and Business Intelligence (BI) reporting. In this environment, data must be cleaned, transformed, and formatted before it is even allowed into the system—a process known as Schema-on-Write. While this ensures high performance and data integrity, it lacks the flexibility to handle the massive influx of unstructured data, such as video, audio, and raw sensor logs, that define the modern digital economy.
The Data Lake: The Raw Reservoir
The Data Lake was the industry’s answer to the volume problem. It allows for the storage of data in its rawest form, regardless of structure. This Schema-on-Read approach provides immense flexibility and lower storage costs, as it utilizes inexpensive object storage. However, lakes often suffer from a lack of governance, poor query performance, and the risk of becoming data swamps where information is stored but never successfully retrieved or utilized for decision-making.
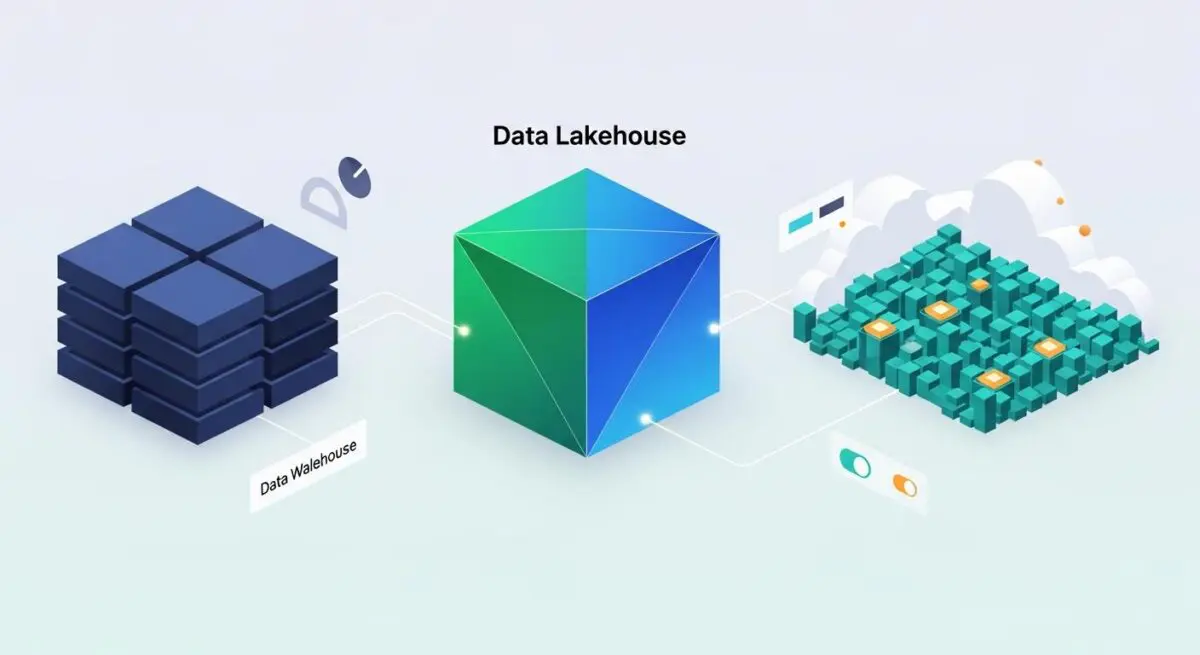
The Data Lakehouse: The Unified Standard
The Data Lakehouse is the architectural evolution that combines the best of both worlds. By implementing a metadata layer on top of low-cost cloud storage, it enables ACID (Atomicity, Consistency, Isolation, Durability) transactions, which were previously the exclusive domain of warehouses. This allows businesses to run high-performance analytics and machine learning workloads on a single, unified platform. It eliminates the need for expensive ETL (Extract, Transform, Load) processes that move data between lakes and warehouses, significantly reducing the surface area for errors and data staleness.
The Data Warehouse is like a meticulously organized library where every book is indexed but new arrivals take months to shelf; the Data Lake is a massive warehouse of unsorted boxes where everything is kept but nothing can be found. The Data Lakehouse is a digital archive where the system automatically catalogs every item the moment it arrives, allowing you to search the entire collection with the speed of a search engine.
The Strategic Impact of Open Table Formats
The technical engine driving the lakehouse revolution is the adoption of Open Table Formats. Technologies such as Apache Iceberg, Delta Lake 4.0, and Apache Hudi have become the plumbing of the modern enterprise. These formats allow different tools—from AI agents to traditional BI dashboards—to access the same data simultaneously without creating proprietary lock-ins. This interoperability is critical for long-term scalability, as it prevents a company from being tethered to a single vendor’s ecosystem.
Furthermore, these formats enable features like time travel, which allows data engineers to query previous versions of a dataset for auditing or model retraining. In an era where data quality is cited by 64% of organizations as the primary hurdle to scaling AI, the ability to maintain a high-integrity, version-controlled data layer is a significant competitive moat. The shift toward these open standards has allowed enterprises to decouple their data from their compute, meaning they only pay for the processing power they use during active queries, rather than maintaining idle, expensive warehouse capacity.
AI Orchestration and the Agentic Lakehouse
The most significant breakthrough in recent months is the rise of the Agentic Lakehouse. We are moving beyond simple data retrieval toward a model where autonomous AI agents interact directly with the data layer. These agents, managed through orchestration layers like Microsoft Copilot or Salesforce OSI, no longer just read data; they write operational states and manage data pipelines autonomously. This shift is supported by serverless, PostgreSQL-compatible databases like Databricks Lakebase, which allow agents to maintain state within the lakehouse environment.
This level of integration is essential for Generative Search Optimization (GEO). As search engines evolve into AI-synthesized response engines, businesses must ensure their data is structured in a way that AI models can accurately cite and reference. A fragmented data stack makes this nearly impossible, whereas a unified lakehouse provides a single source of truth that can be indexed and served to generative models in real-time. Organizations leveraging this architecture are seeing a 25x acceleration in pipeline development, allowing them to react to market shifts in hours rather than weeks.
Navigating Scalability Friction and Regulatory Compliance
Despite the clear advantages, the path to a unified architecture is not without friction. The engineering talent crisis remains a dominant concern, with 90% of organizations reporting a shortage of specialized IT professionals capable of managing these complex systems. This skills gap is projected to have a multi-trillion dollar impact on the global economy. Consequently, many firms are turning to automated data engineering tools to bridge the gap, reducing the manual labor involved in ETL by up to 83%.
Simultaneously, the regulatory environment has become more stringent. The enforcement of the EU AI Act has shifted the burden of proof onto corporations to demonstrate the integrity and non-negligence of their AI systems. A lakehouse architecture simplifies this compliance burden by providing a centralized, auditable trail of all data used to train and inform AI models. Under the new strict liability rules, having a fragmented data stack is no longer just an operational inefficiency—it is a significant legal risk that could result in fines of up to 7% of global revenue.
Andres’ Masterclass: The Big Picture
From my perspective in the strategy room, the debate between warehouses and lakes is effectively over. The real strategic challenge now lies in how quickly an organization can migrate its fragmented legacy systems into a unified lakehouse without disrupting current operations. The goal is not just storage; it is data gravity. By centralizing your data assets into a high-performance, open-format environment, you create a gravitational pull that attracts better talent, more efficient AI agents, and ultimately, higher-quality insights. This is the foundation of a modern competitive moat.
We must view data architecture through the lens of capital allocation. Moving to a lakehouse typically yields a 10.3x ROI compared to the 3.7x seen in poorly integrated models. This massive delta is driven by the elimination of redundant data copies and the ability to scale workloads elastically. For the CEO, the lakehouse represents the transition from data as a cost center to data as a high-yield asset. If your organization is still struggling with agent sprawl across legacy silos, you are not just losing efficiency—you are losing the ability to compete in an AI-driven market.
Future-Proofing Your Data Strategy
The transition to a unified data architecture is the most critical infrastructure decision of the decade. By choosing a lakehouse model, businesses can ensure they are prepared for the next wave of AI orchestration while maintaining the rigorous governance required by global regulators. The focus must remain on data quality, open standards, and the seamless integration of AI agents into the core data layer.
Navigating the intersection of generative search and operational efficiency requires more than just tools—it requires a roadmap. If you’re ready to evolve your strategy through specialized SEO, GEO, Adavanced Hosting Environments, or AI-driven automation, connect with Andres at Andres SEO Expert. Let’s build a future-proof foundation for your business together.