Key Points
- Provenance Injection: Integrating the Citation-Standard-v2 API allows websites to inject cryptographic headers, instantly verifying content origin for AI crawlers like GPTBot.
- Semantic Consistency: LLMs now demand a semantic consistency score of 0.89 Kappa or higher against trusted seed entities to cite a domain for critical YMYL queries.
- Context-Aware Chunking: Utilizing serverless vector databases ensures complex authoritative claims are never split across vector boundaries, preserving vital retrieval signals.
Table of Contents
- The Invisible Cost of the Attribution Void
- Decoding the Math Behind AI Trust
- Injecting Provenance with Automated Citation Pipelines
- Resolving Entity Ambiguity Through Knowledge Graphs
- Mitigating Hallucinations with NLI Validation
- Preserving Context with Semantic Chunking
- The Dawn of Autonomous Reputation Wallets
The Invisible Cost of the Attribution Void
Every single day, brilliant and highly researched content is silently passed over by AI assistants because it lacks the mathematical signals required for modern retrieval. This silent loss of traffic and relevance happens when brands ignore how large language models evaluate content authority.
We have officially entered an era where ranking on a traditional search engine results page means very little if the underlying AI engine does not recognize your brand as a verifiable source of truth. The fundamental architecture of discovery has shifted from counting hyperlinks to calculating semantic trust.
Traditional search engine optimization relies heavily on hyperlink-based PageRank. It operates much like a high school popularity contest, assuming that if many people point to a page, it must be valuable.
However, large language models do not care about popularity. They evaluate authority through semantic proximity to established seed truths and mathematical consensus across their vast training sets.
If your content cannot be mathematically verified against these core truths, your traditional backlink profile becomes entirely secondary.
This creates a massive hurdle known as the Attribution Void. When an AI generates an answer, it synthesizes information from countless vectorized data points.
If your website lacks the precise entity alignment and semantic clarity required by the model, the AI will simply extract your insights and attribute them to a larger, more easily verifiable aggregator.
Overcoming this void requires a deep understanding of LLM Probabilistic Authority Scoring. This framework forces us to re-engineer how we publish, structure, and validate our digital knowledge.
Decoding the Math Behind AI Trust
To truly master Generative Engine Optimization, we must look past keywords and examine the raw mathematical thresholds that dictate AI visibility. The landscape of search is now governed by strict semantic consistency requirements.
Websites utilizing entity-linked structured data saw a 72% increase in being cited as the primary source in Google AI Overviews compared to those using standard HTML. This massive source attribution lift demonstrates that providing clear, machine-readable context is no longer optional.
This structural evolution aligns perfectly with modern search engine guidelines for AI overviews. These updated standards heavily emphasize the importance of distinct, verifiable content formatting.
When a crawler parses your page, it is not just reading text; it is mapping relationships. If those relationships are explicitly defined through structured data, the model requires far less computational effort to trust your claims.
Lower computational effort directly translates to higher citation frequency in generative responses.
Furthermore, the bar for trust in sensitive topics has never been higher. The 2026 Stanford AI Index reveals that LLMs now require a semantic consistency score of 0.89 Kappa or higher against trusted seed entities to feature a domain as a top-tier citation for Your Money Your Life queries.
This means your content cannot simply be accurate in isolation. It must mathematically align with the broader consensus of medical, financial, or legal knowledge embedded within the model’s neural network.
Injecting Provenance with Automated Citation Pipelines
One of the most critical challenges in the generative search era is proving that you are the original author of an insight. We solve this by integrating the Citation-Standard-v2 API to inject cryptographic provenance headers directly into the HTTP response.
Think of this as sealing your content in a tamper-proof digital envelope. When AI crawlers like GPTBot and ClaudeBot hit your server, they instantly read these cryptographic headers and verify your content’s origin without having to cross-reference the entire web.
This cryptographic sealing is essential for the retrieval-augmented generation phase. During RAG, an AI model pulls real-time data to ground its answers and avoid hallucinations.
If your content carries verified provenance headers, the AI engine assigns it a significantly higher trust score. It acts as a fast-pass lane for your data, bypassing the intense scrutiny applied to unverified, anonymous web pages.
However, implementing this level of verification introduces severe real-world friction. Legacy content management systems simply lack the architecture to dynamically generate granular, source-level metadata.
Most traditional platforms output flat HTML, forcing technical SEO teams to build custom middleware solutions. Upgrading your server infrastructure to support dynamic cryptographic headers is the first mandatory step toward securing your intellectual property in an AI-first ecosystem.
Resolving Entity Ambiguity Through Knowledge Graphs
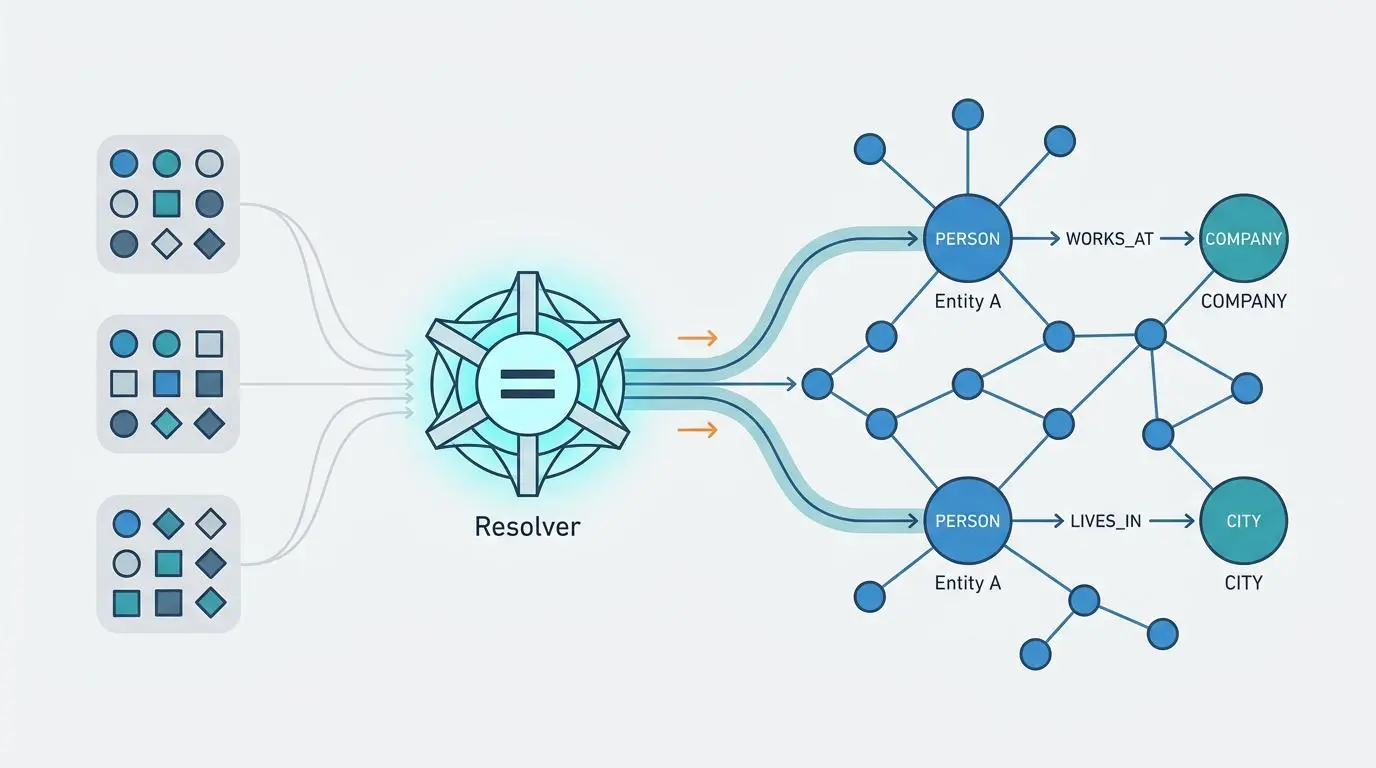
Even with verified provenance, an AI model must still understand exactly who or what your brand is. This is where entity resolution and knowledge graph automation become vital.
By utilizing the Google Knowledge Graph API and Wikidata SPARQL wrappers, we can automate the injection of precise sameAs schema across an entire domain. This programmatic approach ensures that an LLM recognizes your website as the definitive, authoritative owner of a specific semantic entity.
Imagine walking into a crowded room where five people share your exact name. Without a unique identifier, any accomplishments you mention might be credited to someone else.
This is entity ambiguity, and it remains a massive bottleneck in generative search. Without programmatic entity linking, LLMs often become confused by overlapping terminology and attribute your hard-earned authoritative facts to high-traffic aggregators like Wikipedia or major news outlets.
By aggressively mapping your brand and authors to established knowledge bases, you eliminate this confusion. The AI no longer has to guess if your brand is the same entity mentioned in a trusted industry journal.
The automated SPARQL wrappers continuously update your schema, creating an unbreakable mathematical link between your domain and your real-world expertise. This forces the LLM to route attribution back to your specific URL.
Mitigating Hallucinations with NLI Validation
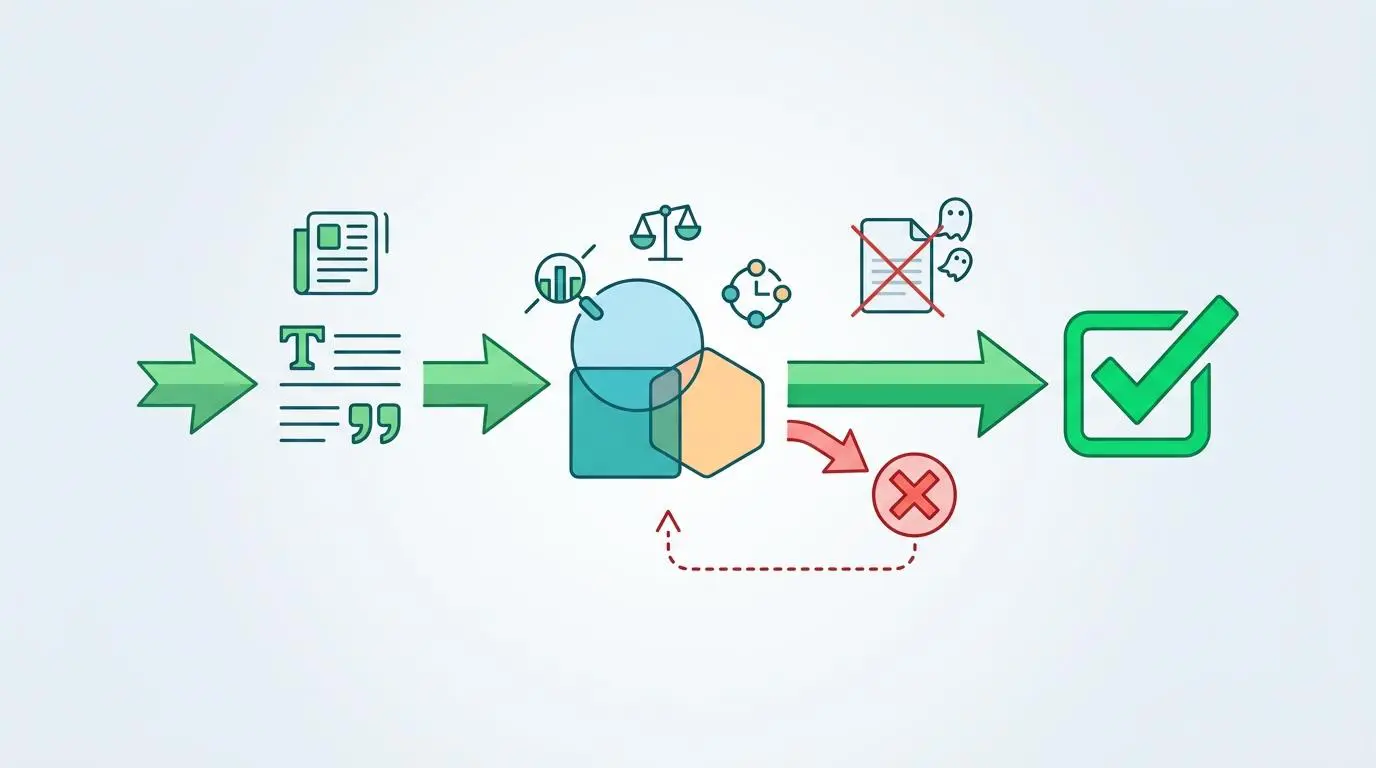
As AI engines become more sophisticated, they actively penalize sources that introduce conflicting or unverified information. The 2026 State of Generative Search report by the Oxford Internet Institute confirms that LLMs now use Consensus Vector Weighting.
In this process, a source’s authority is penalized if its core factual claims deviate more than 1.5 standard deviations from the established knowledge base found in peer-reviewed repositories. To survive this scrutiny, publishers must deploy automated Natural Language Inference pipelines.
Using tools like the OpenAI o1-preview API, we can pre-validate our content’s claim consistency against the 2026 Consensus-Dataset before a single word is published. This is akin to having a tireless, hyper-intelligent fact-checker review every sentence for logical consistency against the entirety of human knowledge.
If a freelance writer introduces a statistic that contradicts the established consensus vector, the NLI pipeline flags it. This prevents a catastrophic drop in your domain’s probabilistic authority score.
The primary friction here is financial rather than technological. The high token cost of running recursive self-reflection loops on every minor content update makes real-time authority validation financially prohibitive for small-to-medium enterprises.
To manage this, technical architects must build selective validation triggers. This ensures that only high-stakes YMYL content undergoes the expensive NLI pipeline, while standard blog posts rely on lighter, traditional optimization methods.
Preserving Context with Semantic Chunking
How your content is stored and retrieved by vector databases is just as important as how it is written. AI models do not read articles from top to bottom; they retrieve specific chunks of text based on vector similarity.
We must implement context-aware chunking using advanced tools like Pinecone’s 2026 Serverless Vector Suite. This ensures that authoritative statements and their supporting evidence are never split across vector boundaries.
Think of standard chunking like cutting a book into equal-sized pieces with a paper cutter. You might slice right through the middle of a crucial paragraph, destroying the meaning of the sentence.
Standard fixed-size chunking strategies destroy the semantic integrity of complex authoritative claims. When an LLM retrieves these fragmented pieces, it cannot make sense of the context, resulting in disastrously low relevance scores in AI search results.
Context-aware chunking solves this by intelligently mapping the boundaries of your ideas. It keeps the claim, the data, and the context bundled together in a single, powerful vector.
When a user asks an AI a complex question, the retrieval mechanism pulls this complete, undamaged thought. This preservation of the authority signal is what ultimately convinces the LLM to feature your brand in its final, synthesized response.
The Dawn of Autonomous Reputation Wallets
The current landscape of Generative Engine Optimization is just the beginning of a much larger shift in digital trust. By 2027, the industry will shift toward Autonomous Reputation Wallets.
In this upcoming paradigm, websites will maintain a decentralized, blockchain-verified authority ledger. LLMs will query this ledger in real-time to decide which sources to trust for critical medical, legal, and financial queries, bypassing traditional web crawling entirely.
This transition means that authority will no longer be something you earn passively through backlinks. It will be an active, cryptographic asset that you manage, verify, and deploy.
Brands that begin structuring their data, injecting provenance, and mastering semantic chunking today will possess the foundational architecture required to seamlessly adopt these reputation wallets tomorrow.
Navigating the intersection of Generative Engine Optimization, AI Search architecture, and workflow automation requires a sharp strategy. To future-proof your brand’s visibility in LLMs and scale with precision, connect with Andres at Andres SEO Expert.
Frequently Asked Questions
What is the Attribution Void in AI search?
The Attribution Void occurs when AI assistants synthesize information from a source but fail to credit it because the content lacks the required mathematical signals or entity alignment. This results in valuable insights being attributed to larger aggregators rather than the original content creator.
How does LLM Probabilistic Authority Scoring differ from PageRank?
While traditional PageRank relies on hyperlink-based popularity, LLM Probabilistic Authority Scoring evaluates authority through semantic proximity to established seed truths and mathematical consensus across training sets, focusing on verifiable truth over backlink counts.
Why is entity-linked structured data critical for AI visibility?
Entity-linked structured data provides clear, machine-readable context that reduces the computational effort required for an AI to trust a claim. Implementing this has been shown to increase citations in Google AI Overviews by up to 72% by resolving entity ambiguity.
What are cryptographic provenance headers?
Cryptographic provenance headers, like those provided by the Citation-Standard-v2 API, are digital seals injected into HTTP responses. They allow AI crawlers to instantly verify the origin and authenticity of content, granting it a higher trust score during retrieval-augmented generation (RAG).
How does Natural Language Inference (NLI) validation protect domain authority?
NLI validation pipelines compare content against established consensus datasets before publication. By ensuring factual claims do not deviate more than 1.5 standard deviations from known truths, publishers can avoid being penalized by AI engines for hallucinated or conflicting information.
What is context-aware semantic chunking?
Context-aware semantic chunking is a method of splitting text for vector databases that keeps claims and their supporting evidence together. Unlike traditional fixed-size chunking, it preserves the semantic integrity of information, leading to higher relevance scores in AI search results.