Key Points
- Conflict Identification: The error occurs when an XML sitemap submits a URL for indexing while HTML meta tags or HTTP headers simultaneously apply a ‘noindex’ directive.
- Resolution Protocol: Resolving the conflict requires auditing X-Robots-Tags, synchronizing SEO plugin settings, and purging stale database transients via WP-CLI.
- Automated Prevention: Preventing recurrence involves implementing CI/CD pipeline checks with headless crawlers and monitoring server logs for 200 OK/noindex pairings.
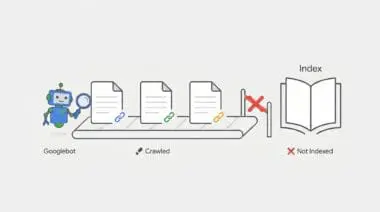
What is the ‘Submitted URL marked ‘noindex” Error?
This technical conflict arises when a URL is explicitly submitted via an XML sitemap—a signal of high priority—while simultaneously carrying a ‘noindex’ directive via HTML meta tags or HTTP headers. This contradiction forces Googlebot to process the URL, consuming Crawl Budget, only to discard the indexing attempt, which degrades the site’s overall crawl efficiency and authority signals. In the context of GEO (Generative Engine Optimization), this inconsistency creates ‘data noise,’ where generative engines may fail to attribute or retrieve content because the site’s structural signals (sitemap) and page-level instructions (robots directives) are in direct opposition, leading to potential exclusion from RAG (Retrieval-Augmented Generation) pipelines.
Symptom Validation
Identifying this issue begins within the Google Search Console ‘Page indexing’ report, which explicitly flags the ‘Submitted URL marked noindex’ status. However, deeper validation requires analyzing raw server logs. In these logs, you will observe Googlebot requesting specific URLs and receiving a 200 OK response code. Despite the successful load, the response body contains a meta robots tag set to noindex, or the HTTP response header includes an X-Robots-Tag directive. This confirms the crawler is successfully accessing the page but is being instructed to drop it from the index immediately after.
Potential Causes & Ecosystem Conflicts
At its core, this error is a symptom of desynchronization between your site’s routing logic, its SEO plugin configuration, and the server’s caching layers. When the system generating the XML sitemap falls out of sync with the system rendering the page headers or HTML, contradictory signals are broadcast to search engines.
Mapping Conflicts in the AI Search Ecosystem
SEO Plugin Desynchronization
Technical: A post or category is set to ‘noindex’ within the application logic, but the sitemap generation engine fails to exclude the entry due to a race condition or manual override in the plugin’s exclusion list.
WordPress Context: Common in RankMath or Yoast when a user sets a post to ‘noindex’ via the meta box, but the plugin’s sitemap cache does not immediately refresh, leaving the URL in the generated XML file.
Stale Database Transients
Technical: WordPress stores sitemap fragments in the wp_options table as transients to reduce server load. If these are not flushed after changing a page’s robots status, the old sitemap persists.
WordPress Context: Occurs when object caching (Redis/Memcached) or WP-Cron failures prevent the ‘delete_transient’ function from clearing the ‘wpseo_sitemap’ or ‘rank_math_sitemap’ entries.
Edge-Level Header Injection
Technical: A Cloudflare Worker or NGINX ‘add_header’ directive is applying X-Robots-Tag: noindex to a URI pattern that is still being dynamically generated into the XML sitemap by the application layer.
WordPress Context: Often happens when developers use NGINX location blocks to noindex staging-like URLs (e.g., /temp-*) that are accidentally included in the production sitemap.
In a typical WordPress environment, SEO plugins handle both page-level meta tags and sitemap generation. However, race conditions or manual overrides can cause a post to be marked noindex in the database while remaining in the sitemap cache. Furthermore, WordPress relies heavily on the database to store sitemap fragments as transients. If object caching mechanisms fail to flush these transients upon a status change, the stale sitemap persists. Beyond the application layer, edge-level configurations introduce another layer of complexity. Cloudflare Workers or NGINX location blocks might inject a noindex header to specific URI patterns that the application layer is still actively pushing into the production XML sitemap.
Engineering Resolution Roadmap
Resolving this conflict requires a systematic approach to align your sitemap outputs with your page-level directives. The goal is to either remove the noindex tag if the page should be indexed, or remove the URL from the sitemap if the page is intentionally hidden.
Technical Transformation Blueprint
Audit Robots Directive Source
Run ‘curl -I -L -A “Googlebot” [URL]’ to check for X-Robots-Tag in the header. If absent, inspect the HTML source for <meta name=’robots’ content=’noindex’>.
Synchronize Plugin Settings
Navigate to the SEO plugin’s Sitemap Settings and ensure the specific Post Type or Taxonomy is either indexed or explicitly excluded from the sitemap.
Purge Sitemap Cache and Transients
Use WP-CLI command ‘wp transient delete –all’ and flush any object cache (Redis/Memcached) to force a fresh sitemap generation.
Trigger GSC Validation
Submit the updated sitemap URL in GSC and click ‘Validate Fix’ on the ‘Submitted URL marked noindex’ report to initiate a recrawl.
The first step is to audit the exact source of the robots directive. By running a cURL command mimicking Googlebot, you can determine if the instruction is originating from an HTTP header or the HTML document itself. Once identified, you must synchronize your SEO plugin settings. Ensure that any post type, taxonomy, or individual URL intended to be hidden is explicitly excluded from the sitemap generation rules. Next, to clear out any lingering data, purge the sitemap cache and database transients. Utilizing WP-CLI to delete transients, alongside flushing Redis or Memcached, forces the application to rebuild the XML sitemap from the current database state. Finally, submit the refreshed sitemap to Google Search Console and trigger a validation to initiate a recrawl.
The Code Fix
If you are using Yoast SEO and want to programmatically guarantee that no ‘noindex’ URLs bleed into your XML sitemap, inject the following PHP snippet into your child theme‘s functions.php file or a custom functionality plugin. This script hooks into the sitemap generation engine, queries the database for any post containing the noindex meta value, and dynamically strips those IDs from the final XML output, permanently resolving the protocol conflict at the server level.
add_filter( 'wpseo_exclude_from_sitemap_by_post_ids', function( $excluded_ids ) { $noindex_posts = get_posts( array( 'meta_key' => '_yoast_wpseo_meta-robots-noindex', 'meta_value' => '1', 'fields' => 'ids', 'post_type' => 'any', 'posts_per_page' => -1 ) ); return array_merge( $excluded_ids, $noindex_posts ); } );Validation Protocol & Edge Cases
Before relying on Google Search Console to confirm the fix, it is critical to validate the resolution locally to ensure the contradictory signals have been eliminated.
Validation Protocol
- Run ‘curl -I -L -A “Googlebot” https://example.com/page’ to verify no ‘noindex’ header exists.
- Use the Google Search Console ‘URL Inspection Tool’ and click ‘Live Test’ to confirm Google sees the ‘index’ directive.
- Check the ‘Sitemaps’ report in GSC to ensure the ‘Last Read’ date is current and the URL count has decreased.
Even with strict adherence to the resolution roadmap, edge cases can prevent immediate success. A common scenario involves a Varnish or NGINX FastCGI cache layer configured with a long time-to-live specifically for XML files. In this situation, the server continues to serve a static, outdated version of the sitemap to Googlebot, even after the WordPress database and SEO plugins have been correctly updated. Consequently, the sitemap appears correct for logged-in administrators but remains broken for external crawlers. To resolve this, you must manually purge the edge cache or server-side cache specifically for the sitemap URIs.
How to Prevent Future Issues & Best Practices
To prevent this desynchronization from recurring, engineering teams should implement a continuous integration pipeline check using a headless crawler, such as Puppeteer, to verify that no URL present in the XML sitemap returns a noindex directive. Additionally, configuring server-side log monitoring to trigger alerts when Googlebot encounters a 200 status code paired with a noindex header provides an early warning system before Search Console flags the error.
As a best practice, maintain a strict separation of concerns regarding indexing directives. Avoid mixing edge-level header injections with application-level SEO plugin settings. Establish a unified protocol where all indexing rules are managed centrally within the content management system, ensuring that the sitemap generation engine always has access to the single source of truth regarding a URL indexability status.
Think of your XML sitemap as a VIP guest list for an exclusive event, and the noindex tag as a bouncer at the front door. The submitted URL marked noindex error is the equivalent of handing Googlebot a VIP ticket, only for the bouncer to turn them away upon arrival. Not only does this waste the guest’s time, but it also damages your credibility as the event organizer.
Decoding the Submitted URL Marked ‘noindex’: The Ghost in the Generative Machine
In the evolving landscape of Generative Engine Optimization, technical debt within your site architecture creates semantic noise that actively confuses generative response engines like ChatGPT, Gemini, Perplexity, and Google AI Overviews. When an AI model attempts to synthesize information from a domain, it relies heavily on structural signals to determine content priority and validity. A submitted URL marked noindex error presents a logical paradox to these Large Language Models. The sitemap insists the data is critical, while the page-level directives demand it be ignored. This data inconsistency prevents generative models from confidently extracting and attributing your content, ultimately leading to your domain being bypassed in Retrieval-Augmented Generation pipelines in favor of technically sound competitors.
Surviving and thriving in the generative ecosystem requires an uncompromising commitment to a clean stack. Generative engines do not have the patience to untangle contradictory indexing signals; they simply move on. To maintain entity integrity and ensure real-time discoverability, modern SEO must transition from reactive troubleshooting to proactive, autonomous monitoring. Leveraging automation platforms like Zapier, N8N, or Make.com to build autonomous pipelines is the inevitable future of technical SEO. By integrating server log analysis with real-time crawler validation, you can instantly detect and resolve sitemap conflicts before they degrade your AI-search visibility, ensuring your technical foundation remains an asset rather than a liability.
Conclusion & Next Steps
Resolving the submitted URL marked noindex error is a critical step in reclaiming your crawl budget and ensuring your technical signals align perfectly with your indexing strategy. By auditing your directives, synchronizing your plugins, and clearing stale caches, you eliminate the friction that slows down search engine crawlers and generative AI models alike.
Navigating the intersection of generative search and operational efficiency requires more than just tools—it requires a roadmap. If you’re ready to evolve your strategy through specialized SEO, GEO, Advanced Hosting Environments, or AI-driven automation, connect with Andres at Andres SEO Expert. Let’s build a future-proof foundation for your business together.