Executive Summary
- Redundancy Architecture: High Availability (HA) eliminates single points of failure by deploying redundant web servers, database clusters, and load balancers.
- Automated Failover: HA systems utilize health checks and automated failover protocols to redirect traffic from degraded nodes to healthy instances without manual intervention.
- Stateless Configuration: Achieving true HA in WordPress requires a stateless application tier where media, sessions, and databases are decoupled from the local server filesystem.
What is High Availability?
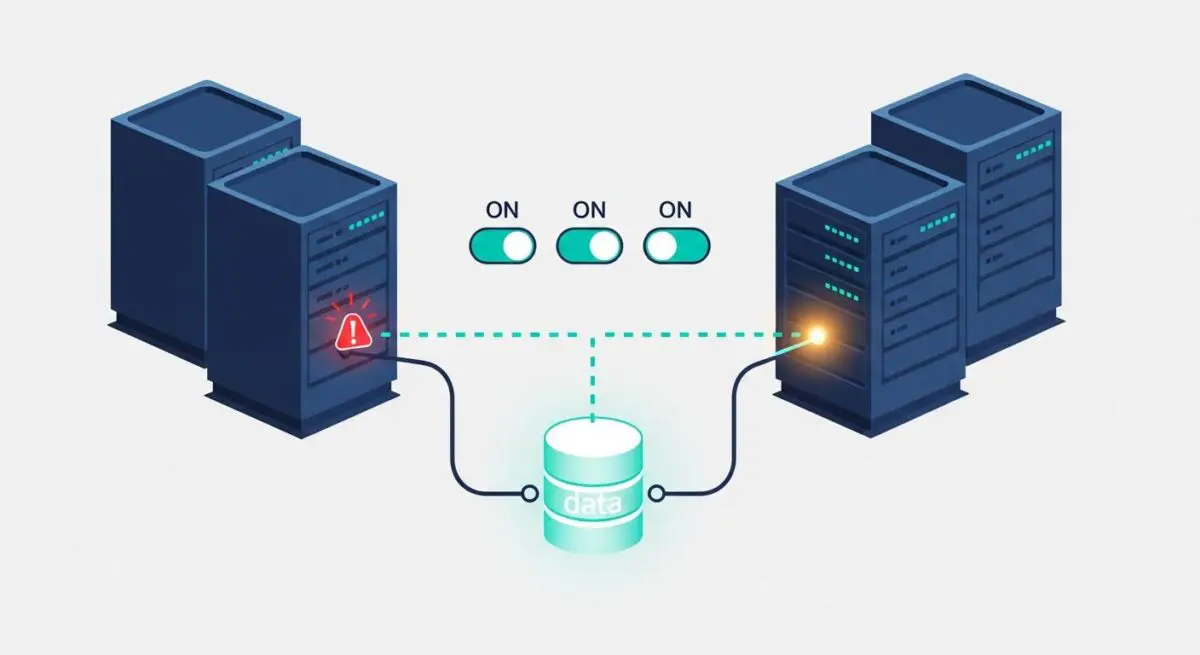
High Availability (HA) refers to a system design approach and associated implementation that ensures a prearranged level of operational performance, usually uptime, for a higher than normal period. In the context of WordPress enterprise architecture, HA is the engineering practice of ensuring that the CMS remains accessible even if one or more components of the hosting infrastructure fail. This is achieved by eliminating Single Points of Failure (SPOF) through redundancy. A standard single-server WordPress setup is inherently fragile; if the hardware, the operating system, or the MySQL process fails, the entire site goes offline. An HA architecture, conversely, distributes the workload across multiple nodes, ensuring that the failure of a single server does not result in service interruption.
Technically, High Availability is measured in percentages, often aiming for the “five nines” (99.999% uptime), which translates to less than five minutes of downtime per year. To achieve this in a WordPress environment, the architecture must be decomposed into several layers: the load balancing layer, the application (web) layer, the data (database) layer, and the storage layer. Each layer must be redundant. For instance, instead of one web server, an HA setup uses a cluster of two or more servers synchronized in real-time. Instead of a single database, it utilizes a primary-replica or multi-primary cluster (such as MariaDB Galera or AWS Aurora) that ensures data integrity and availability across different physical locations or availability zones.
The Real-World Analogy
To understand High Availability, consider the electrical system of a modern surgical hospital. A standard house relies on a single power line from the grid; if a transformer blows, the lights go out. A hospital, however, operates on an HA model. It has multiple independent power feeds from the city grid. If the primary feed fails, an automated switch transfers the load to a secondary feed. If the entire city grid goes dark, massive on-site diesel generators automatically kick in within seconds. Furthermore, critical equipment like life support machines have their own internal batteries (Uninterruptible Power Supplies). The patient on the operating table—much like a user on a high-traffic WordPress site—never experiences a loss of service because the system was designed to expect and survive individual component failures.
How High Availability Impacts Server Performance & Speed Engineering?
High Availability significantly alters the performance profile of a WordPress site. By utilizing a Load Balancer (such as Nginx, HAProxy, or a cloud-native solution like AWS ELB), incoming traffic is distributed across multiple web nodes. This horizontal scaling prevents any single CPU or RAM module from becoming a bottleneck, which directly improves the Time to First Byte (TTFB) during high-traffic events. When one node is under heavy load, the load balancer intelligently routes new requests to a less-burdened node, maintaining consistent response times.
However, HA also introduces technical challenges for speed engineering, specifically regarding data synchronization and latency. In a distributed environment, the database is often located on a separate network tier. If the database cluster is geographically dispersed to ensure disaster recovery, the physical distance can introduce “replication lag.” Speed engineers must mitigate this by implementing robust object caching layers, such as Redis or Memcached, which store frequently accessed database queries in memory. This reduces the need for the web nodes to communicate with the database cluster for every request, effectively neutralizing the latency overhead of the HA architecture. Furthermore, using a Content Delivery Network (CDN) in front of an HA origin ensures that static assets are served from the edge, further reducing the load on the high-availability cluster.
Best Practices & Implementation
- Decouple the Filesystem: WordPress must be made “stateless.” This means moving the /wp-content/uploads/ directory to a shared object storage solution like Amazon S3 or a distributed filesystem like GlusterFS. This ensures that when a user uploads an image, it is available to all web nodes simultaneously.
- Implement Distributed Object Caching: Use Redis or Memcached as a centralized object cache. This prevents “cache fragmentation” where different web nodes have different versions of the site’s data, ensuring a consistent and fast experience across the entire cluster.
- Database Clustering with Failover: Utilize a managed database service or a self-hosted Galera Cluster. Ensure that the WordPress configuration (wp-config.php) is aware of the cluster or uses a database proxy (like MaxScale or ProxySQL) to handle read/write splitting and automated failover.
- Health Checks and Auto-Scaling: Configure the load balancer to perform frequent health checks (e.g., every 5 seconds). If a node returns a 5xx error or fails to respond, the load balancer should automatically drop it from the pool and, in cloud environments, trigger an auto-scaling group to spin up a fresh, healthy instance.
- Centralized Session Management: Store PHP session data in Redis rather than on the local disk. This allows a user to stay logged in even if the load balancer moves their subsequent request to a different web node.
Common Mistakes to Avoid
One of the most frequent errors is maintaining a “Single Point of Failure” within an otherwise redundant system. For example, an agency might deploy multiple web nodes but keep the database on a single standalone server. If that database server fails, the entire HA stack collapses. Another common mistake is failing to account for “Split-Brain” scenarios in database clusters, where two nodes disagree on the state of the data, leading to corruption. Finally, many organizations neglect to test their failover procedures. An HA system is only theoretical until a controlled “chaos engineering” test proves that the system can actually survive a node failure without dropping user sessions or losing data.
Conclusion
High Availability is the cornerstone of enterprise WordPress architecture, shifting the focus from simple hosting to resilient infrastructure engineering. By eliminating single points of failure and automating recovery, brands can ensure their digital presence remains performant and accessible under any conditions.